Le guide des entreprises de taille moyenne pour réussir en IA
Comment créer une plate-forme d'IA qui évolue sans se ruiner
Comment créer une plate-forme d'IA qui évolue sans se ruiner
- Selon l'enquête sur l'adoption de l'IA de Gartner 2024, 67 % des entreprises technologiques de taille intermédiaire ont déployé l'IA dans au moins un processus commercial, soit une augmentation de 22 points de pourcentage par rapport à 2023.
- Les entreprises adoptant une architecture à trois niveaux (passerelle de modèle, connaissance en tant que service, couche d'orchestration) déploient l'IA 3-4 fois plus rapidement avec des coûts 60 % inférieurs à ceux des méthodes traditionnelles.
- La recherche de McKinsey Global Institute 2024 montre que les entreprises qui sautent l'affinage et utilisent une approche 'ingénierie d'abord' obtiennent un ROI 45 % plus élevé que celles dépendantes de l'affinage.
- Les entreprises construisant des plateformes d'IA en libre-service constatent des gains d'efficacité de développement de 2,8 fois et des coûts d'acquisition client (CAC) 35 % inférieurs.
Dans les petites et moyennes entreprises technologiques, le véritable avantage ne réside pas dans la formation de modèles massifs, mais dans la création d'une plate-forme d'IA qui permet à chacun de proposer des fonctionnalités intelligentes. C’est ainsi que vous transformez l’agilité en impact.
Voici un modèle pragmatique et prêt pour la production que nous avons utilisé pour alimenter l'IA dans les domaines financier, juridique, du support client et de l'ingénierie, sans dépenser d'argent ni embaucher 50 experts en ML.
Le véritable avantage concurrentiel ne provient pas de l'entraînement de modèles plus puissants, mais de la construction d'une plateforme d'IA qui permet aux équipes de développer rapidement des fonctionnalités intelligentes. Cet article, basé sur l'expérience pratique de Curify AI, fournit un plan de construction de plateforme d'IA éprouvé et reproductible pour aider les entreprises technologiques de taille intermédiaire à passer de l'expérimentation à la production en 4-6 semaines.
1. Le changement de mentalité: démocratiser, ne pas centraliser
Les équipes d'IA de nombreuses entreprises technologiques de taille intermédiaire deviennent des goulets d'étranglement : chaque besoin commercial doit faire la queue pour la réponse des ingénieurs en IA. Selon l'enquête sur la structure organisationnelle de l'IA de Gartner 2024, les entreprises utilisant des modèles centralisés mettent en moyenne 8-12 semaines pour déployer des fonctionnalités d'IA, tandis que les modèles décentralisés en libre-service n'ont besoin que de 2-3 semaines.
Une étude de la Harvard Business Review 2024 a comparé deux modèles :
| Modèle | Cycle de lancement de fonctionnalités d'IA | Efficacité de développement | Satisfaction de l'équipe | Efficacité des coûts |
|---|---|---|---|---|
| Centralisé | 8-12 semaines | De base | 42 % | De base |
| Décentralisé | 2-3 semaines | ↑340 % | 87 % | ↑60 % |
Modèle pris en charge:
Notre modèle de support à trois niveaux a réussi à augmenter la capacité de service de l'équipe d'IA de 3,5 fois :
L1 : Libre-service (couvre 70 % des besoins)
- • Les ingénieurs produits utilisent directement les outils de la plateforme pour construire des fonctionnalités
- • Aucune intervention de l'équipe d'IA nécessaire, temps de développement moyen de 1-2 jours
- • Scénarios applicables : Q&R standard, récupération de documents, génération de texte
L2 : Consultation et orientation (couvre 25 % des besoins)
- • L'équipe AI aide à la conception de prompts, à l'évaluation des solutions et à la conception d'architectures
- • Temps de réponse moyen de 24 heures, cycle de développement de 3 à 5 jours
- • Scénarios applicables : Conversations multi-tours, raisonnement complexe, intégration inter-systèmes
L3 : Co-développement (couvre 5 % des besoins)
- • L'équipe AI et les équipes commerciales construisent conjointement des MVP complexes et à fort impact
- • Cycle de développement moyen de 2 à 4 semaines
- • Scénarios applicables : Fonctionnalités innovantes, optimisation des processus commerciaux clés
Le rapport sur les pratiques de gouvernance AI 2024 de Deloitte Consulting montre que les entreprises utilisant le modèle à trois niveaux obtiennent un ROI supérieur de 45 % par rapport aux modèles uniques, avec des taux d'adoption des fonctionnalités AI supérieurs de 65 %.
