Yapay Zeka Veri İş Akışını Yeniden Şekillendiriyor: Asistanlıktan Ajanlığa
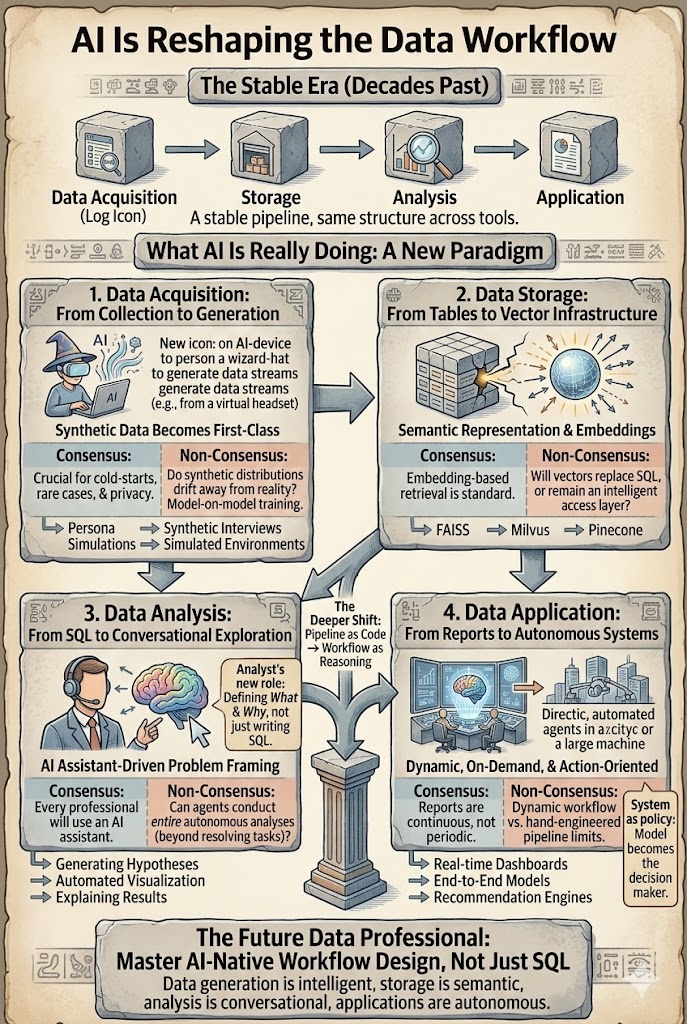
Veri iş akışı son on yılda oldukça istikrarlıydı. İster bir veri bilimcisi, ister analist, ister öneri mühendisi olun, boru hattı kabaca aynı görünüyordu: edinim → depolama → analiz → uygulama. Yapay zeka bu iş akışını sadece hızlandırmakla kalmıyor, aynı zamanda her katmanını yeniden şekillendirmeye başlıyor. Gerçek soru artık yapay zekanın veri işini değiştirip değiştirmeyeceği değil, hangi kısımların açıkça değiştiği ve hangi varsayımların yanlış çıkacağıdır.
Veri İş Akışının Dört Katmanı
Farklı araçlar, farklı endüstriler — ama temelde aynı dört adımlı yapı: veri üretmek veya toplamak, depolamak, analiz etmek, içgörü uygulamak. Bu boru hattı, şekil olarak nispeten az değişiklikle on yıl boyunca arama, reklam ve öneri sistemlerini destekledi. Değişen şey, her katmanın artık büyük modeller ve ajanlar tarafından yeniden şekillendirilme derinliğidir. Aşağıdaki bölümler her katmanı ele alır ve konsensüsü (açıkça değişen) tartışmasız olanlardan (hala tartışmaya açık olan) ayırır.
Her Katman Nasıl Değişiyor
1. Veri Edinimi — Sentetik Veri Birinci Sınıf Bir Kaynak Oluyor
Geleneksel olarak, faydalı veriler gerçek dünyadan geliyordu: günlükler, işlemler, sensörler, anketler. Bu varsayım kırılmaya başlıyor. Artık daha fazla veri, kişilik simülasyonları, davranış modelleme, sentetik görüşmeler, A/B testi veri üretimi ve pekiştirme öğrenimi eğitimi ve değerlendirmesi için kullanılan simüle edilmiş ortamlar aracılığıyla üretiliyor.
Konsensüs: Sentetik veriler, özellikle soğuk başlangıç problemlerinde, nadir senaryolarda ve gizlilik kısıtlı ortamlarda gerçek dünya verilerini giderek daha fazla tamamlayacak.
Tartışmasız: Modeller giderek diğer modeller tarafından üretilen verilerle eğitildiğinde ne olacak? Sentetik dağılımlar yavaş yavaş gerçeklikten uzaklaşacak mı ve geri bildirim döngüleri oluşturacak mı?
Veri edinimi *toplamadan* *üretim + kalibrasyona* kayıyor.
