2026年のベストAIボイスクローンツール:ElevenLabs対F5-TTS対OpenVoice
このトピックに関するほとんどの投稿は、10以上のツールをランク付けしたリストを提供しますが、それは役に立ちません。3つのツールがほぼすべての実際のユースケースをカバーしており、それらの違いは明確です。このガイドでは、3つのツールを選び、それぞれが実際に得意とすることを示し、ボイスクローンツールが全く必要ない共通のユースケース(自分の声で他の言語に動画を吹き替える)を示します。
誰のためのものか
ナレーション、オーディオブック、またはカスタムTTS機能のために自分の声をクローンするツールを選ぶクリエイター。SaaSにボイスクローン機能を出荷する製品チーム。オープンソースと商業の比較を考慮しているローカリゼーションチーム。自分の声でYouTube動画を他の言語にローカライズしようとしている場合は、ボイスクローンツールが必要ない場合はどうするか?のコールアウトに進んでください — それは異なる問題であり、異なるツールです。
クイックバイヤーズガイド — 実際に重要なこと
重要な4つの次元があります; 残りはマーケティングコピーです。
1. 同意と合法性(最初に重要な唯一のルール)。 他人の声を明示的な書面による同意なしにクローンすることは法的な災害です — GDPRはEUで声を生体データとして扱います; FCCの2024年の裁定により、米国のロボコールでの使用が違法になりました。DescriptやResembleのようなツールは、クローン作成前に同意チェックを強制します。F5-TTSのようなツールはポリシーをあなたに委ねます。適切に選択してください。
2. 価格モデル。 文字ごとの請求(ElevenLabs、AWS Polly、Azure)は線形にスケールします — 低ボリュームには適していますが、大規模には痛みを伴います。サブスクリプションプランは支出に上限を設けます。オープンソースの自己ホスト型(F5-TTS、OpenVoice)は、ドルをGPUコスト + エンジニアリング時間と交換します。
3. 声の忠実度とサンプルの長さ。 「インスタント」クローンは10-30秒の参照音声が必要で、70-80%の忠実度を提供します。「プロフェッショナル」クローンは30分以上のクリーンなスタジオ音声が必要で、95%以上に達します。使用ケースに合ったティアを選択してください — ポッドキャストのイントロは内部ツールよりも高い忠実度が必要です。
4. 音声がどこにあるか。 一部のベンダーは、アップロードした声をモデルの研究開発に使用するための「永久ライセンス」を自らに付与します。プライバシーポリシーを読みましょう。あなたのインフラから声データを持ち出せない場合は、F5-TTSまたはOpenVoiceを自己ホストしてください。
これらの3つを選んだ理由
ほとんどの「最高の声クローンツール」リストは15件のエントリーがあり、パディングがSEOに役立つからです。私たちは異なります。3つのバケットがほぼすべての実際の使用ケースをカバーします — 商業的な仕上げ、オープンソースの自己ホスト、軽量のオープンソース代替。これらの3つと重複する12のツールを除外しました(Murf、Play.ht、Speechify、Lovo、Listnr、TTSMakerなどは、ElevenLabsと同じ商業的仕上げのバケットに入ります; Fish Audio、Hume、Respeecherは映画/共感的ニッチをターゲットにしています)。長いリストを求める場合、それらはGoogle検索で見つかります。決定を求める場合は、読み続けてください。
比較する価値のある3つのツール
マーケティングコピーを超えて、ボイスクローンの分野は3つのバケットに分かれます:洗練された商業リーダー(ElevenLabs)、オープンソースの作業馬(F5-TTS)、F5-TTSが合わない場合の軽量オープンソースの代替(OpenVoice)。それぞれが異なるリーダーを持っています。あなたの制約に合ったものを選んでください。

