확률적에서 결정론적으로: 생산에서 AI 엔지니어링에 대한 어려운 진실

2024-2025년에 생성적 AI를 시도한 대부분의 SMB 리더들은 같은 인상을 받았습니다: 슬롯 머신처럼 느껴진다는 것입니다. 데모는 마법 같았습니다. 생산 롤아웃은 동전 던지기와 같았습니다 — 한 번은 잘못된 JSON, 다음 번은 환각된 송장 번호, 세 번째는 $4,000의 월 청구서. 그들이 도달한 결론은 합리적이지만 잘못된 것이었습니다: "AI는 아직 우리 비즈니스에 준비가 되어 있지 않다." 실제 결론은: 모델은 작동했습니다. 그 주위의 시스템은 작동하지 않았습니다. AI 엔지니어링 — 확률적 모델을 결정론적 시스템으로 전환하는 학문 — 이 그 격차를 메우는 것이며, 대부분의 SMB 파일럿은 이를 갖추지 못했습니다.
왜 AI 파일럿이 슬롯 머신처럼 느껴지는가
대형 언어 모델은 본질적으로 확률 기계입니다. 같은 입력 프롬프트를 두 번 실행하면 두 개의 다른 출력을 생성할 수 있습니다. 이는 버그가 아닙니다 — 모델을 창의적이고 유용하게 만드는 것입니다. 하지만 이는 또한 단순한 통합이 반복적으로 신뢰할 수 있는 비즈니스 프로세스에 적합하지 않게 만드는 이유이기도 합니다.
모든 SMB AI 파일럿에서 나타나는 다섯 가지 실패 모드는 예측 가능합니다:
- 잘못된 JSON 출력. 모델이 구조화된 응답을 반환하지만, 20번 호출 중 한 번은 다운스트림 파서를 깨뜨립니다. 파이프라인은 조용히 주문을 누락시키거나, 재고를 잘못 계산하거나, 승인 단계를 건너뜁니다.
- 환각. 모델이 존재하지 않는 고객 이름, 제품 SKU, 주문 날짜 또는 가격을 만들어냅니다. 챗봇에서는 짜증이 납니다. 자동 송장 발행이나 준수 단계에서는 비즈니스 리스크입니다.
- 추론 드리프트. 장기 실행 에이전트가 올바른 목표로 작업을 시작하지만 관련 없는 곳에서 끝납니다 — 맥락 창이 관련 없는 중간 출력으로 가득 차고 원래 목표가 사라집니다.
- 맥락 폭발. 2,000 토큰이 필요한 간단한 쿼리가 80,000으로 부풀어 오릅니다. 이전 모든 턴이 다시 전송되고 있기 때문입니다. 대기 시간이 3초에서 45초로 증가합니다.
- 비용 폭주. 파일럿은 10월에 $200로 작동했습니다. 12월에는 같은 워크플로우가 $4,000의 비용이 들었습니다. 트래픽이 20배 증가했지만 아무도 예산 경계를 설정하지 않았습니다.
이러한 문제는 더 나은 프롬프트를 작성한다고 해결되지 않습니다. 모델 주위에 엔지니어링을 통해 해결됩니다 — 신뢰할 수 없는 제3자 API를 처리하는 방법과 같습니다.
