L'usine de contenu IA : Pourquoi les agences de marketing doivent arrêter d'acheter des outils et commencer à construire des pipelines

La plupart des propriétaires d'agences de marketing rencontrent le même mur autour du même nombre de clients. Le 11ème contrat est signé, deux autres designers sont embauchés, et la marge brute sur les dix comptes originaux chute d'une manière ou d'une autre. Embauchez plus vite que vous ne vendez et vous vous retrouvez à court ; vendez plus vite que vous n'embauchez et la qualité s'effondre ; évaluez le travail à des tarifs "compétitifs" et l'économie unitaire ne se ferme jamais. C'est le piège de la scalabilité humaine, et pour les agences qui gèrent des publications sociales à bas prix et des travaux d'affichage saisonniers, c'est structurel — pas un problème de planification. Acheter ChatGPT, Midjourney et un outil de mise en page SaaS ne le brise pas. Cela déplace simplement le goulot d'étranglement de "heures de designer" à "heures de réglage de prompts de designer." La véritable sortie est une architecture complètement différente : arrêtez d'essayer de rendre les employés individuels plus rapides dans l'ancien flux de travail et commencez à gérer la production de contenu de l'agence comme un système de recommandation à haute concurrence.
Pourquoi les forfaits sociaux à bas prix saignent la marge
La règle 55:25:20 de l'Institut de gestion des agences est la référence à laquelle chaque agence saine se réfère : 55 % du revenu brut ajusté pour les personnes, 25 % pour les frais généraux, 20 % conservés comme bénéfice net. Ce calcul fonctionne avec un revenu par employé d'environ 135 000 $ à 257 000 $. Regardez maintenant le contrat standard des PME sur les réseaux sociaux — 500 $ à 1 500 $ par mois pour deux à trois plateformes et 8 à 12 publications.
Faites le calcul honnêtement. Un contrat de 1 000 $ correspond à environ 40 heures facturables, et ces heures doivent couvrir la stratégie, le design, la rédaction, la planification, les allers-retours avec le client, les révisions et toute QA. Il n'y a pas de scénario réaliste dans lequel un designer junior gérant trois contrats par semaine maintient la marge à flot. La plupart des agences s'en sortent de l'une des deux manières :
- Tarification de perte leader. Prenez les petits comptes à perte, espérez vendre des services premium plus tard. En pratique, cela ancre la marque au prix de perte leader et la vente additionnelle n'arrive presque jamais.
- Sous-livraison silencieuse. Atteindre le nombre de publications contracté mais sauter la stratégie, la QA et le polissage inter-plateformes.
Les deux chemins enferment l'agence dans des prix bas et poussent les employés à se concentrer sur le travail de livraison qui écarte le développement de nouvelles affaires. La concentration sur un seul client au-dessus de 40 % devient un mur porteur, et le propriétaire finit par gérer un emploi gonflé plutôt qu'une entreprise à effet de levier.
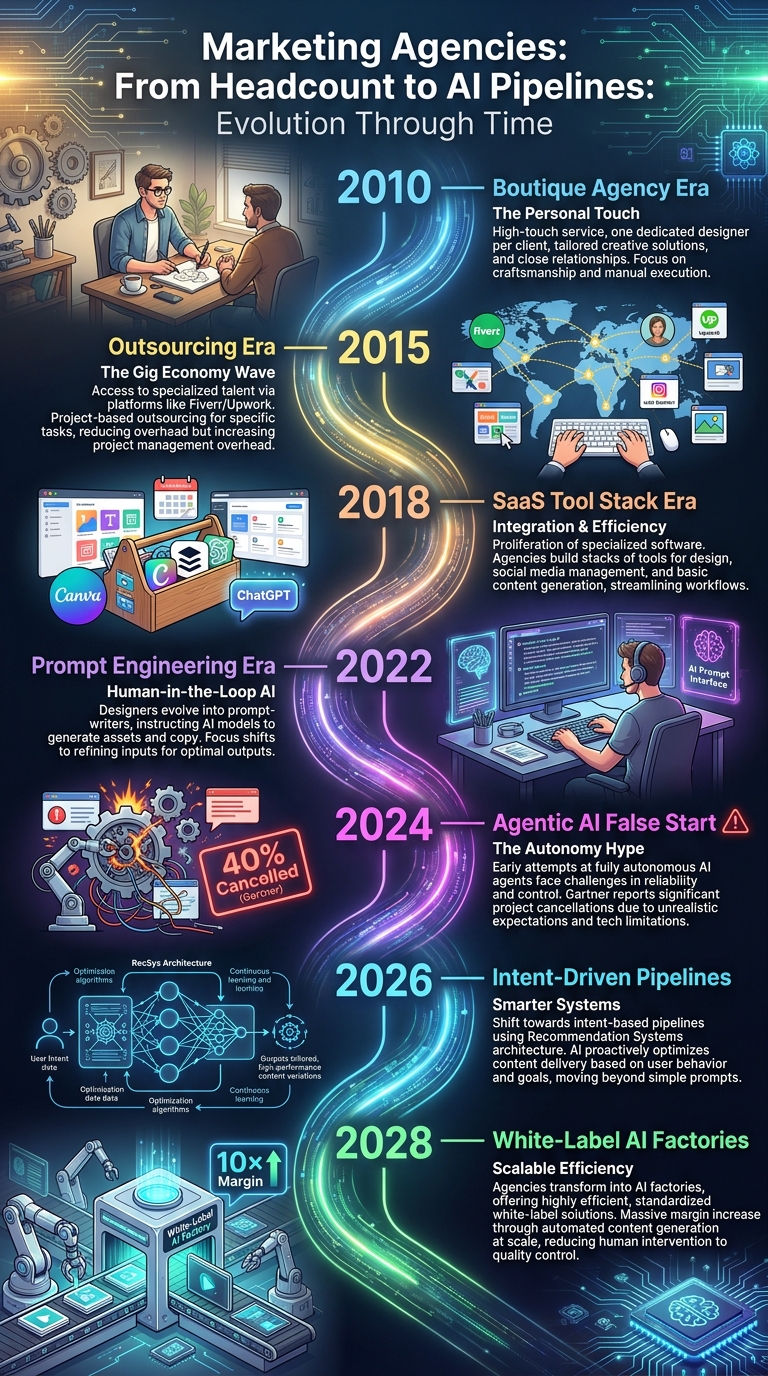
Emprunter l'architecture en quatre étapes des systèmes de recommandation
1. Récupération — L'intention remplace le brief créatif
Flux traditionnel : le responsable de compte réalise un appel de découverte de 60 minutes avec le client, rédige un brief créatif, le remet à un stratège qui le remet à un designer.
