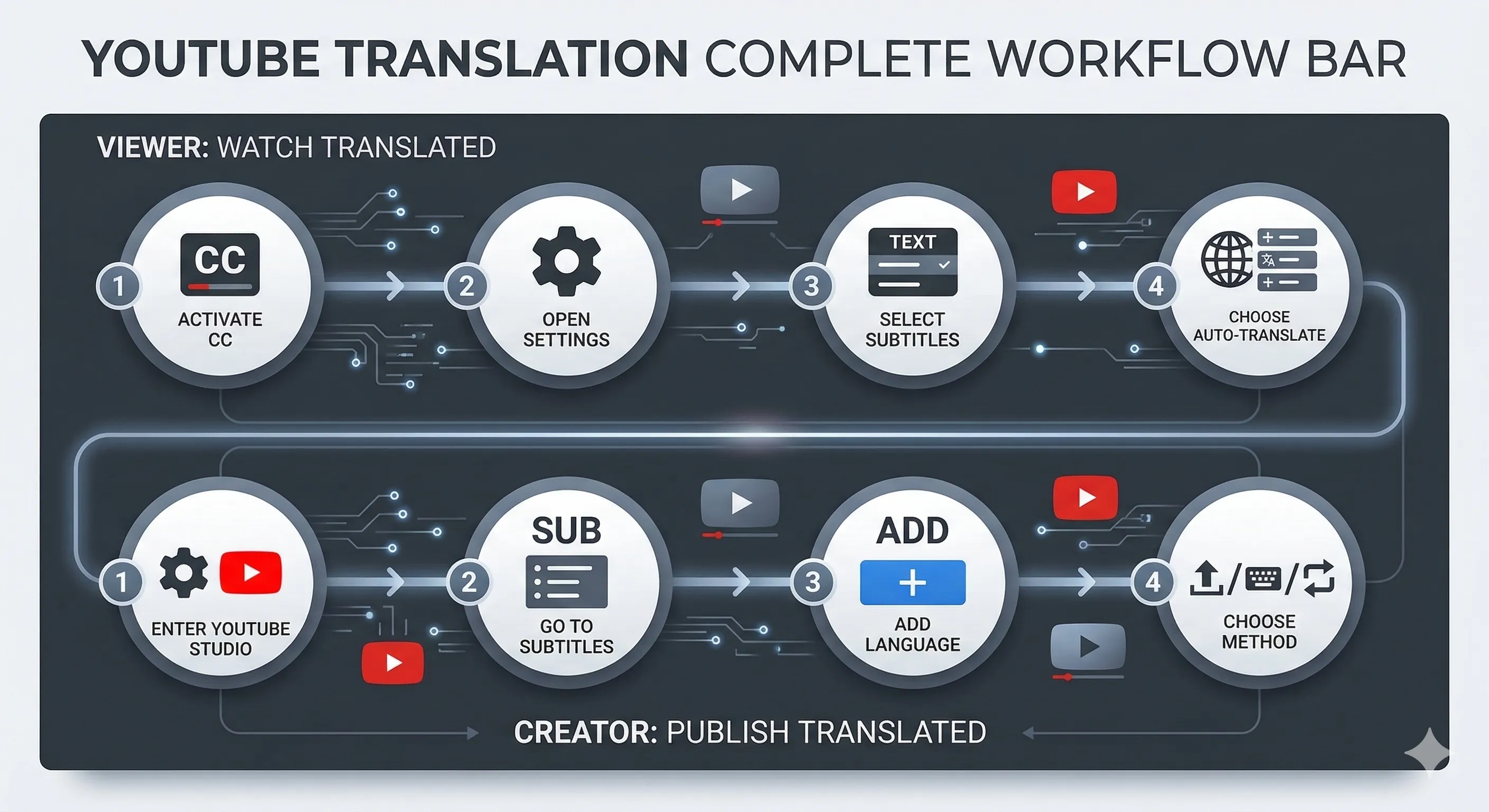
AIビデオ転写パイプラインの内部:ASR、アライメント、スピーカーダイアリゼーション
ほとんどの文字起こしツールは音声からテキストへの変換で止まります。この詳細な解説では、Curifyの完全な文字起こしパイプラインを紹介します:音声がバックグラウンドミュージックから分離される方法、WhisperXがクリーントラックに対してどのように動作するか、スピーカーダイアライゼーションが重なり合う声をどのように分割するか、強制アラインメントがトランスクリプトに単語レベルのタイムスタンプを戻す方法、そして出力が[/tools/video-transcript-generator](/tools/video-transcript-generator)で下流の字幕、ダビング、翻訳ツールを駆動できるようにする方法です。SRTをダウンロードするだけでなく、文字起こしをより大きなパイプラインに統合したい場合、これはほとんどのブログ投稿がスキップするレイヤーです。
エンドツーエンドの動画転写パイプライン
生の動画コンテンツを構造化された時間同期テキストに変換する生産グレードの動画転写パイプラインは、複数の高度な処理ステージを通じて実現されます。完全なワークフロー:動画 → 音声抽出 → セグメンテーション → ASR(自動音声認識) → アラインメント → 話者識別 → ポストプロセッシング。
各ステージは特定の技術的課題に対処します:音声抽出は音声トラックを分離し、セグメンテーションは長い音声を管理可能なチャンクに分割し、ASRは音声をテキストに変換し、アラインメントは単語レベルのタイムスタンプを提供し、識別は誰がいつ話したかを特定し、ポストプロセッシングは最終出力をクリーンアップしフォーマットします。
Curifyのパイプラインのような現代のシステムは、Conv-TasNetを音声分離に、WhisperXを音声認識に、話者識別のための高度なクラスタリングアルゴリズムを組み合わせることで、困難な条件でも95%以上の精度を達成します。この技術的深掘りでは、各コンポーネントとその統合戦略を探ります。
転写における技術アーキテクチャの重要性
精度と速度のトレードオフ:大きなモデルはより良い精度を提供しますが、処理時間と計算コストが増加します。生産システムは、ユースケースの要件に基づいてこれらの要素のバランスを取る必要があります。
スケーラビリティの課題:リアルタイム転写にはストリーミング処理と低遅延推論が必要ですが、バッチ処理はスループットとコスト効率を最適化できます。
多言語の複雑さ:コードスイッチング(文中での言語の混合)やクロスリンガルコンテンツは、言語の境界を越えてコンテキストを維持できる専門的なモデルを必要とします。
生産の信頼性:エンタープライズシステムは、実際のコンテンツで必然的に発生するエッジケースを処理するために、フェイルオーバーメカニズム、品質監視、自動エラー回復が必要です。
コアパイプラインコンポーネント
音声前処理とセグメンテーション
パイプラインは、Conv-TasNetを使用した高度な音声前処理から始まります。このステージでは、背景音楽、環境音、その他の音声ソースから人間の音声を分離します。
技術的実装:
# Conv-TasNetを使用した音声分離
import torch
import torchaudio
from conv_tasnet import ConvTasNet
# ソース分離モデルの初期化
separator = ConvTasNet(
n_bases=512, # 基底関数の数
kernel_size=16, # 畳み込みカーネルサイズ
stride=8, # 時間的畳み込みのストライド
n_layers=8, # 畳み込み層の数
n_src=2 # 分離するソースの数
)
# 16kHzで音声波形を処理
audio_tensor, sample_rate = torchaudio.load('input_video.wav')
if sample_rate != 16000:
resampler = torchaudio.transforms.Resample(sample_rate, 16000)