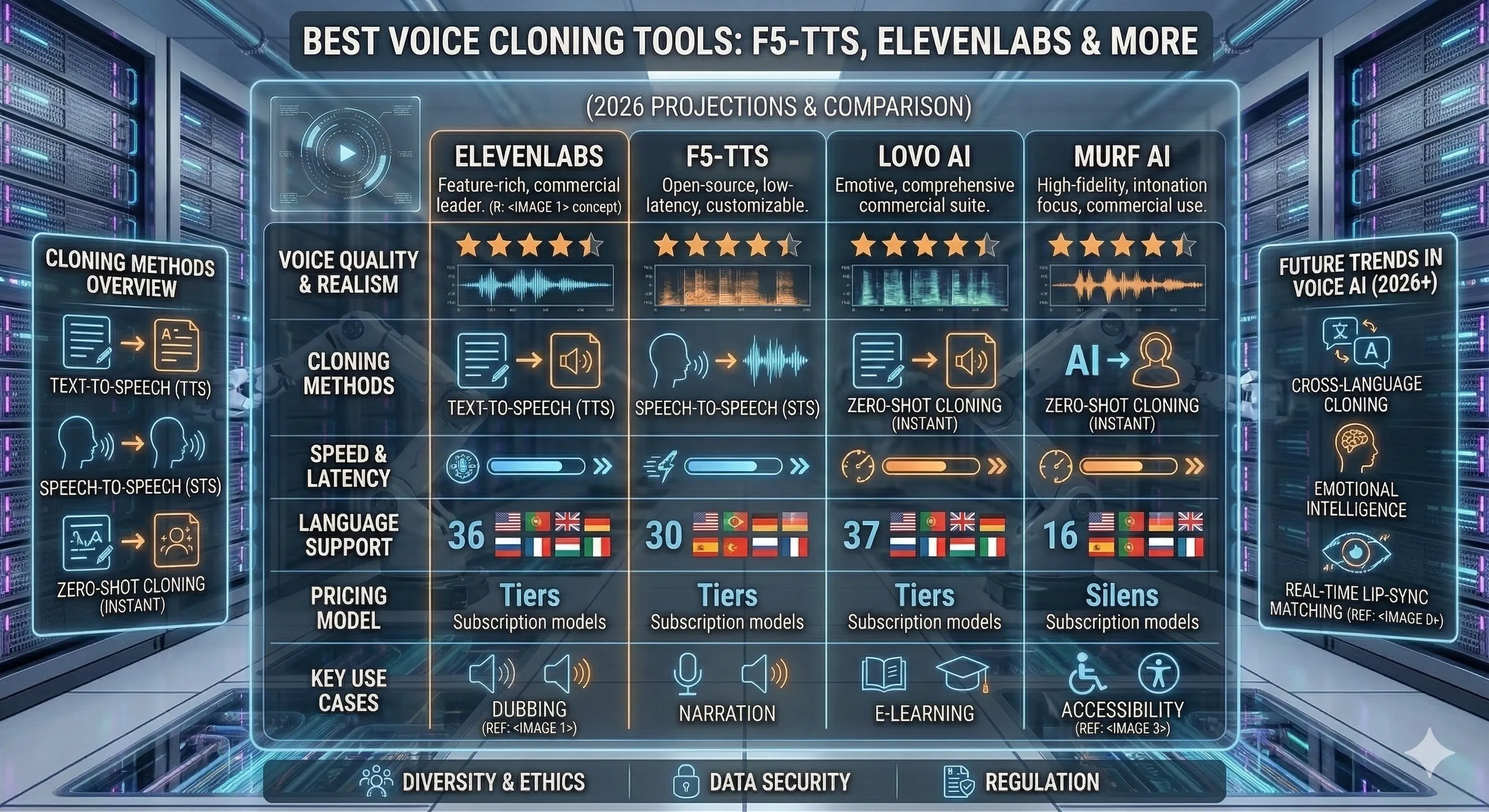
1. ElevenLabs
洗練されたボイスクローンの商業リーダー
- Best for: 製品、オーディオブック、IVR、メディアのキャラクターボイスのためのカスタムボイス
- Pricing: キャラクターごとの課金 — 無料プランは制限あり;有料プランは約$5/月から
- Languages: 成熟した音声ライブラリを持つ30以上の言語
- Notable limitation: ボイスクローンに関するコンテンツポリシーのゲートがあるクローズドプラットフォーム(カスタムボイスには同意確認が必要);高ボリュームではキャラクターごとのコストがかさむ
エンジニアリングの障害が最も少なく、基本的な忠実度が最も高いボイスクローンツールが必要な場合、そしてベンダーロックインに快適であればElevenLabsを選んでください。APIと音声ライブラリはこのカテゴリで最も成熟しています。ユーザーが自分の声をクローンする製品機能を構築している場合、これは最も抵抗の少ない道です。
2. F5-TTS
オープンソースの作業馬、ゼロショット多言語
- Best for: セルフホスティングのボイスクローン、技術チーム、カスタム推論、バッチ生成
- Pricing: 無料(セルフホスティング) — GPUコストが最低
- Languages: ゼロショット転送の多言語;リソースの少ない言語のためのコミュニティファインチューニング
- Notable limitation: GPUと推論インフラが必要;長いクリップ(>30-45秒)ではプロソディがずれる可能性がある;表現の極端(笑い、叫び)は弱まる
エンジニアリングリソースがあり、スケールでクリップあたりのコストがゼロになる経済を望む場合、またはコンプライアンスのためにデータの居住性/セルフホスティングが必要な場合はF5-TTSを選んでください。このモデルはDiffusion Transformerを使用したフローマッチングを行い、ステップと精度を調整すれば商業出力と競争できます。参照リポジトリ:SWivid/F5-TTS;2025年の論文はOpenReviewにあります。
3. OpenVoice
軽量のオープンソース代替品、MITライセンス
- Best for: シングルクリップクローン、リソースの少ない環境、許可のあるライセンス
- Pricing: 無料(MITライセンス、セルフホスティング)
- Languages: 4つ以上の言語を標準装備; それらの間での声スタイル転送
- Notable limitation: 商業リーダーよりも音声の忠実度が低い; リソースの少ないモデルで、F5-TTSが公開している微調整レバーが少ない
F5-TTSがあなたの制約に合わない場合はOpenVoiceを選択してください — より弱いハードウェアで動作する小型モデル、商業利用のためのより許可のあるライセンス、またはシンプルなAPIが必要です。忠実度のトレードオフは現実ですが、非ヒーローのユースケース(ラフドラフト、内部ツール、アクセシビリティプロトタイプ)には管理可能です。
並列比較
3つのツールにわたる同じ4つの次元。各ツールのボックスを読んだ後に、これを使って呼び出しを三角測量してください。
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | 製品、オーディオブック、IVR、メディアのキャラクターボイスのためのカスタムボイス | セルフホスティングのボイスクローン、技術チーム、カスタム推論、バッチ生成 | シングルクリップクローン、リソースの少ない環境、許可のあるライセンス |
