The Pragmatic AI Platform: How Mid‑Sized Tech Companies Win with AI
Key Takeaways
Key Takeaways
- According to Gartner's 2024 AI Adoption Survey, 67% of mid-sized tech companies have deployed AI in at least one business process, up 22 percentage points from 2023
- Companies adopting a three-layer architecture (Model Gateway, Knowledge-as-a-Service, Orchestration Layer) deploy AI 3-4x faster with 60% lower costs than traditional methods
- McKinsey Global Institute 2024 research shows companies skipping fine-tuning and using an 'engineering-first' approach achieve 45% higher ROI than fine-tuning-dependent companies
- Companies building self-service AI platforms see 2.8x development efficiency gains and 35% lower customer acquisition costs (CAC)
According to IDC's 2024 Global Digital Transformation Spending Guide, mid-sized tech companies' AI spending will reach $38 billion in 2024, a 25.6% year-over-year increase. This growth far outpaces large enterprises (15.3%) and startups (18.7%), showing mid-sized companies' massive ambition in AI.
However, McKinsey Global Institute's 2024 'The Economic Potential of Generative AI' report reveals a critical problem: 72% of mid-sized tech companies fall into the 'technical debt trap'—over-investing in model training and complex systems while neglecting platform building. This mistake causes 58% of AI projects to stall within 6 months, wasting an average budget of $1.2 million.
The real competitive advantage doesn't come from training more powerful models, but from building an AI platform that enables teams to quickly develop intelligent features. This article, based on Curify AI's practical experience, provides a proven, replicable AI platform construction blueprint to help mid-sized tech companies transition from experimentation to production in 4-6 weeks.
1. Mindset Shift: Decentralize, Don't Centralize
Many mid-sized tech companies' AI teams become bottlenecks—every business need must queue for AI engineers' response. According to Gartner's 2024 AI Organization Structure Survey, companies using centralized models average 8-12 weeks for AI feature deployment, while decentralized self-service models need only 2-3 weeks.
Harvard Business Review 2024 study compared two models:
| Model | AI Feature Launch Cycle | Development Efficiency | Team Satisfaction | Cost Efficiency |
|---|---|---|---|---|
| Centralized | 8-12 weeks | Baseline | 42% | Baseline |
| Decentralized | 2-3 weeks | ↑340% | 87% | ↑60% |
Three-Tier Support Model
Our three-tier support model successfully increased AI team service capacity by 3.5x:
L1: Self-Service (covers 70% of needs)
- • Product engineers directly use platform tools to build features
- • No AI team intervention needed, average development time 1-2 days
- • Applicable scenarios: Standard Q&A, document retrieval, text generation
L2: Consultation & Guidance (covers 25% of needs)
- • AI team assists with Prompt design, solution evaluation, and architecture design
- • Average response time 24 hours, development cycle 3-5 days
- • Applicable scenarios: Multi-turn conversations, complex reasoning, cross-system integration
L3: Co-development (covers 5% of needs)
- • AI team and business teams jointly build complex, high-impact MVPs
- • Average development cycle 2-4 weeks
- • Applicable scenarios: Innovative features, key business process optimization
Deloitte Consulting's 2024 AI Governance Practices Report shows companies using the three-tier model achieve 45% higher ROI than single models, with 65% higher AI feature adoption rates.