Flux de pipeline : chaque client a un Profil de Workspace structuré — couleurs de marque sous forme de codes hexadécimaux, descripteurs de voix (autoritaire / ludique / technique), trois principales offres, spécification du persona de l'audience cible, contexte géographique. Lorsqu'un sujet de campagne unique arrive ("vente flash du Black Friday"), la couche de récupération consulte le profil, extrait la structure de modèle correspondante d'une bibliothèque de modèles sélectionnés et émet un objet d'intention structuré. Pas d'appel de découverte. Pas de directive de marque mal mémorisée. La couche d'intention est également là où vous encodez les hiérarchies : "la conformité à la marque l'emporte toujours sur la latitude créative," "le logo doit rester clair et non obstrué," "les conventions CTA de la plateforme prennent le pas sur les préférences de texte." C'est ce que les ingénieurs en IA appellent l'ingénierie de l'intention — encoder les priorités commerciales dans le système lui-même au lieu de les coller dans des chaînes de prompts.
2. Filtrage — Le rendu découplé élimine le problème du texte incompréhensible
La raison pour laquelle les premiers outils "auto-poster" se sont ridiculisés est la même que celle des premiers modèles de diffusion qui se sont ridiculisés en typographie : un seul modèle d'image de bout en bout essayant de rendre un anglais lisible sur un fond texturé hallucine des caractères comme un panneau néon ivre. La solution de production est le rendu découplé — gardez le modèle d'image dans son domaine (générez l'art de fond, la couche texturée, le motif illustratif), puis compositez la typographie par-dessus via un moteur de rendu déterministe qui connaît les polices, le crénage et les boîtes de délimitation.
Associé à une vérification multimodale (un petit modèle de vision-langage vérifie chaque rendu pour conformité — logo présent, pas de texte cassé, hex de marque dans la tolérance) et une récompense esthétique ajustée par RLHF, l'étape de filtrage élimine complètement la boucle de correction humaine. Les bases open-source sur la génération d'affiches atteignent maintenant ~0,77 OCR F1 sur la sortie rendue — ce qui signifie que le système lit sa propre sortie avant de la servir. Les designers cessent d'être des éditeurs de texte pour le modèle.
3. Évaluation — Une intention, cinquante variantes, mise en page pixel parfaite
Avec l'art de fond validé, l'étape d'évaluation assemble l'actif final selon les spécifications : logos vectoriels placés à des coordonnées exactes, boutons CTA dimensionnés selon les conventions de la plateforme, marges de débordement définies pour l'impression, zones de sécurité respectées pour les découpes de vidéos verticales. La technologie est peu remarquable une fois que vous la nommez — un moteur de rendu HTML/CSS/SVG sans tête (un cluster Puppeteer ou Playwright) piloté par une file d'attente de tâches asynchrones (Celery + Redis est la pile commune).
Ce qui est intéressant, c'est la conséquence architecturale : une intention de campagne se divise en 50 variantes adaptées à la plateforme en parallèle sans que quiconque n'ouvre Photoshop. C'est là que le coût par compte se déplace réellement. Un contrat de 1 000 $ qui consommait auparavant 40 heures de designer consomme maintenant quelques centimes de calcul. Le coût incrémentiel de l'agence pour ajouter le 11ème client est une ligne de configuration, pas une embauche.