| Pricing | キャラクターごとの課金 — 無料プランは制限あり;有料プランは約$5/月から | 無料(セルフホスティング) — GPUコストが最低 | 無料(MITライセンス、セルフホスティング) |
| Languages | 成熟した音声ライブラリを持つ30以上の言語 | ゼロショット転送の多言語;リソースの少ない言語のためのコミュニティファインチューニング | 4つ以上の言語を標準装備; それらの間での声スタイル転送 |
| Limitation | ボイスクローンに関するコンテンツポリシーのゲートがあるクローズドプラットフォーム(カスタムボイスには同意確認が必要);高ボリュームではキャラクターごとのコストがかさむ | GPUと推論インフラが必要;長いクリップ(>30-45秒)ではプロソディがずれる可能性がある;表現の極端(笑い、叫び)は弱まる | 商業リーダーよりも音声の忠実度が低い; リソースの少ないモデルで、F5-TTSが公開している微調整レバーが少ない |
どのユースケースにどれを選ぶか
- SaaS機能、オーディオブック、またはIVRのためのカスタム音声 → ElevenLabs。成熟しており、洗練されていて、エンジニアリングの表面が低い。
- スケールでの音声クローン、自ホスト → F5-TTS。クリップごとに無料、完全な制御、GPUが最低条件。
- リソースの少ない環境または許可のあるライセンスが必要 → OpenVoice。軽量モデル、MIT。
- 話者の声を保持しながら別の言語に動画をローカライズする → すべての3つをスキップ。次のセクションを読んでください。
音声クローン*ツール*が必要ない場合は?
「最高の音声クローンツール」にたどり着いたほとんどの読者は、実際には1つの特定の問題を解決しようとしています: 別の言語で元の話者のように動画を聞かせる。もしあなたがそうなら、音声クローンツールは必要ありません — 内部で音声クローンを使用するダビングツールが必要です。
Curify Video Dubbingは、ソース動画から元の話者の声をクローンし、音声を翻訳し、ソースのタイミングに合わせて調整し、話者のアイデンティティを保持したままターゲット言語でダビングトラックを提供します。音声クローンは目に見えません — 動画をアップロードし、言語を選択し、ダブを取得します。このパイプラインは、上記で説明したF5-TTSの系譜に基づいて構築されており、調整、リップシンク、字幕生成を処理するので、これらの要素を自分で組み立てる必要はありません。
これが適している場合: YouTube動画、コースモジュール、製品デモ、ウェビナー、チュートリアルのローカライズ。
適していない場合: TTS API、IVR、オーディオブックのナレーション、またはユーザーが自分の声をクローンするSaaS機能のための音声クローン — それらについては、上記のElevenLabsまたはF5-TTSを使用してください。異なるカテゴリ、異なるツール。
声をクローンする前に知っておくべきコンプライアンス
法的助言ではありません — 自分の管轄の弁護士に相談してください。とはいえ、3つの防御可能な実践がどこにでも見られます:
- 同意と権利。 声の所有者から明示的な書面による同意を得ること。参照音声の出所を文書化すること。アメリカの一部の州では、パブリシティの権利は死後も存続します;弁護士がこれを調査できます。
- 開示。 プラットフォームや管轄が要求する場合、合成または意味的に変更された声にラベルを付けること。YouTubeはアップロード中に開示の手段を提供しています — それを使用してください。
- 電話注意。 アメリカのFCCの2024年の宣言的判決により、事前の明示的な同意なしにロボコールでのAI生成音声がTCPAの下で違法となりました。あなたのユースケースが電話に関わる場合、これが障害となります。
よくある質問
2026年にAI音声クローンは合法ですか?