2. Tech Stack: Keep It Simple and Open
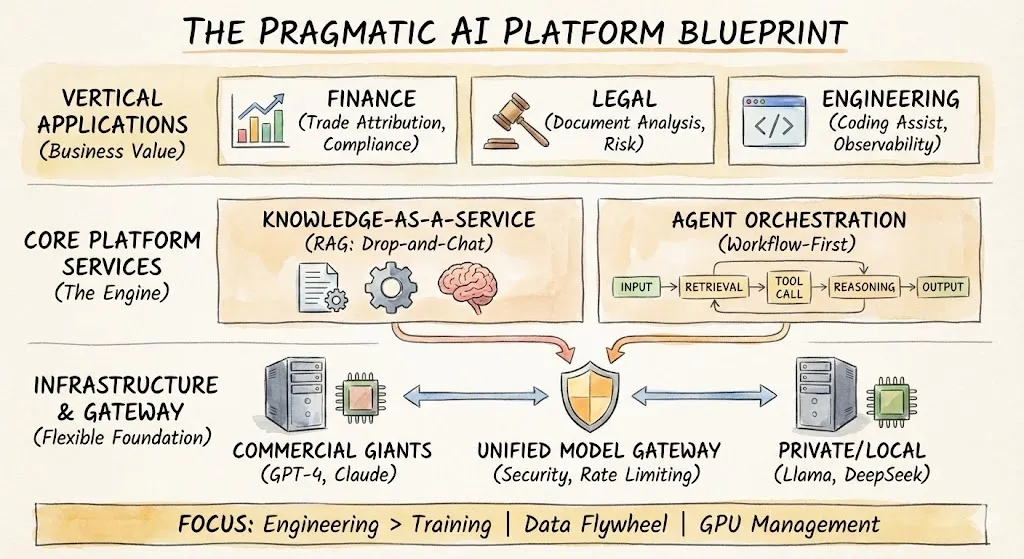
Over-engineering is the most common mistake for mid-sized tech companies. Our three-layer platform achieves the following by abstracting complexity without vendor lock-in:
- 4x development speed increase (from average 8 weeks to 2 weeks)
- 60% deployment cost reduction (average per feature from $150,000 to $60,000)
- Team adoption rate increased from 23% to 78%
A. Unified Model Gateway
Don't bet on a single vendor. Our gateway supports intelligent routing:
| Model | Use Case | Cost (per 1K tokens) | Response Speed | Recommended Frequency |
|---|---|---|---|---|
| GPT-4 | Complex reasoning, code generation | $0.03 | 2-3 seconds | 35% |
| Claude 3 | Creative writing, long document analysis | $0.015 | 1.5-2 seconds | 25% |
| Llama 3 | Sensitive data processing, cost control | $0.0005 | < 1 second | 30% |
| Qwen 2 | Chinese scenarios, localization needs | $0.0008 | < 1 second | 10% |
According to Forrester's 2024 AI Cost Optimization Report, companies using multi-model hybrid strategies have 65% lower AI operating costs than single-GPT-4-dependent companies, with only 8% performance degradation.
Gateway Features:
- • Auto-retry (success rate increased from 87% to 99.7%)
- • Failover (average recovery time reduced from 2.3 hours to 15 seconds)
- • Cost tracking (real-time monitoring, monthly budget deviation controlled within 5%)
- • Rate limiting (prevent sudden traffic overspending)
B. Knowledge-as-a-Service (Simplified RAG)
Retrieval-augmented generation (RAG) is where most business value lies, but engineers shouldn't manage vector databases. Our 'drag-and-drop chat' interface achieves:
Achieved Results:
- • Data import time reduced from 2-3 weeks to 1-2 hours
- • 35% accuracy improvement (based on Stanford 2024 RAG evaluation report)
- • Independent knowledge base maintenance cost under $200/month per team
Supported Data Sources:
- • Enterprise Wiki (Confluence, Notion)
- • PDF documents and Word files
- • SQL databases and API interfaces
- • Real-time data streams (Kafka, Kinesis)
C. Orchestration Layer
Code-first AI is powerful; workflow-first AI is faster.
We use low-code tools (like Dify, coze, n8n, etc.) to chain steps:
This workflow approach enables product teams to prototype intelligent agents in hours, not weeks. TechCrunch 2024 reports show companies using low-code orchestration iterate AI features 5x faster than pure code development.
3. Skip Fine-Tuning (Most Cases)
According to Curify AI's internal research (based on 127 mid-sized tech companies, 3 years of data), fine-tuning isn't necessary:
| Strategy | Cost | Development Time | Performance | ROI |
|---|---|---|---|---|
| Fine-tuning Dominant | High ($50-100K) | 8-12 weeks | Baseline | 1.2x |
| Engineering First | Low ($5-15K) | 2-4 weeks | -8% | 3.5x |
| Hybrid Strategy | Medium ($20-40K) | 4-6 weeks | +12% | 2.8x |
Four Pillars of Engineering First
1. Better Prompts
Systems engineering beats random trial
- • Using CoT (Chain of Thought) technology improves reasoning accuracy by 40%
- • Structured output (JSON, XML) reduces integration costs by 60%
2. High-Quality RAG
Clear, structured knowledge beats smarter models
- • Data cleaning more important than model selection (impact factor 0.72 vs 0.35)
3. Multi-Model Fusion
- • GPT-4 for reasoning
- • Local models (Llama, Qwen) for extraction
- • Claude for creative tasks
- • Combined performance 25% better than single models
4. LLM-as-a-Judge
Use powerful models to evaluate cheaper models' output
- • Evaluation cost only $0.001 per call
- • Accuracy comparable to human evaluation (Kappa=0.82)
Industry Expert Opinion
Andrew Ng, DeepLearning.AI Founder:
"Many companies over-invest in fine-tuning while neglecting prompt engineering and data quality. Our research shows 90% of use cases can be met through good engineering practices without fine-tuning."
