L'IA redéfinit le flux de travail des données : de l'assistant à l'agent
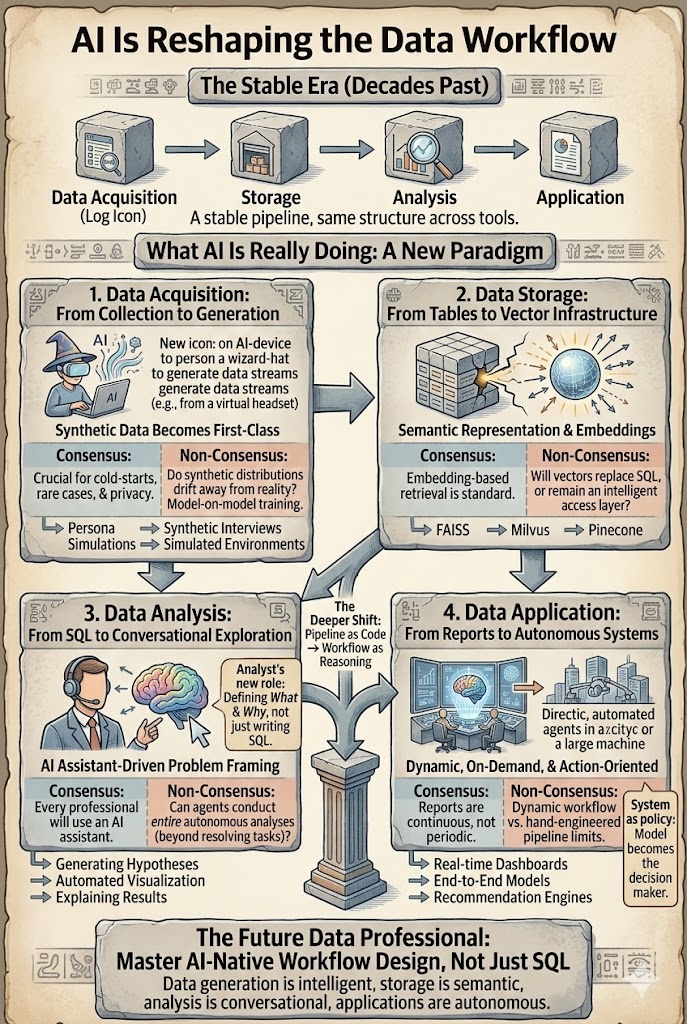
Le flux de travail des données a été remarquablement stable pendant une décennie. Que vous soyez un data scientist, un analyste ou un ingénieur en recommandations, le pipeline a à peu près toujours été le même : acquisition → stockage → analyse → application. L'IA n'accélère pas seulement ce flux de travail, elle commence à redéfinir chaque couche. La vraie question n'est plus de savoir si l'IA changera le travail des données, mais quelles parties changent clairement et quelles hypothèses s'avéreront fausses.
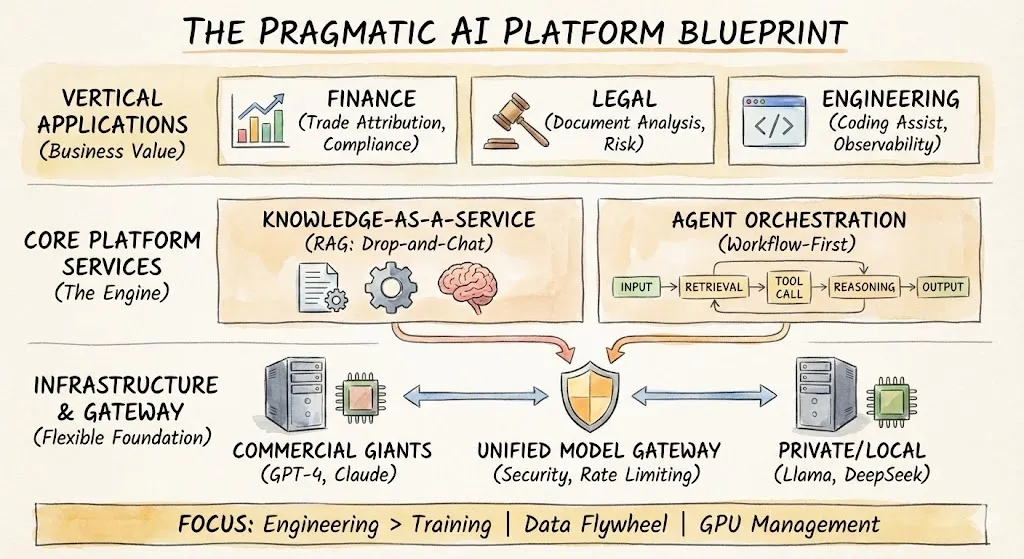
Les Quatre Couches du Flux de Travail des Données
Différents outils, différentes industries, mais fondamentalement la même structure en quatre étapes : générer ou collecter des données, les stocker, les analyser, appliquer l'insight. Ce pipeline a alimenté dix ans de recherche, de publicités et de systèmes de recommandations avec relativement peu de changements de forme. Ce qui a changé, c'est la profondeur à laquelle chaque couche est maintenant redéfinie par de grands modèles et agents. Les sections ci-dessous parcourent chaque couche et séparent le consensus (ce qui change clairement) du non-consensus (ce qui est encore sujet à débat).