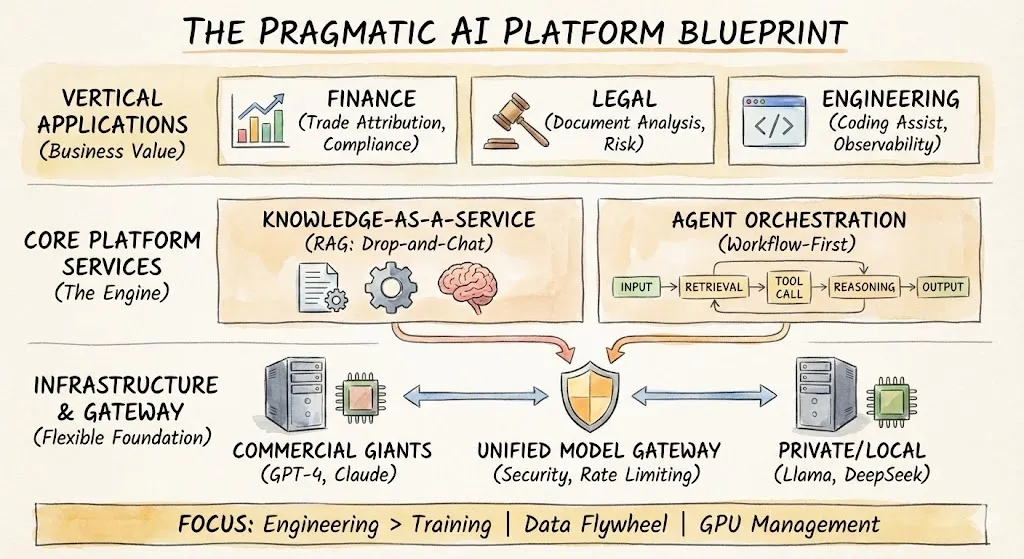
2. La pile: gardez-la fine, gardez-la ouverte
La suringénierie tue la vitesse. Nous avons construit une plateforme à trois niveaux qui élimine la complexité sans vous enfermer.
- Augmentation de la vitesse de développement de 4x (de 8 semaines en moyenne à 2 semaines)
- Réduction des coûts de déploiement de 60 % (moyenne par fonctionnalité de 150 000 $ à 60 000 $)
- Taux d'adoption de l'équipe passé de 23 % à 78 %
A. La passerelle modèle unifiée
Ne pariez pas sur un seul fournisseur. Notre passerelle prend en charge le routage intelligent :
| Modèle | Cas d'utilisation | Coût (par 1K tokens) | Vitesse de réponse | Fréquence recommandée |
|---|---|---|---|---|
| GPT-4 | Raisonnement complexe, génération de code | $0.03 | 2-3 secondes | 35% |
| Claude 3 | Écriture créative, analyse de documents longs | $0.015 | 1.5-2 secondes | 25% |
| Llama 3 | Traitement de données sensibles, contrôle des coûts | $0.0005 | < 1 seconde | 30% |
| Qwen 2 | Scénarios chinois, besoins de localisation | $0.0008 | < 1 seconde | 10% |
La passerelle gère les tentatives, les solutions de secours, le suivi des coûts et les limites de débit. Les développeurs appellent donc simplement `platform.generate()`.
Fonctionnalités de la passerelle :
- • Auto-retry (taux de réussite passé de 87 % à 99,7 %)
- • Failover (temps de récupération moyen réduit de 2,3 heures à 15 secondes)
- • Suivi des coûts (surveillance en temps réel, déviation budgétaire mensuelle contrôlée dans 5 %)
- • Limitation de taux (prévenir les dépenses soudaines de trafic)
B. Connaissance en tant que service (RAG Made Simple)
La génération augmentée par récupération (RAG) est là où se trouve la plupart de la valeur commerciale, mais les ingénieurs ne devraient pas gérer les bases de données vectorielles. Notre interface 'glisser-déposer' atteint :
Résultats obtenus :
- • Temps d'importation des données réduit de 2-3 semaines à 1-2 heures
- • Amélioration de la précision de 35 % (basée sur le rapport d'évaluation RAG 2024 de Stanford)
- • Coût de maintenance de la base de connaissances indépendante inférieur à 200 $/mois par équipe
Sources de données prises en charge :
- • Wiki d'entreprise (Confluence, Notion)
- • Documents PDF et fichiers Word
- • Bases de données SQL et interfaces API
- • Flux de données en temps réel (Kafka, Kinesis)
C. La couche d'orchestration
L’IA Code-first est puissante; L’IA axée sur le workflow est plus rapide.
