ИИ изменяет рабочий процесс с данными: от помощника к агенту
Рабочий процесс с данными оставался удивительно стабильным на протяжении десятилетия. Независимо от того, являетесь ли вы дата-сайентистом, аналитиком или инженером по рекомендациям, процесс выглядел примерно одинаково: приобретение → хранение → анализ → применение. ИИ не просто ускоряет этот процесс — он начинает изменять каждый его уровень. Реальный вопрос больше не в том, изменит ли ИИ работу с данными. Вопрос в том, какие части явно меняются, и какие предположения окажутся неверными.
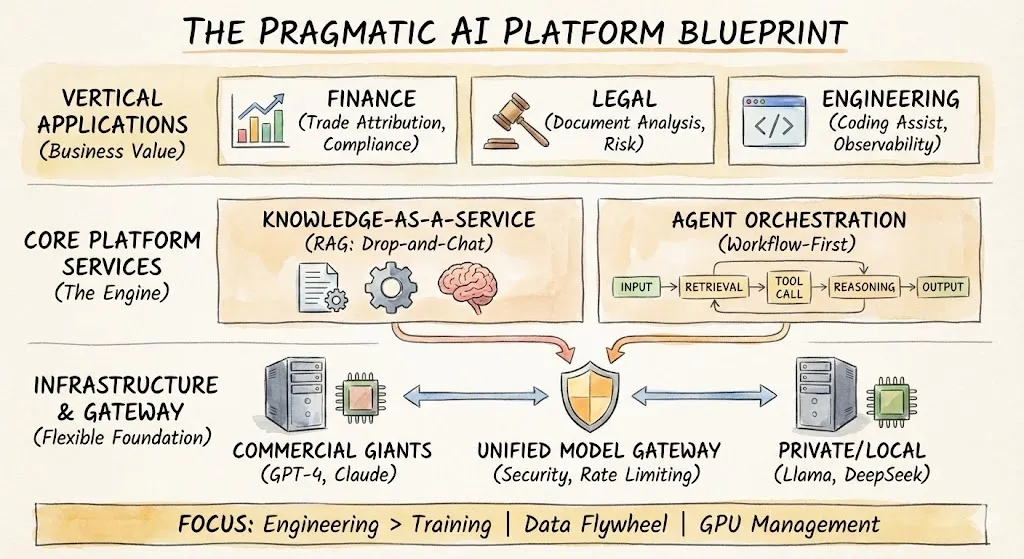
Четыре уровня рабочего процесса с данными
Разные инструменты, разные отрасли — но в основном одна и та же четырехступенчатая структура: генерировать или собирать данные, хранить их, анализировать, применять полученные знания. Этот процесс обеспечивал десять лет поиска, рекламы и систем рекомендаций с относительно небольшими изменениями в структуре. Что изменилось, так это глубина, на которой каждый уровень теперь изменяется большими моделями и агентами. В следующих разделах рассматривается каждый уровень и отделяется консенсус (что явно меняется) от неконсенсуса (что все еще подлежит обсуждению).
Как меняется каждый уровень
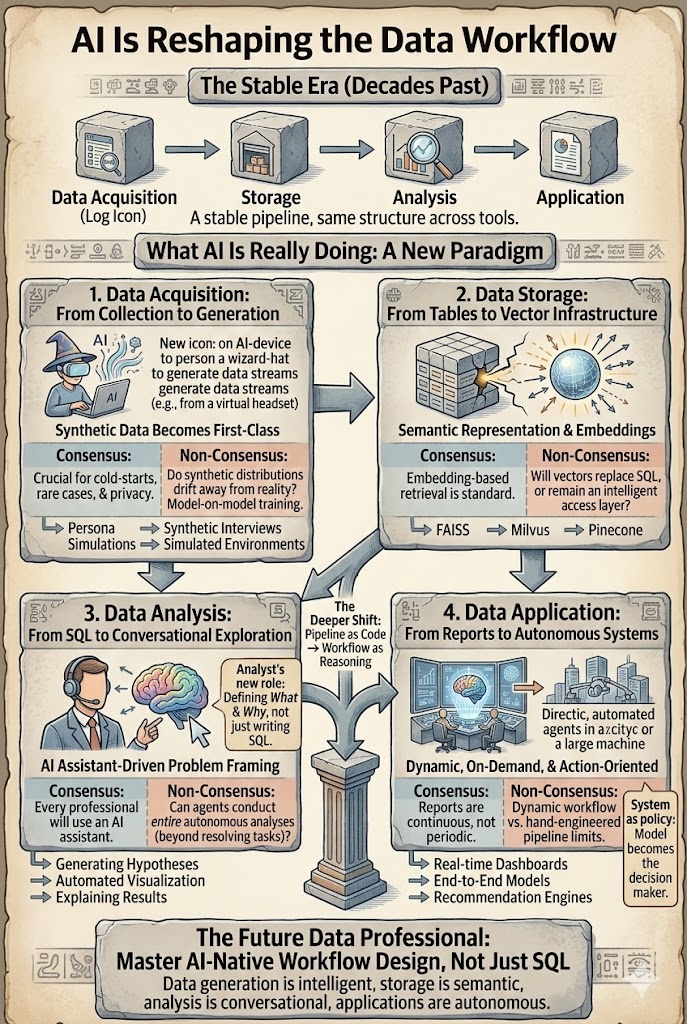
1. Приобретение данных — синтетические данные становятся первоклассным источником
Традиционно полезные данные поступали из реального мира: журналы, транзакции, датчики, опросы. Это предположение начинает рушиться. Все больше данных теперь генерируется, а не собирается — через симуляции персонажей, моделирование поведения, синтетические интервью, генерацию данных A/B-тестов и смоделированные среды, используемые для обучения и оценки с подкреплением.