Comment Chaque Couche Change
1. Acquisition de Données — Les Données Synthétiques Devenant une Source de Premier Ordre
Traditionnellement, les données utiles provenaient du monde réel : journaux, transactions, capteurs, enquêtes. Cette hypothèse commence à se briser. De plus en plus de données sont désormais générées plutôt que collectées — à travers des simulations de persona, la modélisation comportementale, des interviews synthétiques, la génération de données de tests A/B, et des environnements simulés utilisés pour la formation et l'évaluation de l'apprentissage par renforcement.
Consensus : Les données synthétiques vont de plus en plus compléter les données du monde réel, en particulier dans les problèmes de démarrage à froid, les scénarios rares et les environnements soumis à des contraintes de confidentialité.
Non-consensus : Que se passe-t-il lorsque les modèles s'entraînent de plus en plus sur des données produites par d'autres modèles ? Les distributions synthétiques vont-elles lentement s'éloigner de la réalité et former des boucles de rétroaction ?
L'acquisition de données passe de *collection* à *génération + calibration*.
2. Stockage de Données — Des Tables à l'Infrastructure Vectorielle
Les systèmes de données traditionnels étaient construits autour du stockage structuré : bases de données relationnelles, entrepôts et magasins de colonnes. L'IA introduit une nouvelle couche — représentations vectorielles. Textes, images, vidéos, trajectoires de comportement des utilisateurs et fragments de connaissances sont de plus en plus stockés sous forme d'embeddings qui alimentent la recherche sémantique, la génération augmentée par récupération et le raisonnement multimodal. Les bases de données vectorielles telles que FAISS, Milvus et Pinecone deviennent une infrastructure centrale.
Consensus : La récupération basée sur les embeddings est désormais un modèle de conception standard. RAG est l'architecture par défaut pour ancrer les LLM dans des données propriétaires.
Non-consensus : Les vecteurs remplaceront-ils finalement les couches de stockage traditionnelles ? Ou resteront-ils une couche d'indexation au-dessus des données brutes ? Pouvons-nous reconstruire les données originales à partir des embeddings suffisamment bien pour que les vecteurs deviennent le stockage principal ?
Pour l'instant, les embeddings fonctionnent moins comme stockage et plus comme une couche d'accès intelligente. Mais cette couche a déjà redéfini la manière dont les données sont accessibles.
3. Analyse des Données — De SQL à l'Exploration Conversationnelle
La couche d'analyse change le plus rapidement. Le flux de travail traditionnel ressemblait à ceci :
définition du problème → SQL → ingénierie des fonctionnalités → modélisation → interprétation
Aujourd'hui, les systèmes d'IA peuvent assister presque chaque étape : les LLM génèrent automatiquement du SQL, proposent des hypothèses, construisent des visualisations, construisent des modèles de référence et expliquent les résultats. Le rôle de l'analyste passe de *Rédacteur de Requêtes* à *Cadreur et Validateur de Problèmes*.
Consensus : Chaque professionnel des données travaillera bientôt avec un assistant IA. Les copilotes et l'analyse basée sur le chat deviennent des incontournables.
Non-consensus : Les agents réaliseront-ils finalement des analyses complètes de bout en bout ? Dans le support client, les agents peuvent déjà gérer 80 % des tickets. L'analyse des données est plus difficile — les questions elles-mêmes sont souvent ambiguës et les objectifs changent en cours d'investigation. L'automatisation accélérera l'exécution, mais les humains resteront probablement responsables de la définition du problème.
4. Application des Données — Des Rapports aux Systèmes Autonomes
La dernière étape — appliquer les insights — évolue sur deux fronts.
Rapports. L'IA transforme déjà le reporting : résumés automatiques, graphiques, tableaux de bord et présentations à travers texte, image et vidéo. Le changement plus profond est que les rapports n'ont plus besoin d'être périodiques. Ils peuvent être générés en continu et à la demande. Le véritable gain de productivité n'est pas "écrire plus vite" mais "des rapports qui existent lorsque la question est posée."
Systèmes autonomes. La recommandation, la recherche, la publicité et la conduite autonome s'éloignent des pipelines modulaires conçus à la main vers des modèles de bout en bout où le modèle lui-même devient la politique de décision. Le changement est de *consommateur de fonctionnalités* à *générateur de stratégie*.
Assistant vs Agent — Consensus et Non-Consensus
Un consensus émergent : les assistants et les agents coexisteront à long terme. Mais l'équilibre diffère fortement selon les domaines.
| Domaine | Part de l'assistant | Part de l'agent |
|---|---|---|
| Support client | 20 % | 80 % |
| Analyse des données | 70 % | 30 % (incertain) |
| Optimisation de la politique de recommandation | 50 % | 50 % |
| Conduite autonome | 10 % | 90 % |
L'incertitude clé est l'analyse des données. Dans les domaines où la définition du problème est la partie la plus difficile, les agents ont du mal à boucler la boucle. Le résultat le plus probable : l'analyse reste dominée par les assistants, mais l'exécution devient hautement automatisée. Les humains cadrent ; les agents explorent.