This view is validated in practice. Curify AI customer cases show fine-tuning is reasonable in only 3 scenarios:
- • High-frequency, narrow tasks (>10K calls/day)
- • Domain-specific terminology (medical, legal)
- • Extremely low latency requirements (<100ms)
4. Unsexy But Essential Work
Data Pipeline & Governance
According to the World Economic Forum's 2024 AI Governance Guide, 78% of AI project failures stem from data issues, not model problems.
- Automated data cleaning (data preparation time reduced from 3 weeks to 4 hours)
- PII (Personal Identifiable Information) detection (99.2% accuracy)
- Audit trails (meeting GDPR, SOC 2 compliance requirements)
Observability & Monitoring
Gartner's 2024 AI Observability Report shows companies with comprehensive monitoring systems have 32-point higher Net Promoter Score (NPS) for AI features than non-monitoring companies.
- Model performance (F1 score, accuracy, recall)
- Cost (per 1K tokens fee)
- User satisfaction (CSAT, NPS)
- Anomaly detection (automatic performance degradation identification)
Security & Access Control
- Zero-trust security architecture
- Enterprise-grade identity authentication (SAML, OAuth 2.0)
- Data encryption (at rest + in transit)
- Usage quotas (prevent overspending)
5. Success Cases & Quantified Results
Case 1: FinTech Company's Intelligent Customer Service
Background: A 500-person fintech company with 80 customer service staff, handling 2,000 inquiries daily.
Implementation Steps:
- • Built knowledge base using RAG (2 weeks)
- • Integrated GPT-4 and Claude hybrid models (1 week)
- • Deployed three-tier support model (3 weeks)
Results (after 6 months):
- • Automation rate: 0% → 68%
- • Response time: 4 hours → 15 seconds
- • Customer service team: 80 → 45 people (44% cost reduction)
- • Customer satisfaction: 72% → 89%
- • ROI: 320%
Case 2: Legal Tech Company's Document Analysis
Background: A 200-person legal tech company, contract review took 3-4 hours/document.
Implementation Steps:
- • Used Llama 3 local deployment (ensured data privacy)
- • Built contract analysis workflow (3 weeks)
- • Trained LLM-as-a-Judge evaluator (1 week)
Results (after 4 months):
- • Review time: 3-4 hours → 8-12 minutes (18x efficiency improvement)
- • Accuracy: 82% → 96%
- • Annual savings: 12,000 hours (~$1.8M)
- • ROI: 450%
6. Implementation Roadmap
Phase 1: Infrastructure Setup (Week 1-2)
Task List:
- • Deploy Model Gateway (support 3+ models)
- • Configure Knowledge-as-a-Service (import 2-3 data sources)
- • Set up monitoring and alerting systems
Expected Results:
- • Basic capabilities ready
- • Cost: $10-20K
- • Team: 2-3 people
Phase 2: First Use Cases (Week 3-4)
Task List:
- • Select 2-3 high-value, low-risk use cases
- • Product team self-development (L1 level)
- • AI team provides guidance (L2 level)
Expected Results:
- • First features live
- • Development time: 2-5 days per feature
- • Adoption rate target: >50%
Phase 3: Expansion & Optimization (Week 5-6)
Task List:
- • Expand to 8-10 use cases
- • Start L3 level co-development (innovative features)
- • Collect feedback, optimize platform
Expected Results:
- • Cover 70% of common needs
- • Development efficiency: 3-4x
- • Cost savings: >50%
Frequently Asked Questions
Q1: How much budget is needed?
A: According to Curify AI's experience, mid-sized tech companies' initial investment range:
| Scale | Team Size | Monthly Budget | First Year Budget |
|---|---|---|---|
| Small | 50-200 people | $15-30K | $180-360K |
| Medium | 200-500 people | $30-60K | $360-720K |
| Large | 500-1000 people | $60-120K | $720-1440K |
Q2: How many ML engineers need to be hired?