Консенсус: Синтетические данные будут все больше дополнять реальные данные, особенно в проблемах холодного старта, редких сценариях и средах с ограничениями по конфиденциальности.
Неконсенсус: Что произойдет, когда модели все больше будут обучаться на данных, произведенных другими моделями? Будут ли синтетические распределения медленно отклоняться от реальности и образовывать замкнутые циклы?
Приобретение данных смещается от *сбора* к *генерации + калибровке*.
2. Хранение данных — от таблиц к векторной инфраструктуре
Традиционные системы данных строились вокруг структурированного хранения: реляционные базы данных, хранилища и колоночные хранилища. ИИ вводит новый уровень — векторные представления. Текст, изображения, видео, траектории поведения пользователей и фрагменты знаний все чаще хранятся в виде встраиваний, которые обеспечивают семантический поиск, генерацию с дополнением извлечения и многомодальное рассуждение. Векторные базы данных, такие как FAISS, Milvus и Pinecone, становятся основной инфраструктурой.
Консенсус: Извлечение на основе встраиваний теперь является стандартным шаблоном проектирования. RAG — это архитектура по умолчанию для привязки LLM к собственным данным.
Неконсенсус: Заменят ли векторы в конечном итоге традиционные уровни хранения? Или они останутся уровнем индексации поверх сырых данных? Можем ли мы достаточно хорошо восстановить оригинальные данные из встраиваний, чтобы векторы стали основным хранилищем?
Пока встраивания функционируют меньше как хранилище и больше как интеллектуальный уровень доступа. Но этот уровень уже изменил способ доступа к данным.
3. Анализ данных — от SQL к разговорному исследованию
Уровень анализа меняется быстрее всего. Традиционный рабочий процесс выглядел так:
определение проблемы → SQL → создание признаков → моделирование → интерпретация
Сегодня системы ИИ могут помочь на почти каждом этапе: LLM автоматически генерируют SQL, предлагают гипотезы, создают визуализации, строят базовые модели и объясняют результаты. Роль аналитика смещается от *автора запросов* к *формулировщику и валидатору проблем*.
Консенсус: Каждый специалист по данным вскоре будет работать с помощником ИИ. Копилоты и анализ на основе чата становятся стандартом.
Неконсенсус: Будут ли агенты в конечном итоге проводить полный анализ от начала до конца? В службе поддержки агенты уже могут обрабатывать 80% заявок. Анализ данных сложнее — сами вопросы часто неоднозначны, и цели меняются в процессе расследования. Автоматизация ускорит выполнение, но, вероятно, люди останутся ответственными за формулирование проблемы.
4. Применение данных — от отчетов к автономным системам
Последний этап — применение полученных знаний — развивается в двух направлениях.
Отчеты. ИИ уже трансформирует отчетность: автоматические резюме, диаграммы, панели и презентации по тексту, изображениям и видео. Более глубокий сдвиг заключается в том, что отчеты больше не нужно составлять периодически. Их можно генерировать непрерывно и по запросу. Реальная выгода в производительности заключается не в "быстром написании", а в "отчетах, которые существуют, когда задается вопрос."
Автономные системы. Рекомендации, поиск, реклама и автономное вождение переходят от ручных модульных процессов к моделям end-to-end, где сама модель становится политикой принятия решений. Сдвиг происходит от *потребителя признаков* к *генератору стратегий*.
Помощник против агента — консенсус и неконсенсус
Один из возникающих консенсусов: помощники и агенты будут сосуществовать в долгосрочной перспективе. Но баланс резко различается в разных областях.
| Область | Доля помощника | Доля агента |
|---|---|---|
| Поддержка клиентов | 20% | 80% |
| Анализ данных | 70% | 30% (неопределенно) |
| Оптимизация политики рекомендаций | 50% | 50% |
| Автономное вождение | 10% | 90% |
Ключевая неопределенность заключается в анализе данных. В областях, где определение проблемы является самой сложной частью, агентам трудно замкнуть цикл. Наиболее вероятный исход: анализ остается с преобладанием помощников, но выполнение становится высокоавтоматизированным. Люди формулируют; агенты исследуют.