Le changement plus profond n'est pas un SQL plus rapide ou de meilleurs tableaux de bord. C'est qui contrôle le flux de travail. Nous passons de *Pipeline as Code* à *Workflow as Reasoning* — de l'exécution d'étapes prédéfinies à des systèmes qui planifient des actions, explorent des hypothèses et itèrent.
Tools & Resources
Learn about the best tools available...
Où Curify S'inscrit dans Ce Changement
Curify est construit autour du modèle *Workflow as Reasoning*. Trois exemples concrets sur la plateforme aujourd'hui :
- Génération de contenu comme flux de travail, pas comme un coup unique. La bibliothèque /nano-template contient 172 modèles paramétrés qui enchaînent génération d'invite → génération d'image → étiquetage de variante → synchronisation CDN — un flux de génération, pas une invite unique.
- Accès soutenu par des embeddings au niveau de la galerie. Le corpus /nano-banana-pro-prompts de plus de 4 000 invites est consultable par tag, sujet et similarité sémantique — la couche vectorielle est le chemin d'accès, le JSON brut est la source de vérité.
- Transcription audio + vidéo comme entrée en amont. /tools/video-transcript-generator produit des transcriptions étiquetées par intervenant qui s'écoulent vers /tools/video-dubbing et /tools/translate-subtitles — un flux de travail où une entrée génère trois sorties localisées.
La Vraie Question pour les Professionnels des Données
Le flux de travail traditionnel des données ne disparaît pas. Mais il évolue : la génération de données devient plus intelligente, le stockage devient plus sémantique, l'analyse devient plus conversationnelle, les applications deviennent plus autonomes.
Une vue non-consensuelle plus radicale : les futurs systèmes de données pourraient se diviser en deux — systèmes d'analyse interprétables par les humains (pour comprendre le monde) et systèmes d'optimisation en boîte noire (pour optimiser les résultats). Lorsque les deux se séparent, les professionnels des données ne disparaissent pas ; ils deviennent des *interprètes de stratégie* plutôt que des opérateurs de données.
La vraie question pour tout professionnel des données aujourd'hui n'est plus "pouvez-vous écrire du SQL". C'est : pouvez-vous concevoir des flux de travail natifs à l'IA ?
Take the next step
Putting what you read into practice.
Articles Connexes
DS & AI Engineering
De Probabiliste à Déterministe : Vérités Difficiles sur l'Ingénierie de l'IA en Production
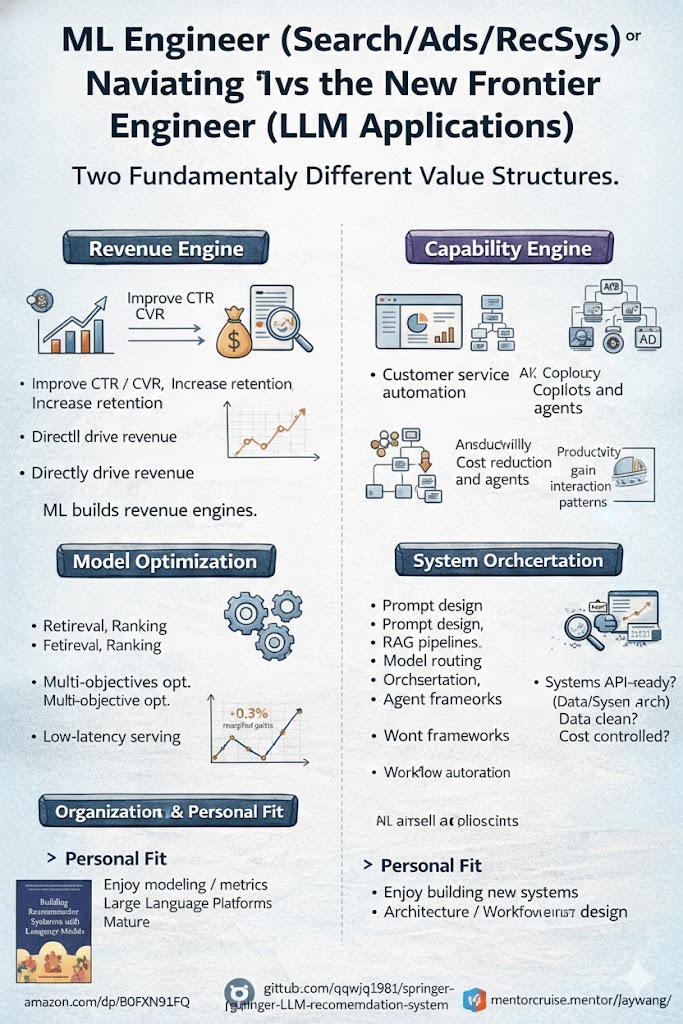
Ingénieur ML ou Ingénieur IA ? Deux Chemins de Carrière, Deux Structures de Valeur