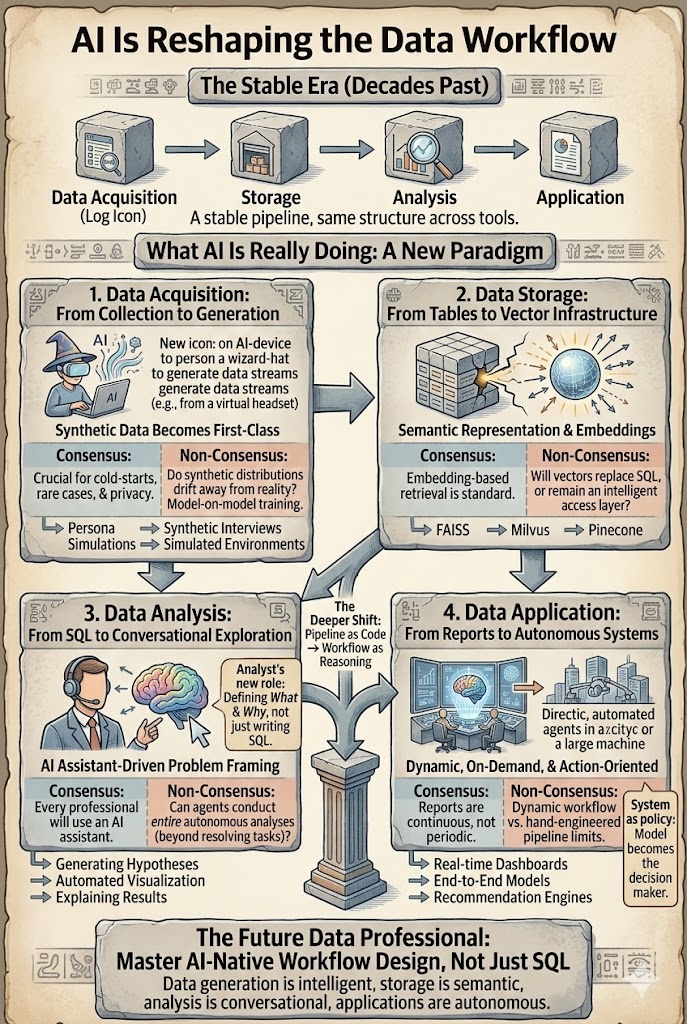
AI를 결정론적으로 만드는 네 가지 엔지니어링 레이어
1. 스키마 검증, 자동 복구 및 대체
첫 번째 방어선. 시스템 경계를 넘는 모든 모델 출력은 다운스트림에서 사용되기 전에 스키마에 대해 검증됩니다. 검증이 실패하면 — 정기적으로 실패합니다 — 시스템은 오류를 발생시키지 않습니다. 자동 복구 패스를 실행합니다 (작은 모델이 잘못된 JSON을 수정하고, 더 엄격한 프롬프트로 재시도하거나, 유효한 하위 집합을 추출합니다) 그리고 복구가 실패하면 결정론적 기본값으로 돌아갑니다.
SMB 소유자에게 이는 하루에 한 번 고객 메시지를 조용히 건너뛰는 챗봇과 모든 파싱 실패를 인간 검토 대기열로 표시하는 챗봇의 차이입니다. 모델 실패의 확률은 변하지 않습니다. 비즈니스 실패의 확률은 호출당 ~5%에서 <0.1%로 줄어듭니다.
2. 의미론적 캐싱 및 비용 제어
대부분의 AI 작업 부하는 많은 중복 작업을 포함합니다. 두 고객이 "귀하의 반품 정책은 무엇입니까"라는 질문을 약간 다른 단어로 합니다; 오늘날의 단순한 구현은 두 번의 모델 호출을 만듭니다. 의미론적 캐시 (최근 프롬프트에 대한 벡터 유사성 + 유사성이 임계값을 초과할 때 답변 재사용)는 이를 하나의 호출로 축소하여 사용자 경험을 변경하지 않고도 토큰 지출을 50-80% 줄입니다.
이를 하드한 테넌트별 토큰 예산, 기능별 속도 제한 및 저위험 쿼리를 위한 작은 모델 라우팅 규칙과 결합하면 비용 폭주 문제가 발생하지 않습니다. "AI가 너무 비쌌다"는 거의 항상 누락된 비용 제어 레이어 때문이지, 비싼 모델 때문이 아닙니다.
3. 상태 기반 오케스트레이션 및 체크포인트 복구
다단계 워크플로우 — 초안 생성 → 검토 → 형식 지정 → 게시 — 는 추론 드리프트와 맥락 폭발이 실제로 발생하는 곳입니다. 해결책은 워크플로우를 상태 기계처럼 다루는 것입니다: 각 단계는 명시적인 입력, 명시적인 출력 및 체크포인트를 가집니다. 단계 2가 성공한 후 단계 3이 실패하면 시스템은 전체 에이전트를 다시 시작하는 대신 단계 2의 출력에서 재개합니다.
이것이 30분 비디오 번역 파이프라인이 일시적인 API 타임아웃을 견디는 방법입니다: 이미 처리된 세그먼트는 처리된 상태로 유지되고, 실패한 세그먼트는 백오프와 함께 재시도되며, 사용자는 "재개됨"을 보고 "다시 시작됨"을 보지 않습니다.
4. 자동 평가 및 가시성
마지막 레이어는 대부분의 파일럿이 결코 도달하지 못하는 것입니다: 시스템이 시간이 지남에 따라 개선되고 있는지 악화되고 있는지를 아는 것입니다. 자동 평가 파이프라인은 모든 모델 출력을 중요한 차원에서 금본위 세트에 대해 점수화합니다 — 사실 정확성, 형식 준수, 비즈니스 정책 준수. 가시성은 대기 시간, 요청당 토큰 비용, 테넌트별 실패율 및 검증을 깨뜨린 실제 프롬프트를 캡처합니다.