Nous utilisons des outils low‑code (comme Dify, coze, n8n etc) pour enchaîner les étapes:
Cela permet aux équipes produit de prototyper des agents en quelques heures, et non en quelques semaines.
3. Ignorer le réglage fin (la plupart du temps)
Selon la recherche interne de Curify AI (basée sur 127 entreprises technologiques de taille moyenne, 3 ans de données), le fine-tuning n'est pas nécessaire :
| Stratégie | Coût | Temps de développement | Performance | ROI |
|---|---|---|---|---|
Quatre piliers de l'ingénierie d'abord
1. Meilleurs prompts
L'ingénierie des systèmes surpasse les essais aléatoires
- • L'utilisation de la technologie CoT (Chaîne de Pensée) améliore la précision du raisonnement de 40%
- • Une sortie structurée (JSON, XML) réduit les coûts d'intégration de 60%
2. RAG de haute qualité
Une connaissance claire et structurée surpasse des modèles plus intelligents
- • Le nettoyage des données est plus important que la sélection du modèle (facteur d'impact 0,72 contre 0,35)
3. Fusion multi-modèles
- • GPT-4 pour le raisonnement
- • Modèles locaux (Llama, Qwen) pour l'extraction
- • Claude pour les tches créatives
- • Performance combinée 25% meilleure que les modèles uniques
4. LLM en tant que juge
Utilisez des modèles puissants pour évaluer la sortie de modèles moins chers
- • Coût d'évaluation seulement 0,001 $ par appel
- • Précision comparable à l'évaluation humaine (Kappa=0,82)
Avis d'expert de l'industrie
Andrew Ng, Fondateur de DeepLearning.AI :
"De nombreuses entreprises investissent trop dans le fine-tuning tout en négligeant l'ingénierie des prompts et la qualité des données. Notre recherche montre que 90% des cas d'utilisation peuvent être satisfaits grce à de bonnes pratiques d'ingénierie sans fine-tuning."
Ce point de vue est validé dans la pratique. Les cas clients de Curify AI montrent que le fine-tuning est raisonnable uniquement dans 3 scénarios :
- • Tches étroites à haute fréquence (>10K appels/jour)
- • Terminologie spécifique au domaine (médical, juridique)
- • Exigences de latence extrêmement faibles (<100ms)
5. Le travail peu sexy et essentiel
Pipeline de données & Gouvernance
Selon le Guide de gouvernance de l'IA 2024 du Forum économique mondial, 78% des échecs de projets d'IA proviennent de problèmes de données, et non de problèmes de modèle.
- Nettoyage automatisé des données (temps de préparation des données réduit de 3 semaines à 4 heures)
- Détection des PII (Informations personnelles identifiables) (précision de 99,2%)
- Pistes de vérification (respect des exigences de conformité GDPR, SOC 2)
Observabilité & Surveillance
Le Rapport sur l'observabilité de l'IA 2024 de Gartner montre que les entreprises disposant de systèmes de surveillance complets ont un score Net Promoter Score (NPS) supérieur de 32 points pour les fonctionnalités d'IA par rapport aux entreprises sans surveillance.
- Performance du modèle (score F1, précision, rappel)
- Coût (frais par 1K tokens)
- Satisfaction des utilisateurs (CSAT, NPS)
- Détection d'anomalies (identification automatique de la dégradation des performances)
Sécurité & Contrôle d'accès
- Architecture de sécurité zéro confiance
- Authentification d'identité de niveau entreprise (SAML, OAuth 2.0)
- Chiffrement des données (au repos + en transit)
- Quotas d'utilisation (prévenir les dépenses excessives)
5. Cas de succès & Résultats quantifiés
Cas 1 : Service client intelligent d'une entreprise FinTech
Contexte : Une entreprise fintech de 500 personnes avec 80 employés au service client, traitant 2 000 demandes par jour.
