2026年最佳AI语音克隆工具:ElevenLabs与F5-TTS与OpenVoice
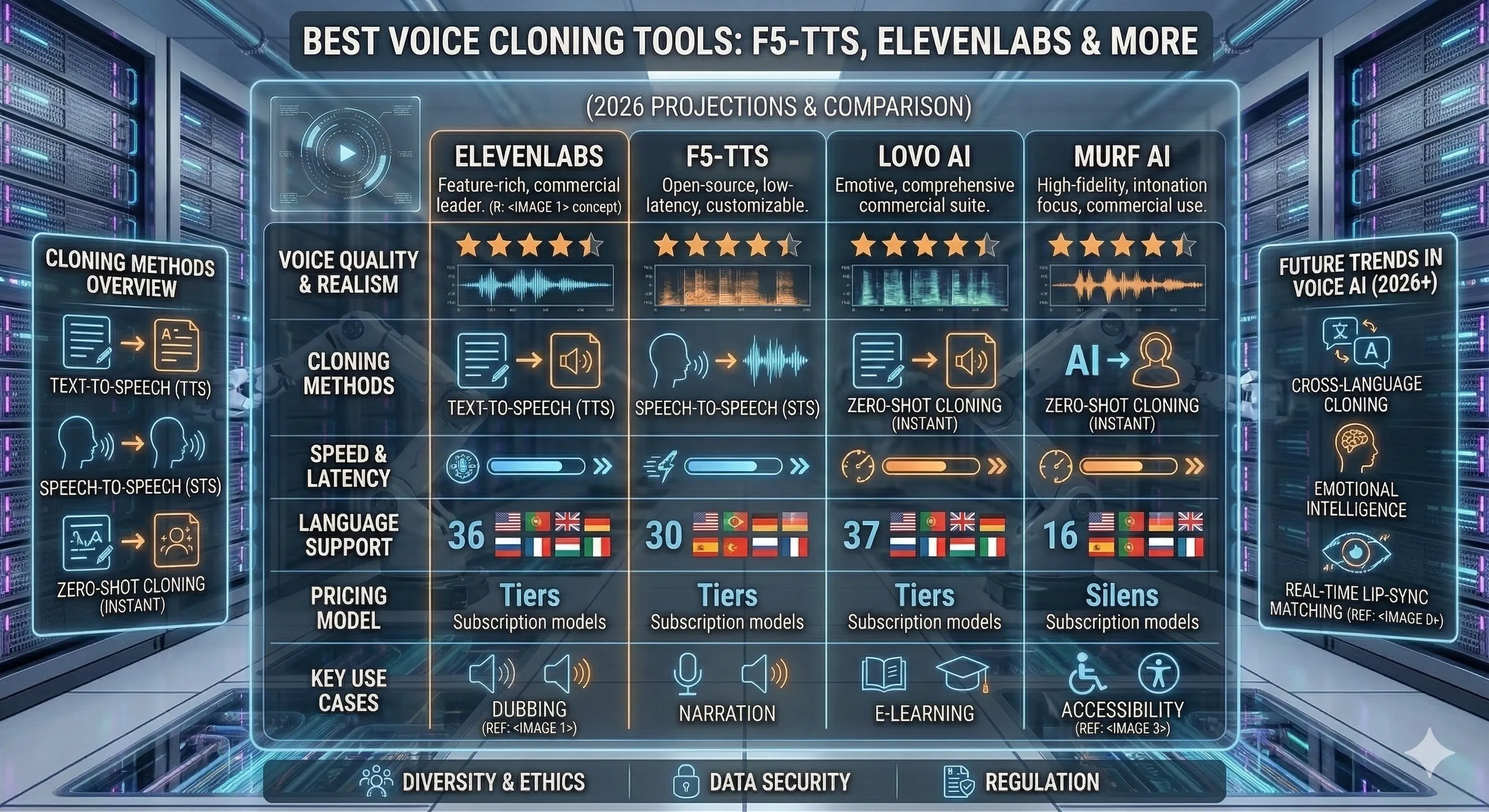
大多数关于这个主题的文章都会列出10个以上的工具排名。这并没有帮助——三个工具几乎涵盖了所有实际用例,它们之间的差异很明显。本指南挑选了这三款工具,说明每款工具的最佳用途,并标出一个常见的用例(将视频配音成另一种语言,同时保留你的声音),在这种情况下你根本不需要语音克隆工具。
适合谁
创作者选择工具来克隆他们自己的声音用于旁白、有声书或自定义TTS功能。产品团队在SaaS中推出语音克隆功能。本地化团队考虑开源与商业。如果你想用自己的声音将YouTube视频本地化为另一种语言,请跳到如果你不需要语音克隆工具怎么办?的提示——那是一个不同的问题和不同的工具。
快速购买指南 — 实际上什么才重要
四个维度很重要;其余的都是营销文案。
1. 同意与合法性(首要规则)。 在没有明确书面同意的情况下克隆他人的声音是法律灾难 — GDPR在欧盟将声音视为生物识别数据;FCC的2024年裁决使其在美国的机器人电话中变得非法。像Descript和Resemble这样的工具在克隆之前会强制进行同意检查。像F5-TTS这样的工具则将政策留给你自行决定。请相应选择。
2. 定价模型。 按字符计费(ElevenLabs、AWS Polly、Azure)呈线性扩展 — 对于低量来说不错,但在大规模时会很痛苦。订阅计划限制你的支出。开源自托管(F5-TTS、OpenVoice)则用美元换取GPU成本 + 工程时间。
3. 声音保真度与样本长度。 “即时”克隆需要10-30秒的参考音频,提供70-80%的保真度。“专业”克隆需要30分钟以上的干净录音室音频,达到95%以上。选择与你的用例相匹配的级别 — 播客介绍需要比内部工具更高的保真度。
4. 音频存储位置。 一些供应商授予自己使用你上传的声音进行模型研发的“永久许可”。请阅读隐私政策。如果你不能让你的声音数据离开你的基础设施,请自托管F5-TTS或OpenVoice。
我们如何选择这三款工具
大多数“最佳语音克隆工具”列表有15个条目,因为填充有助于SEO。我们不同意。三个类别几乎涵盖了所有实际用例 — 商业抛光、开源自托管和轻量级开源替代品。我们剔除了12个与这三者重叠的工具(Murf、Play.ht、Speechify、Lovo、Listnr、TTSMaker等都与ElevenLabs在同一商业抛光类别中;Fish Audio、Hume、Respeecher则针对电影/共情细分市场)。如果你想要长列表,那就在谷歌搜索中找。如果你想要决策,请继续阅读。
值得比较的三款工具
除了营销文案,语音克隆领域分为三个类别:精致的商业领导者(ElevenLabs)、开源的工作马(F5-TTS)和当F5-TTS不适合时的轻量级开源替代品(OpenVoice)。每个工具都有不同的受众。选择一个符合你限制条件的工具。

1. ElevenLabs
精致语音克隆的商业领导者
- Best for: 产品、自定义声音、有声书、IVR、媒体角色声音
- Pricing: 按字符计费——免费层有限;付费计划起价约为5美元/月
- Languages: 30多种语言,拥有成熟的语音库
- Notable limitation: 封闭平台,语音克隆有内容政策限制(自定义声音需验证同意);高容量时按字符费用累积