それは管轄区域のパッチワークです。米国: 音声クローンに対する連邦法はありませんが、非同意使用に対して州のパブリシティ権法が適用されます; FCCの2024年の裁定により、ロボコールでのAI音声が違法になります。EU: GDPRは声を生体データとして扱います — 明示的な同意が必要で、モデルのトレーニング使用を開示する必要があります。常に声の所有者から明示的な書面による同意を得て、それを文書化し、プラットフォームが要求する場合は合成コンテンツにラベルを付けてください(YouTube、TikTok)。
声をクローンするのにどれくらいの音声が必要ですか?
ティアによります。インスタントクローン(ElevenLabs Instant、OpenVoice)は10-30秒の参照音声が必要で、70-80%の忠実度を提供します。プロフェッショナルクローン(ElevenLabs Professional、F5-TTSファインチューニング)は30分以上のクリーンなスタジオ音声が必要で、95%以上の忠実度に達します。ポッドキャストのイントロ用に自分の声をクローンする場合、インスタントティアで問題ありません。製品機能を出荷する場合は、プロフェッショナルに進んでください。
個人プロジェクトのために有名人の声をクローンできますか?
いいえ。すべての信頼できるプラットフォーム(ElevenLabs、Resemble、Respeecher)は、利用規約でこれを禁止しています。これはほとんどの米国の州でパブリシティ権法に違反し、多くの管轄区域で著作権に違反します。オープンソースモデルを自己ホストしても、有名人クローンの出力を配布することは法的措置の対象となります。やめてください。
声のクローンとテキスト読み上げ(TTS)の違いは何ですか?
TTSは、既存の声(しばしばキュレーションされたストックボイス)を使用して書かれたテキストを音声に変換します。声のクローンは、参照サンプルからキャプチャされた特定の人の声で音声を生成します。ほとんどの現代のプラットフォーム(ElevenLabs、F5-TTS)は両方を行います — それらはクローンを機能として持つTTSエンジンです。「声のクローンツール」は通常「声をクローンするために使用しているTTSエンジン」を意味します。
音声から音声(STS)とは何ですか?
異なるメカニズム: あなたは自分自身がセリフを演じるのを録音し(トーン、ペーシング、感情を含む)、ツールはあなたのパフォーマンスを異なるターゲット声にマッピングします。元の俳優の感情的な表現を引き継ぐダビングに役立ちます。Respeecherはこれに特化しており、ElevenLabsや他のプラットフォームも機能として持っています。ストレートな声のクローンとは異なる問題です。
自分の声でYouTube動画をダビングしたいだけです。どのツール?
上記の3つのツールだけでは不十分です — パイプラインを構築する必要があります。必要なものは: (1) 元の音声を抽出する, (2) スピーカーの声をクローンする, (3) スクリプトを翻訳する, (4) クローンされた声でダビング音声を生成する, (5) ソース動画のタイミングに合わせる, (6) オプションでリップシンクする。Curify Video Dubbingはすべてのステップをエンドツーエンドで行います。声のクローンは内部的なもので、動画をアップロードし、言語を選択し、ダブを取得します。「声のクローンツール」とは異なるカテゴリです。
短いバージョン
3つのツール、1つの決定:ElevenLabsは製品を出荷する場合に最適で、洗練された低エンジニアリング表面を提供します;F5-TTSはGPUを持っていて、スケールでクリップあたりのコストがゼロになる場合に最適です;OpenVoiceは許可のあるライセンスで軽量モデルが必要な場合に最適です。そして、あなたの本当の問題が自分の声で動画を吹き替えることであれば、Curifyを試してみてください — ボイスクローンは自動で行われ、上記の3つを学ぶ必要はありません。
Take the next step
Putting what you read into practice.