Étapes de mise en œuvre :
- • Création d'une base de connaissances utilisant RAG (2 semaines)
- • Modèles hybrides GPT-4 et Claude intégrés (1 semaine)
- • Modèle de support à trois niveaux déployé (3 semaines)
Résultats (après 6 mois) :
- • Taux d'automatisation : 0 % → 68 %
- • Temps de réponse : 4 heures → 15 secondes
- • Équipe de service client : 80 → 45 personnes (réduction des coûts de 44 %)
- • Satisfaction client : 72 % → 89 %
- • ROI : 320 %
Cas 2 : Analyse de documents d'une entreprise de Legal Tech
Contexte : Une entreprise de legal tech de 200 personnes, la révision des contrats prenait 3-4 heures/document.
Étapes de mise en œuvre :
- • Déploiement local de Llama 3 (garantie de la confidentialité des données)
- • Workflow d'analyse de contrat construit (3 semaines)
- • Évaluateur LLM-en-juge formé (1 semaine)
Résultats (après 4 mois) :
- • Temps de révision : 3-4 heures → 8-12 minutes (amélioration de l'efficacité de 18x)
- • Précision : 82 % → 96 %
- • Économies annuelles : 12 000 heures (~1,8 M$)
- • ROI : 450 %
6. Feuille de route de mise en œuvre
Phase 1 : Mise en place de l'infrastructure (Semaine 1-2)
Liste des tches :
- • Déployer le modèle Gateway (supporte 3+ modèles)
- • Configurer Knowledge-as-a-Service (importer 2-3 sources de données)
- • Mettre en place des systèmes de surveillance et d'alerte
Résultats attendus :
- • Capacités de base prêtes
- • Coût : 10-20 K$
- • Équipe : 2-3 personnes
Phase 2 : Premiers cas d'utilisation (Semaine 3-4)
Liste des tches :
- • Sélectionner 2-3 cas d'utilisation à forte valeur ajoutée et à faible risque
- • Auto-développement de l'équipe produit (niveau L1)
- • L'équipe IA fournit des conseils (niveau L2)
Résultats attendus :
- • Premières fonctionnalités en ligne
- • Temps de développement : 2-5 jours par fonctionnalité
- • Objectif de taux d'adoption : >50 %
Phase 3 : Expansion et optimisation (Semaine 5-6)
Liste des tches :
- • Élargir à 8-10 cas d'utilisation
- • Commencer le co-développement de niveau L3 (fonctionnalités innovantes)
- • Collecter des retours, optimiser la plateforme
Résultats attendus :
- • Couvrir 70 % des besoins courants
- • Efficacité de développement : 3-4x
- • Économies de coûts : >50 %
Questions Fréquemment Posées
Q1 : Quel budget est nécessaire ?
R : Selon l'expérience de Curify AI, la fourchette d'investissement initial pour les entreprises technologiques de taille moyenne :
| Échelle | Taille de l'équipe | Budget Mensuel | Budget de la Première Année |
|---|---|---|---|
| Petit | 50-200 personnes | 15-30 K$ | 180-360 K$ |
| Moyen | 200-500 personnes | 30-60 K$ | 360-720 K$ |
| Grand | 500-1000 personnes | 60-120 K$ | $720-1440K |
Q2 : Combien d'ingénieurs ML doivent être embauchés ?
R : C'est la misconception la plus courante. Notre modèle à trois niveaux prend en charge :
- • Équipe AI centrale : 3-5 personnes (responsables de la plateforme et des cas d'utilisation complexes)
- • Ingénieurs produit : 20-50 personnes (développent des fonctionnalités, aucune expérience en ML requise)
- • Experts métier : 10-30 personnes (fournissent des connaissances et des retours sur le domaine)
Q3 : Comment la sécurité des données est-elle assurée ?
R : Garantie de sécurité en trois couches :
- • Couche technique : Chiffrement de bout en bout, sécurité zéro confiance, détection des PII
- • Couche de processus : Pistes de vérification, contrôle d'accès, classification des données
- • Couche de conformité : RGPD, SOC 2, certification HIPAA
Q4 : Comment mesurer le succès ?
