AI Is Reshaping the Data Workflow: From Assistant to Agent
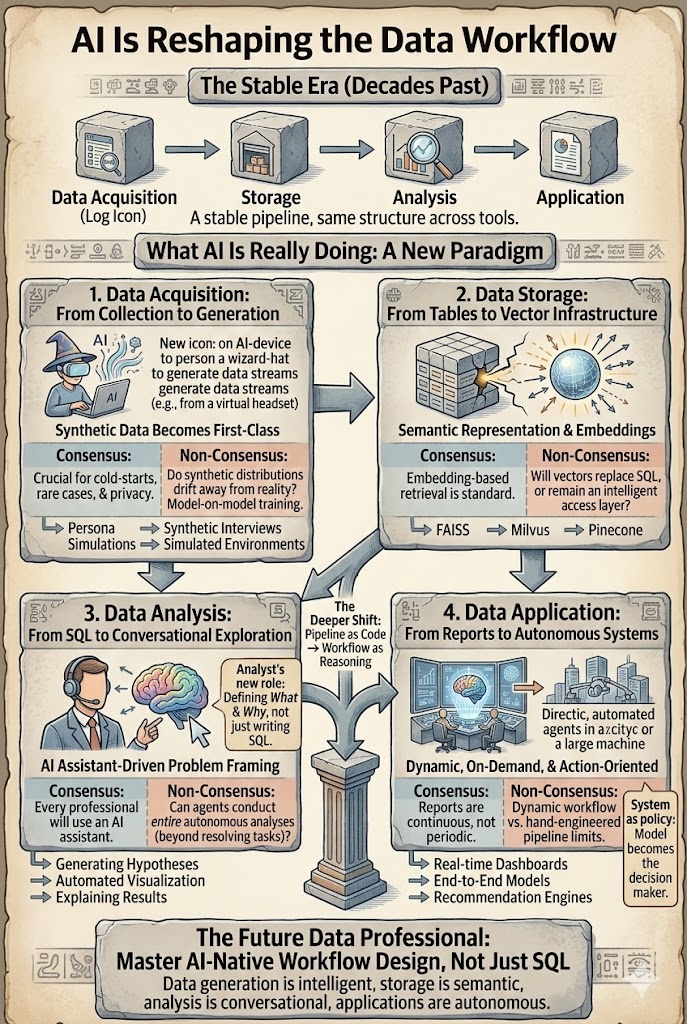
The data workflow has been remarkably stable for a decade. Whether you are a data scientist, analyst, or recommendation engineer, the pipeline has looked roughly the same: acquisition → storage → analysis → application. AI is not just accelerating this workflow — it is starting to reshape each layer of it. The real question is no longer whether AI will change data work. It is which parts are clearly changing, and which assumptions will turn out to be wrong.
The Four Layers of the Data Workflow
Different tools, different industries — but fundamentally the same four-step structure: generate or collect data, store it, analyze it, apply the insight. This pipeline has powered ten years of search, ads, and recommendation systems with relatively little change in shape. What has changed is the depth at which each layer is now being reshaped by large models and agents. The sections below walk each layer and separate the consensus (what is clearly changing) from the non-consensus (what is still up for debate).
How Each Layer Is Changing
1. Data Acquisition — Synthetic Data Becomes a First-Class Source
Traditionally, useful data came from the real world: logs, transactions, sensors, surveys. That assumption is starting to break. More and more data is now generated rather than collected — through persona simulations, behavioral modeling, synthetic interviews, A/B test data generation, and simulated environments used for reinforcement learning training and evaluation.
Consensus: Synthetic data will increasingly complement real-world data, especially in cold-start problems, rare scenarios, and privacy-constrained environments.
Non-consensus: What happens when models increasingly train on data produced by other models? Will synthetic distributions slowly drift away from reality and form feedback loops?
Data acquisition is shifting from *collection* to *generation + calibration*.
2. Data Storage — From Tables to Vector Infrastructure
Traditional data systems were built around structured storage: relational databases, warehouses, and column stores. AI introduces a new layer — vector representations. Text, images, videos, user behavior trajectories, and knowledge fragments are increasingly stored as embeddings that power semantic search, retrieval-augmented generation, and multimodal reasoning. Vector databases such as FAISS, Milvus, and Pinecone are becoming core infrastructure.
Consensus: Embedding-based retrieval is now a standard design pattern. RAG is the default architecture for grounding LLMs in proprietary data.
Non-consensus: Will vectors eventually replace traditional storage layers? Or will they remain an indexing layer on top of raw data? Can we reconstruct original data from embeddings well enough that vectors become primary storage?
For now, embeddings function less as storage and more as an intelligent access layer. But that layer has already reshaped how data is accessed.
3. Data Analysis — From SQL to Conversational Exploration
The analysis layer is changing fastest. The traditional workflow looked like this:
problem definition → SQL → feature engineering → modeling → interpretation
Today, AI systems can assist nearly every step: LLMs auto-generate SQL, propose hypotheses, build visualizations, construct baseline models, and explain results. The role of the analyst shifts from *Query Writer* to *Problem Framer and Validator*.
Consensus: Every data professional will soon work with an AI assistant. Copilots and chat-based analysis are becoming table stakes.
Non-consensus: Will agents eventually conduct entire analyses end-to-end? In customer support, agents can already handle 80% of tickets. Data analysis is harder — the questions themselves are often ambiguous and the goals shift mid-investigation. Automation will accelerate execution, but humans will likely remain responsible for framing the problem.