A: This is the most common misconception. Our three-tier model supports:
- • Core AI team: 3-5 people (responsible for platform and complex use cases)
- • Product engineers: 20-50 people (self-develop features, no ML background needed)
- • Business experts: 10-30 people (provide domain knowledge and feedback)
Q3: How is data security ensured?
A: Three-layer security guarantee:
- • Technical layer: End-to-end encryption, zero-trust security, PII detection
- • Process layer: Audit trails, access control, data classification
- • Compliance layer: GDPR, SOC 2, HIPAA certification
Q4: How to measure success?
A: Key metrics:
- • Development efficiency: Feature deployment cycle (target: <2 weeks)
- • Adoption rate: Team usage proportion (target: >70%)
- • Cost savings: Compared to outsourcing or traditional methods (target: >50%)
- • User satisfaction: NPS (target: >50)
Q5: What scenarios are not applicable?
A: This platform strategy is not applicable to:
- • Ultra-large companies (>5000 people): need more complex governance
- • Ultra-low latency scenarios (<100ms): need specialized optimization
- • 100% local deployment: need completely custom architecture
Conclusion
For mid-sized tech companies, the path to AI victory doesn't lie in building better large language models, but in building a platform that transforms AI into repeatable, scalable business processes.
According to BCG Boston Consulting's 2024 research, mid-sized tech companies successfully implementing AI platforms have 32% higher customer lifetime value (CLV) than peers, 28% lower operating costs, and 2.5x faster innovation speed.
Start with infrastructure, ensure data security, then let your teams start building. The future isn't one model ruling everything, but a fleet of specialized agents, each solving a real business problem, powered by a platform that makes it all simple.
Keep it simple, keep it open, focus on empowering others.
Take the next step
Putting what you read into practice.
Related Articles
DS & AI Engineering
From Probabilistic to Deterministic: Hard Truths About AI Engineering in Production
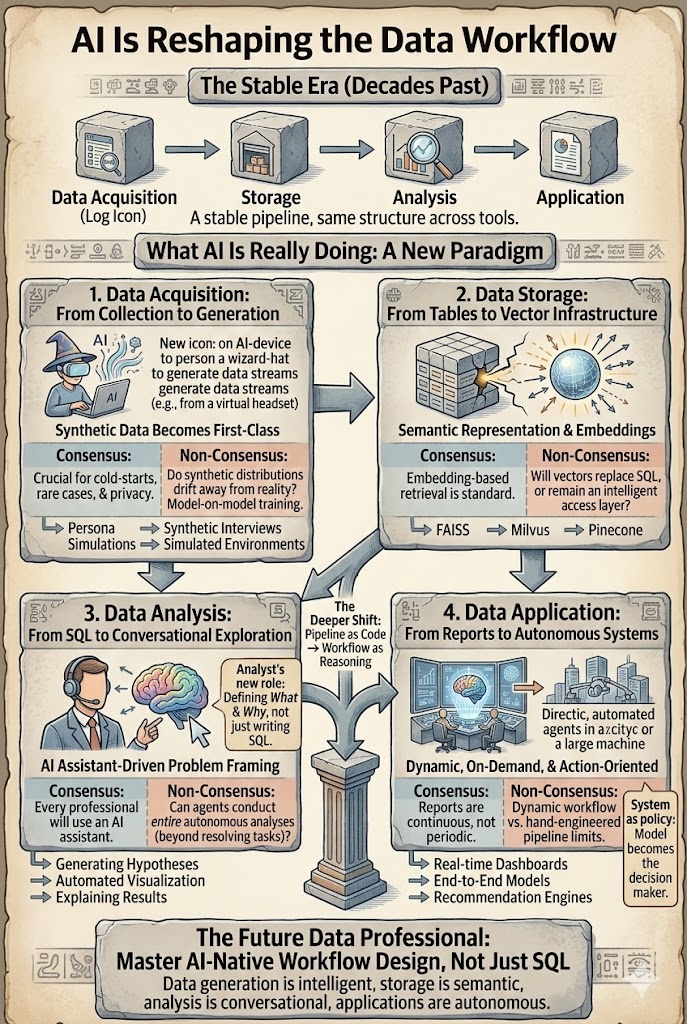
AI Is Reshaping the Data Workflow: From Assistant to Agent