audio_tensor = resampler(audio_tensor)
# ソースを分離
with torch.no_grad():
separated_sources = separator(audio_tensor)
speech_source = separated_sources[0] # 主な音声を抽出
Conv-TasNetアーキテクチャは、畳み込みエンコーディング-デコーディング構造を使用して、生の波形から音声ソースを直接分離し、スペクトログラムベースのアプローチに関連する情報損失を回避します。
WhisperXによるASR(音声からテキスト)
クリーンな音声は、転写精度と速度に最適化されたOpenAIのWhisperモデルの強化版であるWhisperXに供給されます。システムは、話者の識別による複数の話者、方言、アクセントを処理し、音声を話者ごとに自動的にセグメント化します。
技術的実装:
# WhisperXを使用した高度な音声認識
import whisperx
import torch
from whisperx.utils import get_writer
# 転写用のWhisperXモデルをロード
model = whisperx.load_model("large-v3", device="cuda")
# 単語レベルのタイムスタンプと話者識別を使用して転写を実行
result = model.transcribe(
speech_source,
batch_size=32, # 効率のためにバッチ処理
language="auto", # 言語を自動検出
task="transcribe",
word_timestamps=True, # 単語レベルのタイミングを有効にする
print_progress=True
)
# 強制アラインメントを使用してWhisper出力を整列
model_a, metadata = whisperx.load_align_model(
language_code=result["language"],
device="cuda"
)
result = whisperx.align(
result["segments"],
model_a,
metadata,
speech_source,
device="cuda"
)
# 話者ラベルを割り当てる
diarize_model = whisperx.DiarizationPipeline(
use_auth_token=False,
device="cuda"
)
diarize_segments = diarize_model(speech_source)
result = whisperx.assign_word_speakers(diarize_segments, result)
WhisperXは、最適化された推論、より良い話者識別、強化された単語レベルのタイミング精度を通じて、基本的なWhisperモデルを改善します。強制アラインメントステップは、音声と転写の間の正確な同期を保証します。
強制アラインメントと単語レベルのタイムスタンプ
強制アラインメントは、高品質の字幕、動画の同期、下流の言語処理に不可欠な正確な単語レベルのタイムスタンプを提供します。このステージでは、専用の音響モデルが音声信号とASRシステムからの初期転写を取り込み、粗いASR出力よりもはるかに細かい粒度で整列させます。各文やセグメントの開始と終了のタイミングだけでなく、システムは各単語の正確な開始と終了のタイミングを推定します。これは、音響証拠と転写を考慮して、各単語の最も可能性の高いタイミングを計算するために、隠れマルコフモデルやニューラル音響エンコーダなどの確率的シーケンスモデルを使用します。結果は、各単語に開始時間、終了時間、信頼度スコアが注釈され、セグメントには詳細なタイミングメタデータが付加されたリッチな構造です。これらの正確なタイムスタンプは、フレーム精度の字幕レンダリングを可能にし、編集者が動画タイムラインの特定のスピーチ部分に直接ジャンプできるようにし、機械翻訳、吹き替え、リップシンク分析、大規模メディアライブラリ全体でのコンテンツベースの検索などの後続のタスクのための信頼できる時間的バックボーンを作成します。