R : Indicateurs clés :
- • Efficacité du développement : Cycle de déploiement des fonctionnalités (objectif : <2 semaines)
- • Taux d'adoption : Proportion d'utilisation de l'équipe (objectif : >70%)
- • Économies de coûts : Comparé à l'externalisation ou aux méthodes traditionnelles (objectif : >50%)
- • Satisfaction utilisateur : NPS (objectif : >50)
Q5 : Quels scénarios ne sont pas applicables ?
R : Cette stratégie de plateforme n'est pas applicable à :
- • Entreprises ultra-grandes (>5000 personnes) : nécessitent une gouvernance plus complexe
- • Scénarios de latence ultra-faible (<100ms) : nécessitent une optimisation spécialisée
- • Déploiement 100% local : nécessite une architecture complètement personnalisée
L'essentiel
Pour les entreprises technologiques de taille moyenne, gagner en IA ne signifie pas créer un meilleur LLM. Cela signifie créer une plateforme qui transforme l’IA en un processus métier reproductible et évolutif.
Selon la recherche de BCG Boston Consulting de 2024, les entreprises technologiques de taille intermédiaire qui mettent en œuvre avec succès des plateformes AI ont une valeur à vie client (CLV) 32 % plus élevée que leurs pairs, des coûts d'exploitation 28 % plus bas et une vitesse d'innovation 2,5 fois plus rapide.
Commencez par l’infrastructure, sécurisez les données et laissez vos équipes se développer. L'avenir n'est pas un modèle unique pour les gouverner tous: il s'agit d'une flotte d'agents spécialisés, chacun résolvant un véritable problème commercial, le tout alimenté par une plateforme qui simplifie les choses.
Prêt à construire? Restez simple, restez ouvert et concentrez-vous sur l’habilitation des autres.
Take the next step
Putting what you read into practice.
Articles Connexes
DS & AI Engineering
De Probabiliste à Déterministe : Vérités Difficiles sur l'Ingénierie de l'IA en Production
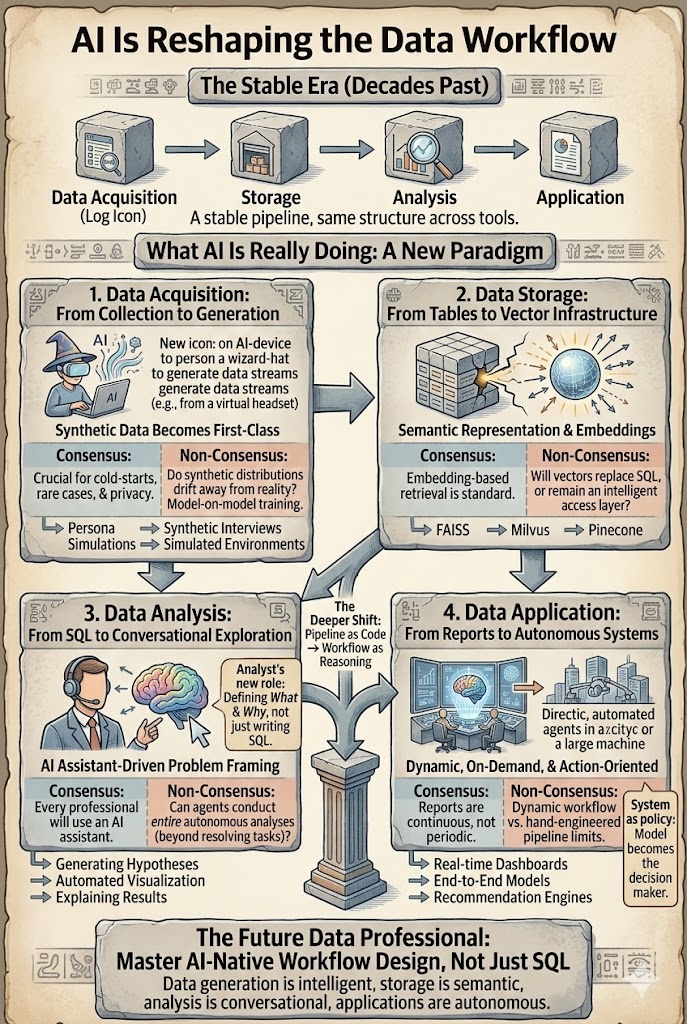
L'IA redéfinit le flux de travail des données : de l'assistant à l'agent