Более глубокий сдвиг заключается не в более быстром SQL или лучших панелях. Это кто контролирует рабочий процесс. Мы переходим от *Pipeline as Code* к *Workflow as Reasoning* — от выполнения предопределенных шагов к системам, которые планируют действия, исследуют гипотезы и итерации.
Tools & Resources
Learn about the best tools available...
Где Curify вписывается в этот сдвиг
Curify построен вокруг шаблона *Workflow as Reasoning*. Три конкретных примера на платформе сегодня:
- Генерация контента как рабочий процесс, а не одноразовый запрос. Библиотека /nano-template содержит 172 параметризованных шаблона, которые связывают запрос → генерацию изображения → тегирование вариантов → синхронизацию CDN — рабочий процесс генерации, а не одноразовый запрос.
- Доступ на основе встраиваний на уровне галереи. Корпус /nano-banana-pro-prompts из более чем 4000 запросов можно искать по тегам, темам и семантическому сходству — векторный уровень является путем доступа, сырые JSON являются источником истины.
- Транскрипция аудио + видео как входные данные. /tools/video-transcript-generator выводит транскрипты с метками спикеров, которые поступают в /tools/video-dubbing и /tools/translate-subtitles — рабочий процесс, где один вход приводит к трем локализованным выходам.
Реальный вопрос для специалистов по данным
Традиционный рабочий процесс с данными не исчезает. Но он эволюционирует: генерация данных становится более интеллектуальной, хранение становится более семантическим, анализ становится более разговорным, приложения становятся более автономными.
Более радикальная точка зрения неконсенсуса: будущие системы данных могут разделиться на две — системы анализа, понятные человеку (для понимания мира) и системы оптимизации черного ящика (для оптимизации результатов). Когда две системы разделятся, специалисты по данным не исчезнут; они станут *интерпретаторами стратегий*, а не операторами данных.
Реальный вопрос для любого специалиста по данным сегодня больше не в том, "можете ли вы писать SQL." Это: можете ли вы разрабатывать рабочие процессы, ориентированные на ИИ?
Take the next step
Putting what you read into practice.
Связанные статьи
DS & AI Engineering
От вероятностного к детерминированному: жесткие истины о инженерии ИИ в производстве
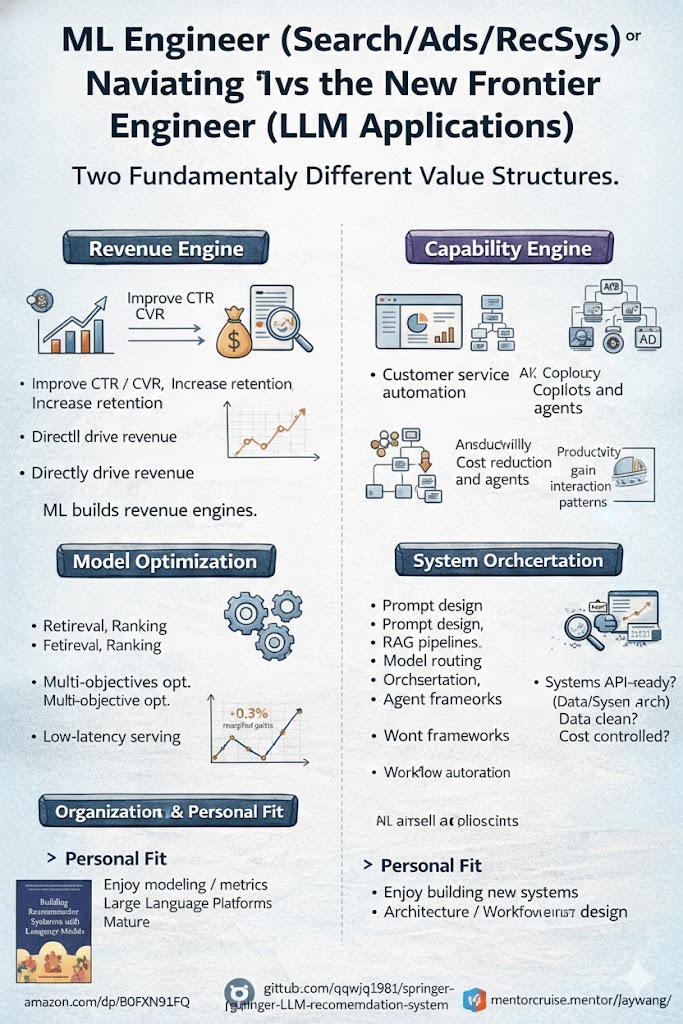
Инженер ML или инженер ИИ? Два карьерных пути, две структуры ценностей