話者識別の実装
話者識別は、音声または動画ファイル全体で「誰がいつ話したか」という質問に答える役割を果たし、生の転写を構造化された話者認識の会話に変換します。システムは、単一の支配的な話者を含む可能性のある均質なセグメントに音声を分割し、各セグメントを音色、ピッチパターン、話し方などの特徴をキャプチャするコンパクトな数値表現である話者埋め込みに変換します。これらの埋め込みを使用して、クラスタリングアルゴリズムは、事前に話者の数やその身元を知らなくても、似た音のセグメントを一貫した話者のアイデンティティにグループ化します。高度な識別パイプラインは、話者の数を適応的に推定し、話者が重なる境界を洗練し、長い録音全体で同じ話者IDが割り当てられるようにラベルをスムーズにします。結果として得られる識別された転写は、各セグメント、しばしば各単語に安定した話者ラベルを関連付け、会議の議事録、話者ごとの要約、コールセンター分析、パーソナライズされたコンテンツ推奨、各瞬間にどのキャラクターまたは参加者が話しているかを示す明確な字幕などのアプリケーションを可能にします。
ポストプロセッシングと品質保証
ポストプロセッシングと品質保証のステージは、生のモデル出力をエンドユーザーや下流システムに適した洗練された生産準備完了の転写に変換します。ポストプロセッシングは通常、ケースの修正、数字の拡張または標準化、略語の処理、句読点の復元などの正規化ステップから始まります。これにより、テキストはトークンの平坦なシーケンスではなく、自然な散文のように読みやすくなります。タイムスタンプは標準化された字幕タイムコードにフォーマットされ、転写は長さ、期間、言語的境界に応じて読みやすい字幕ユニットまたは段落にセグメント化されます。品質保証は、このクリーンな転写の上に検証レイヤーを追加します:単語レベルの信頼度スコアをセグメントレベルのメトリックに集約し、異常に低い信頼度のパッセージ、急なタイミングギャップ、または疑わしい繰り返しを検出し、人間のレビューや自動再処理のためにフラグを立てます。追加のチェックは、スタイルガイドを強制し、適切な場合には不流暢さやフィラー単語を削除し、ファイル全体で話者ラベルが一貫していることを保証します。これらのポストプロセッシングとQAステップは、最終出力が言われたことを反映するだけでなく、専門的な転写、ローカリゼーション、アクセシビリティワークフローに必要な精度、読みやすさ、フォーマット基準を満たすことを保証します。
技術的課題と解決策
重複するスピーチ:複数の話者が同時に話すことはASRの課題を引き起こします。解決策には、音声ソースの分離、複数話者モデル、および高度な識別アルゴリズムが含まれます。
多言語の切り替え:言語間のコードスイッチングは、同時に複数の言語を処理できるモデルを必要とします。高度なシステムは、言語識別と専門的な多言語モデルを使用します。
ノイズの多い環境:バックグラウンド音楽、環境音、音質の低下は転写精度を低下させます。音声前処理とソース分離技術がこれらの問題を軽減します。
レイテンシと精度:リアルタイムアプリケーションは低レイテンシを必要としますが、精度を犠牲にする場合があります。生産システムは、ユースケースに基づいてこれらの競合する要件のバランスを取る必要があります。
生産システム設計
バッチ処理とストリーミング処理:バッチ処理はコストとスループットを最適化しますが、ストリーミング処理はライブアプリケーションのリアルタイム転写を可能にします。
GPU推論の最適化:モデルの量子化、バッチ処理、テンソル並列化により、計算コストを削減しつつ精度を維持します。
パイプラインオーケストレーション:メッセージキュー(Azure Service Busなど)が処理ステージ間の調整を行い、スケーラブルでフォールトトレラントなワークフローを実現します。
コスト最適化戦略:動的バッチ処理、スポットインスタンス、モデル圧縮により、インフラストラクチャコストを削減しつつサービスレベル契約を維持します。
技術アーキテクチャの比較
| コンポーネント | 基本ASR | WhisperX | エンタープライズパイプライン |
|---|---|---|---|