2. Veri Depolama — Tablolardan Vektör Altyapısına
Geleneksel veri sistemleri yapılandırılmış depolama etrafında inşa edilmişti: ilişkisel veritabanları, depolar ve sütun mağazaları. Yapay zeka yeni bir katman getiriyor — vektör temsilleri. Metin, görüntüler, videolar, kullanıcı davranış yolları ve bilgi parçaları giderek daha fazla, anlamsal arama, geri alma artırılmış üretim ve çok modlu akıl yürütmeyi destekleyen gömme olarak depolanıyor. FAISS, Milvus ve Pinecone gibi vektör veritabanları temel altyapı haline geliyor.
Konsensüs: Gömme tabanlı geri alma artık standart bir tasarım kalıbı. RAG, özel verilerde LLM'leri temellendirmek için varsayılan mimaridir.
Tartışmasız: Vektörler nihayetinde geleneksel depolama katmanlarını mı değiştirecek? Yoksa ham verilerin üstünde bir indeksleme katmanı olarak mı kalacaklar? Vektörlerin birincil depolama haline gelmesi için gömme verilerden orijinal verileri yeterince iyi yeniden yapılandırabilir miyiz?
Şu anda, gömmeler daha az depolama işlevi görüyor ve daha çok zeki erişim katmanı olarak işlev görüyor. Ancak bu katman, verilerin erişim şeklini zaten yeniden şekillendirdi.
3. Veri Analizi — SQL'den Konuşma Tabanlı Keşfe
Analiz katmanı en hızlı değişiyor. Geleneksel iş akışı şöyle görünüyordu:
problem tanımı → SQL → özellik mühendisliği → modelleme → yorumlama
Bugün, yapay zeka sistemleri neredeyse her adımda yardımcı olabilir: LLM'ler otomatik olarak SQL oluşturur, hipotezler önerir, görselleştirmeler oluşturur, temel modeller inşa eder ve sonuçları açıklar. Analistin rolü *Sorgu Yazarı* olmaktan *Problem Çerçeveleyici ve Doğrulayıcı* olmaya kayıyor.
Konsensüs: Her veri profesyoneli yakında bir yapay zeka asistanıyla çalışacak. Copilotlar ve sohbet tabanlı analiz standart hale geliyor.
Tartışmasız: Ajanlar nihayetinde tüm analizleri baştan sona gerçekleştirecek mi? Müşteri desteklerinde, ajanlar zaten biletlerin %80'ini yönetebiliyor. Veri analizi daha zor — sorular genellikle belirsizdir ve hedefler soruşturma sırasında değişir. Otomasyon yürütmeyi hızlandıracak, ancak insanlar muhtemelen problemi çerçevelemekten sorumlu kalacak.
4. Veri Uygulaması — Raporlardan Otonom Sistemlere
Son aşama — içgörüleri uygulamak — iki cephede evrim geçiriyor.
Raporlar. Yapay zeka zaten raporlamayı dönüştürüyor: otomatik özetler, grafikler, panolar ve metin, görüntü ve video üzerinden sunumlar. Daha derin değişim, raporların artık periyodik olmasına gerek olmamasıdır. Sürekli ve talep üzerine üretilebilirler. Gerçek verimlilik kazancı "daha hızlı yazmak" değil, "soru sorulduğunda mevcut olan raporlar"dır.
Otonom sistemler. Öneri, arama, reklam ve otonom sürüş, el ile mühendislik yapılmış modüler boru hatlarından, modelin kendisinin karar politikası haline geldiği uçtan uca modellere doğru kayıyor. Değişim, *özellik tüketicisinden* *strateji üreticisine* geçiştir.
Asistan vs Ajan — Konsensüs ve Tartışmasız
Ortaya çıkan bir konsensüs: asistanlar ve ajanlar uzun vadede bir arada var olacak. Ancak denge alanlara göre keskin bir şekilde farklılık gösteriyor.
| Alan | Asistan payı | Ajan payı |
|---|---|---|
| Müşteri desteği | %20 | %80 |
| Veri analizi | %70 | %30 (belirsiz) |
| Öneri politikası optimizasyonu | %50 | %50 |
| Otonom sürüş | %10 | %90 |
Ana belirsizlik veri analizidir. Problemin tanımının en zor kısım olduğu alanlarda, ajanlar döngüyü kapatmakta zorlanıyor. En olası sonuç: analiz asistan ağırlıklı kalacak, ancak yürütme yüksek derecede otomatikleşecek. İnsanlar çerçeveleme yapar; ajanlar keşfeder.
Daha derin değişim, daha hızlı SQL veya daha iyi panolar değil. İş akışını kimin kontrol ettiğidir. *Kod Olarak Boru Hattı*'ndan *Akıl Yürütme Olarak İş Akışı*'na geçiyoruz — önceden tanımlanmış adımları yürütmekten, eylemleri planlayan, hipotezleri keşfeden ve yineleyen sistemlere.