当你需要一款语音克隆工具,且希望减少工程障碍并获得最高基准保真度,并且你能接受供应商锁定时,选择ElevenLabs。该API和语音库在该类别中最为成熟。如果你正在构建一个产品功能,让用户克隆自己的声音,这是最简单的路径。
2. F5-TTS
开源工作马,零-shot多语言
- Best for: 自托管语音克隆、技术团队、自定义推理、批量生成
- Pricing: 免费(自托管)——GPU成本是底线
- Languages: 多语言零-shot迁移;社区微调低资源语言
- Notable limitation: 需要GPU和推理基础设施;长片段(>30-45秒)时音调可能漂移;表现极端(大笑、喊叫)会减弱
当你有工程资源,想要在大规模下实现零成本每片段经济,或需要数据驻留/自托管以满足合规要求时,选择F5-TTS。该模型使用流匹配与扩散变换器——一旦你调整步骤和精度,输出与商业产品竞争。参考库:SWivid/F5-TTS;2025年论文在OpenReview。
3. OpenVoice
轻量级开源替代品,MIT许可证
- Best for: 单个剪辑克隆,低资源环境,宽松许可
- Pricing: 免费(MIT许可证,自托管)
- Languages: 开箱即用的4种以上语言;跨语言的声音风格转移
- Notable limitation: 声音保真度低于商业领导者;低资源模型,因此F5-TTS暴露的微调杠杆较少
当F5-TTS不符合您的限制时选择OpenVoice——您想要一个在较弱硬件上运行的小模型,更宽松的商业使用许可,或更简单的API。保真度的权衡是现实的,但对于非关键使用案例(粗略草稿、内部工具、可访问性原型)是可以管理的。
并排比较
三个工具的相同四个维度。阅读每个工具的框后,使用此信息进行三角测量。
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | 产品、自定义声音、有声书、IVR、媒体角色声音 | 自托管语音克隆、技术团队、自定义推理、批量生成 | 单个剪辑克隆,低资源环境,宽松许可 |
| Pricing | 按字符计费——免费层有限;付费计划起价约为5美元/月 | 免费(自托管)——GPU成本是底线 | 免费(MIT许可证,自托管) |
| Languages | 30多种语言,拥有成熟的语音库 | 多语言零-shot迁移;社区微调低资源语言 | 开箱即用的4种以上语言;跨语言的声音风格转移 |
| Limitation | 封闭平台,语音克隆有内容政策限制(自定义声音需验证同意);高容量时按字符费用累积 | 需要GPU和推理基础设施;长片段(>30-45秒)时音调可能漂移;表现极端(大笑、喊叫)会减弱 | 声音保真度低于商业领导者;低资源模型,因此F5-TTS暴露的微调杠杆较少 |
哪个适合哪个用例
- SaaS功能、有声书或IVR的自定义声音 → ElevenLabs。成熟、精致,工程表面低。
- 大规模语音克隆,自托管 → F5-TTS。每个剪辑免费,完全控制,GPU是底线。
- 需要低资源环境或宽松许可 → OpenVoice。更轻的模型,MIT。
- 将视频本地化为另一种语言,同时保留说话者的声音 → 跳过这三个。阅读下一部分。
如果您不需要语音克隆*工具*怎么办?