| 音声処理 | シングルチャネル | 基本フィルタリング | Conv-TasNet分離 |
| 音声認識 | HMM/GMM | トランスフォーマー | WhisperX + ファインチューニング |
| 話者識別 | なし | 基本クラスタリング | 高度なクラスタリング + 音声プロファイリング |
| 強制アラインメント | なし | 基本アラインメント | 単語レベルの精密アラインメント |
| 品質保証 | 手動 | 信頼度スコアリング | 自動化 + 人間のレビュー |
| スケーラビリティ | 限定的 | 中程度 | エンタープライズスケール |
| 精度 | 70-85% | 90-95% | 95-98% |
技術的トレードオフ:
- レイテンシと精度:大きなモデルはより良い精度を提供しますが、処理時間が増加します
- 計算コスト:GPUアクセラレーションは生産規模の処理に不可欠です
- モデルサイズ:量子化はメモリ使用量を削減しますが、エッジケースの精度に影響を与える可能性があります
- 言語サポート:多言語モデルは、より多くのストレージと計算リソースを必要とします
Curifyの生産転写アーキテクチャ
Curifyの転写システムは、スケール、精度、信頼性のために設計された最先端の音声処理技術の生産グレードの実装を表しています。当社のアーキテクチャは、最小限の人間の介入で動画コンテンツをエンドツーエンドで処理するために、複数の専門的なニューラルネットワークを統合したパイプラインを組み合わせています。
コア技術コンポーネント:
音声処理スタック:Conv-TasNetを音声分離に、WhisperXを転写に利用することで、Curifyはノイズの多い環境でも95%以上の精度を達成します。システムは16kHzの解像度で音声を処理し、リアルタイムのノイズ削減と話者識別を適用して個々の声を分離します。
品質保証パイプライン:自動化された信頼度スコアリングは、人間のレビューのために潜在的な転写エラーを特定します。システムは、技術コンテンツの精度を向上させるためにドメイン固有の用語で訓練された言語モデルを使用し、業界特有の語彙に対するファインチューニング機能を備えています。
インフラストラクチャ:分散処理を持つGPUクラスターに展開され、100以上の同時転写ジョブを処理します。システムは、コンテンツの複雑さと音声品質に応じて、約2分で1時間の動画を処理します。
パイプラインオーケストレーション:Azure Service Busキューが処理ステージ間の調整を行い、失敗や再試行を自動的に処理できるフォールトトレラントなワークフローを実現します。システムは、コスト効率のためのバッチ処理とリアルタイムアプリケーションのためのストリーミングの両方をサポートします。
🎯 あなたの組織のために高度な転写パイプラインを実装する準備はできましたか? Curifyの技術転写ソリューションを探る
動画転写技術の未来
ビデオ転写技術は、基本的な音声認識システムから、ニューラルネットワーク、音声処理、最適化技術の進歩を組み合わせた高度なマルチステージパイプラインへと進化しました。Curifyのパイプラインのような現代のシステムは、音声分離のためのConv-TasNet、転写のためのWhisperX、そして高度な品質保証が生産グレードのワークフローに統合できることを示しています。
技術チームや開発者にとっての重要なポイントは、ビデオ転写はもはや研究の問題ではなく、解決されたエンジニアリングの課題であるということです。残された機会は、基本的な技術的制限ではなく、最適化、エッジケース、統合にあります。これらのシステムがより良いモデルアーキテクチャと大規模なトレーニングデータセットを通じて改善され続ける中で、あらゆるコンテンツタイプに対して完璧な転写がスケールで利用可能になる未来に近づいています。
ここで説明されている技術アーキテクチャは2026年の最先端を代表していますが、この分野は急速に進化し続けています。リアルタイム転写、ゼロショットスピーカー識別、自動コンテンツ要約は、ビデオコンテンツの処理と分析へのアプローチをさらに変革する新たな能力として既に現れています。
Take the next step
Putting what you read into practice.