Tools & Resources
Learn about the best tools available...
Curify Bu Değişimde Nerede Yer Alıyor
Curify, *Akıl Yürütme Olarak İş Akışı* kalıbı etrafında inşa edilmiştir. Bugün platformda üç somut örnek:
- İçerik üretimi iş akışı olarak, tek seferlik değil. /nano-template kütüphanesi, istem → görüntü üretimi → varyant etiketleme → CDN senkronizasyonu zincirini oluşturan 172 parametreli şablondan oluşur — bir üretim iş akışı, tek seferlik bir istem değil.
- Galeri katmanında gömme destekli erişim. /nano-banana-pro-prompts 4,000+ istemin etiket, konu ve anlamsal benzerlik ile aranabilir olduğu bir koleksiyondur — vektör katmanı erişim yolu, ham JSON ise gerçeklik kaynağıdır.
- Ses + video transkripsiyonu yukarı akış girişi olarak. /tools/video-transcript-generator konuşmacı etiketli transkriptler üretir ve bunlar /tools/video-dubbing ve /tools/translate-subtitles ile akışa girer — bir girdinin üç yerelleştirilmiş çıktıyı yönlendirdiği bir iş akışı.
Veri Profesyonelleri İçin Gerçek Soru
Geleneksel veri iş akışı yok olmuyor. Ancak evrim geçiriyor: veri üretimi daha akıllı hale geliyor, depolama daha anlamsal hale geliyor, analiz daha konuşma tabanlı hale geliyor, uygulamalar daha otonom hale geliyor.
Daha radikal bir tartışmasız görüş: gelecekteki veri sistemleri ikiye ayrılabilir — insan tarafından yorumlanabilir analiz sistemleri (dünyayı anlamak için) ve kara kutu optimizasyon sistemleri (sonuçları optimize etmek için). İkisi ayrıldığında, veri profesyonelleri yok olmaz; veri operatörleri yerine *strateji yorumlayıcıları* haline gelirler.
Bugün herhangi bir veri profesyoneli için gerçek soru artık "SQL yazabilir misin" değil. O, yapay zeka yerel iş akışları tasarlayabilir misin?
Take the next step
Putting what you read into practice.
İlgili Makaleler
DS & AI Engineering
Olasılıksaldan Belirleyiciye: Üretimde AI Mühendisliği Hakkında Sert Gerçekler
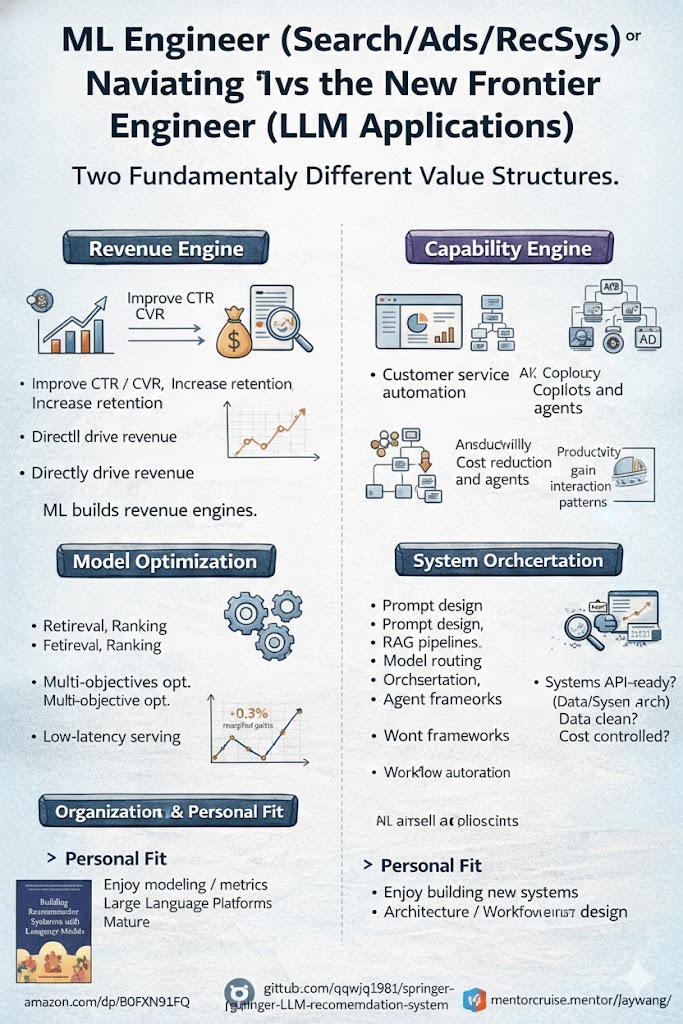
ML Mühendisi mi Yoksa AI Mühendisi mi? İki Kariyer Yolu, İki Değer Yapısı