4. Data Application — From Reports to Autonomous Systems
The final stage — applying insights — is evolving on two fronts.
Reports. AI already transforms reporting: automatic summaries, charts, dashboards, and presentations across text, image, and video. The deeper shift is that reports no longer need to be periodic. They can be generated continuously and on demand. The real productivity gain is not "writing faster" but "reports that exist when the question is asked."
Autonomous systems. Recommendation, search, advertising, and autonomous driving are moving away from hand-engineered modular pipelines toward end-to-end models where the model itself becomes the decision policy. The shift is from *feature consumer* to *strategy generator*.
Assistant vs Agent — Consensus and Non-Consensus
One emerging consensus: assistants and agents will coexist long-term. But the balance differs sharply across domains.
| Domain | Assistant share | Agent share |
|---|---|---|
| Customer support | 20% | 80% |
| Data analysis | 70% | 30% (uncertain) |
| Recommendation policy optimization | 50% | 50% |
| Autonomous driving | 10% | 90% |
The key uncertainty is data analysis. In domains where problem definition itself is the hardest part, agents have trouble closing the loop. The most likely outcome: analysis stays assistant-heavy, but execution becomes highly automated. Humans frame; agents explore.
The deeper shift is not faster SQL or better dashboards. It is who controls the workflow. We are moving from *Pipeline as Code* to *Workflow as Reasoning* — from executing predefined steps to systems that plan actions, explore hypotheses, and iterate.
Tools & Resources
Learn about the best tools available...
Where Curify Fits in This Shift
Curify is built around the *Workflow as Reasoning* pattern. Three concrete examples on the platform today:
- Content generation as workflow, not single-shot. The /nano-template library is 172 parameterized templates that chain prompt → image generation → variant tagging → CDN sync — a generation workflow, not a one-off prompt.
- Embedding-backed access at the gallery layer. The /nano-banana-pro-prompts corpus of 4,000+ prompts is searchable by tag, topic, and semantic similarity — the vector layer is the access path, raw JSON is the source of truth.
- Audio + video transcription as upstream input. /tools/video-transcript-generator outputs speaker-tagged transcripts that flow into /tools/video-dubbing and /tools/translate-subtitles — a workflow where one input drives three localized outputs.
The Real Question for Data Professionals
The traditional data workflow is not disappearing. But it is evolving: data generation becomes more intelligent, storage becomes more semantic, analysis becomes more conversational, applications become more autonomous.
A more radical non-consensus view: future data systems may split into two — human-interpretable analysis systems (for understanding the world) and black-box optimization systems (for optimizing results). When the two separate, data professionals do not disappear; they become *strategy interpreters* rather than data operators.
The real question for any data professional today is no longer "can you write SQL." It is: can you design AI-native workflows?
Take the next step
Putting what you read into practice.
Browse related topics
More templates and prompts in these areas.
Related Articles
DS & AI Engineering
From Probabilistic to Deterministic: Hard Truths About AI Engineering in Production
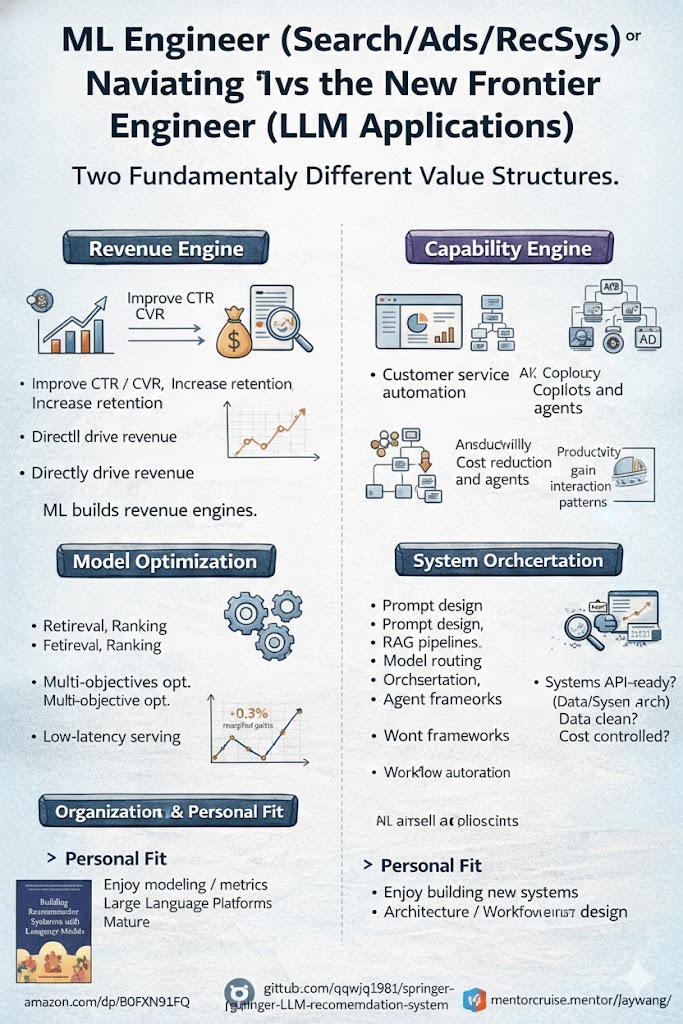
ML Engineer or AI Engineer? Two Career Paths, Two Value Structures