大多数访问“最佳语音克隆工具”的读者实际上是在尝试解决一个特定问题:让视频在另一种语言中听起来像原始说话者。如果您是这样,您不需要语音克隆工具——您需要一个内部使用语音克隆的配音工具。
Curify视频配音从源视频中克隆原始说话者的声音,翻译音频,将其与源时间对齐,并在目标语言中发布保留说话者身份的配音轨道。语音克隆是隐形的——上传视频,选择语言,获取配音。该流程基于上述相同的F5-TTS血统;不同之处在于我们处理对齐、口型同步和字幕生成,因此您不必自己组装这些部分。
何时适合: 本地化YouTube视频、课程模块、产品演示、网络研讨会、教程。
何时不适合: 为TTS API、IVR、有声书叙述或用户克隆自己声音的SaaS功能克隆声音——对于这些,继续使用上面的ElevenLabs或F5-TTS。不同类别,不同工具。
克隆声音前需了解的合规事项
这不是法律建议——请咨询你所在司法管辖区的律师。也就是说,三项可辩护的做法随处可见:
- 同意和权利。 从声音拥有者那里获得明确的书面同意。记录参考音频的来源。在某些美国州,宣传权在死亡后仍然存在;律师可以为你提供相关信息。
- 披露。 在平台或司法管辖区要求的地方标记合成或有意义改变的声音。YouTube在上传时提供了披露路径——请使用它。
- 电话谨慎。 美国FCC的2024年声明性裁定规定,在没有事先明确同意的情况下,AI生成的声音在自动拨号中是非法的。如果你的用例涉及电话,这将是一个障碍。
常见问题
2026年AI语音克隆合法吗?
这是一个管辖权的拼凑。美国:没有针对语音克隆的联邦法律,但州的公开权利法在非自愿使用时生效;FCC的2024年裁决使AI语音在机器人电话中变得非法。欧盟:GDPR将声音视为生物识别数据 — 需要明确同意,并且你必须披露模型训练的使用。始终从声音所有者那里获得明确的书面同意,记录下来,并在平台要求的地方标记合成内容(YouTube、TikTok)。
克隆一个声音需要多少音频?
取决于级别。即时克隆(ElevenLabs Instant、OpenVoice)需要10-30秒的参考音频,提供70-80%的保真度。专业克隆(ElevenLabs Professional、F5-TTS微调)需要30分钟以上的干净录音室音频,达到95%以上的保真度。如果你是为了播客介绍克隆自己的声音,即时级别就可以。如果你要发布产品功能,请选择专业级别。
我可以为个人项目克隆名人的声音吗?
不可以。每个信誉良好的平台(ElevenLabs、Resemble、Respeecher)在其服务条款中禁止这样做。这违反了大多数美国州的公开权利法和许多管辖区的版权。即使你自托管一个开源模型,分发名人克隆的输出也是可追责的。不要这样做。
语音克隆和文本转语音(TTS)有什么区别?
TTS使用预先存在的声音(通常是经过筛选的库存声音)将书面文本转换为语音。语音克隆生成特定人的声音,捕捉自参考样本。大多数现代平台(ElevenLabs、F5-TTS)同时具备这两种功能 — 它们是具有克隆功能的TTS引擎。“语音克隆工具”通常意味着“我用来克隆声音的TTS引擎”。
什么是语音到语音(STS)?
不同的机制:你录制自己表演的一段台词(带有你的语调、节奏、情感),工具将你的表演映射到不同的目标声音上。对于配音很有用,因为你希望配音的声音继承原演员的情感表达。Respeecher专注于此;ElevenLabs等也将其作为一项功能。这与直接的语音克隆是不同的问题。
我只想用自己的声音为YouTube视频配音。哪个工具?
以上三个工具单独使用都不行 — 你需要组装一个流程。你需要:(1)提取原始音频,(2)克隆说话者的声音,(3)翻译脚本,(4)在克隆的声音中生成配音音频,(5)将其与源视频的时间对齐,(6)可选地进行口型同步。Curify视频配音完成所有六个步骤。语音克隆是内部的;你上传一个视频,选择一种语言,得到一个配音。这与“语音克隆工具”是不同的类别。
简短版本
三款工具,一个决定:ElevenLabs如果你正在推出产品并希望有精致的效果和较低的工程难度;F5-TTS如果你有GPU并希望在大规模下每个片段零成本;OpenVoice如果你需要一个许可宽松的轻量级模型。如果你真正的问题是用你自己的声音为视频配音,试试Curify——语音克隆是自动的,你不需要学习上述三款工具中的任何一款。
Take the next step
Putting what you read into practice.