4. Service — Publication automatique, pas copier-coller
La dernière étape est celle où la plupart des contenus "IA pour agences" s'arrêtent — génération sans distribution. Le pipeline pousse les actifs finis et le texte par plateforme directement dans une file d'attente de publication : API Graph Meta pour Instagram et Facebook, API X pour Twitter, Buffer ou flux n8n pour la longue traîne. Pas de captures d'écran passées dans Slack, pas de "pouvez-vous ajouter le texte alternatif sur TikTok," pas de rush du vendredi soir pour copier-coller des légendes sur cinq onglets.
Une fois le service automatisé, le modèle opérationnel de l'agence change de forme. Les responsables de compte passent leur temps sur la stratégie et la croissance des comptes ; le système de production gère l'exécution. La ligne de personnel sur le P&L se découple de la ligne de compte client.
Pourquoi "Il suffit d'utiliser de meilleurs prompts" ne vous amène pas ici
La plupart des agences qui essaient d'automatiser échouent à l'un des trois endroits :
- Cadre d'outil vs cadre de système. Elles traitent l'IA comme un employé plus rapide au lieu de redessiner le flux de travail. Les designers finissent par "écrire des prompts" au lieu de "faire du design." Le goulot d'étranglement se déplace mais ne diminue pas.
- Dérive des objectifs. Sans une couche d'intention imposant la conformité à la marque, l'agent optimise ce qui est le plus facile à mesurer (taux de clics, vitesse de génération) et sacrifie discrètement ce qui n'est pas mesuré (consistance de la marque, confiance des clients). Quelques semaines plus tard, le système expédie du clickbait à grande échelle.
- Le piège de l'escalade. Chaque fois que l'agent hallucine un JSON mal formé, un texte illisible ou une composition couvrant le logo, le flux de travail se bloque et un humain doit nettoyer. Le débit est alors limité à la bande passante de révision de l'humain — le système "automatisé" mais pratique ne fait que mettre en file d'attente le travail pour le même designer qui le faisait auparavant.
Gartner prévoit que plus de 40 % des projets d'IA agentique d'entreprise seront annulés d'ici la fin de 2027 — non pas parce que les modèles se sont détériorés, mais parce que l'architecture environnante n'a jamais été construite. La solution n'est pas de meilleurs prompts. C'est la récupération validée par schéma, le rendu déterministe, l'évaluation automatisée et l'observabilité — la même hygiène d'ingénierie qui a transformé les systèmes de recommandation de démonstrations de recherche en infrastructures.
Tools & Resources
Learn about the best tools available...
Où cela se joue chez Curify
Le modèle en quatre étapes ci-dessus n'est pas théorique. La pile Curify Studio le livre de bout en bout, et une agence peut l'utiliser comme un backend en marque blanche :
- Récupération. Les profils de l'espace de travail capturent les spécifications de marque de chaque client une fois et alimentent chaque étape en aval. Deux bibliothèques de modèles sélectionnés —
template-marketingpour les formats de campagne ettemplate-mbtipour les variations segmentées par audience — fournissent une structure sans brief.
- Filtrage. 172 modèles de prompt paramétrés avec des entrées typées à travers /nano-template gardent chaque rendu validé par un schéma. Le modèle ne voit jamais un prompt libre ; l'agence ne voit jamais une erreur d'analyse.
- Évaluation. Une couche de rendu sans tête décline une intention de campagne en 50 variantes adaptées aux plateformes — carré Instagram, vertical Story, paysage LinkedIn, portrait X, le tout en parallèle.
- Distribution. Publication automatique sur Twitter et Facebook sur des créneaux de hash-bucket ; voir
/tools/video-dubbingpour le pipeline équivalent de doublage et de distribution sur vidéo.
Pour une agence, l'avantage réside dans la couche en marque blanche. Le client se connecte à un tableau de bord de marque d'agence ; l'agence exécute le pipeline de Curify en arrière-plan ; la ligne de personnel sur le P&L cesse de croître avec le nombre de clients.
Le saut de marge de 10× se trouve dans l'architecture, pas dans les prompts
Les agences qui se développeront au cours des deux prochaines années ne seront pas celles qui ont embauché les ingénieurs de prompts les plus intelligents. Ce seront celles qui ont cessé de penser à l'IA comme un outil plus rapide pour le même flux de travail et ont commencé à considérer la production de contenu comme un problème d'ingénierie avec une forme connue — récupérer, filtrer, évaluer, servir.
Pour un propriétaire d'agence regardant les 10 prochains contrats et redoutant silencieusement les 10 prochaines embauches, la question à poser n'est pas "quel outil IA devrais-je acheter ?" La question est : "à quoi ressemblerait mon P&L si mon coût incrémentiel par client était une ligne de configuration au lieu d'un effectif ?"
Cet écart — entre la béquille de l'ingénierie de prompts et le pipeline d'ingénierie de l'intention — est là où la prochaine décennie de marges d'agence se construit ou se perd.
Take the next step
Putting what you read into practice.
Articles Connexes
Content Automation
De Probabiliste à Déterministe : Vérités Difficiles sur l'Ingénierie de l'IA en Production
L'IA redéfinit le flux de travail des données : de l'assistant à l'agent