이것이 없으면 모든 모델 변경은 추측입니다. 이것이 있으면 리더는 다음과 같이 대답할 수 있습니다: "지난주에 배포한 변경 사항이 환각을 줄였는가, 아니면 단지 더 빨라 보였는가?" 이 질문은 AI 프로그램이 복합적으로 발전하는 것과 정체되는 것의 차이입니다.
생산 AI 인터뷰(및 생산 실패)가 실제로 테스트하는 것
후보자나 공급자가 생산 AI 작업을 수행했는지 여부를 판단하는 유용한 신호가 있습니다. 진지한 팀이 묻는 질문은 프롬프트 기술에 관한 것이 아닙니다. 그들은:
- 모델이 세 번 연속으로 잘못된 JSON을 반환합니다 — 사용자에게 무슨 일이 발생합니까?
- 환각된 고객 이름이 잘못된 송장을 초래했습니다 — 시스템이 이를 전송하기 전에 어떻게 감지했습니까?
- 토큰 청구서가 20배 증가했습니다 — 누락된 레이어는 무엇이었고, 어떻게 이를 제한할 것입니까?
- 정책 변경 시 오래된 답변을 반환하지 않는 의미론적 캐시는 어떻게 구축합니까?
- 장기 실행 에이전트가 12단계 중 7단계에서 실패했습니다 — 처음부터 다시 시작합니까, 아니면 6단계에서 재개합니까?
- 에이전트의 출력이 프롬프트 변경 후 "더 나은 느낌"이 듭니다 — 실제로 개선되었는지 측정하는 방법은 무엇입니까?
"프롬프트를 조정하겠다"로 시작하는 답변은 단서입니다: 이 사람은 데모를 만들었지 시스템을 만들지 않았습니다. 스키마 검증, 대체 계층, 비용 경계, 체크포인팅 및 평가 하네스에서 시작하는 답변이 생산 AI의 모습입니다.
공급자나 채용 후보자를 평가하는 SMB 리더를 위해: 이 여섯 가지 질문을 직접 물어보십시오. 답변은 슬롯 머신을 사는 것인지 시스템을 사는 것인지 알려줍니다.
Tools & Resources
Learn about the best tools available...
Curify에서의 상황
이 레이어는 추상적이지 않습니다. Curify 콘텐츠 스택은 생산에서 모든 레이어를 실행합니다:
- 스키마 검증기로서의 템플릿 엔진. /nano-template 라이브러리는 모든 프롬프트가 입력 유형과 검증된 출력 구조를 가진 172개의 매개변수화된 템플릿입니다. 브랜드에 맞는 템플릿을 보내는 B2B 파트너는 매번 동일한 JSON 형태를 받습니다 — 모델은 자유 형식의 프롬프트를 보지 않으며, 사용자는 파싱 오류를 보지 않습니다.
- 체크포인트가 있는 다단계 파이프라인. /tools/video-dubbing는 음성 클론 → 전사 → 번역 → 립싱크 → CDN 업로드입니다. 각 단계는 체크포인트를 가집니다; 립싱크에서의 실패는 음성을 다시 클론하지 않습니다.
- 평가 루프에 의해 지원되는 의미론적 검색. /nano-banana-pro-prompts 코퍼스는 태그 + 주제 + 임베딩 유사성 검색 뒤에 4,000개 이상의 프롬프트를 제공합니다; 모든 쿼리는 실제 세트에 대해 점수화되며 검색 품질 문서는 주마다 상승을 추적합니다.
- 설계에 의한 비용 경계. 기능별 토큰 예산, 저위험 쿼리를 위한 작은 모델 라우팅 및 의미론적 캐시 레이어는 트래픽이 증가함에 따라 월간 추론 비용을 평탄하게 유지합니다.
패턴은 모든 SMB AI 배포가 필요로 하는 것과 동일합니다. 템플릿 엔진은 이를 시행하는 한 가지 방법일 뿐입니다 — 그러나 기본적인 원칙(스키마 우선, 체크포인트, 평가, 관찰)은 보편적입니다.
당신의 AI 파일럿이 슬롯 머신처럼 느껴졌다면, 당신은 AI 엔지니어가 없었습니다
생성적 AI는 소프트웨어가 할 수 있는 것에서 진정한 단계 변화입니다. 2024-2025년에 실패한 대부분의 SMB 파일럿은 모델이 나빠서 실패한 것이 아닙니다. 그들은 그 주위에 결정론적 시스템을 구축한 사람이 없어서 실패했습니다. 확률적 출력을 신뢰할 수 있는 비즈니스 프로세스로 전환하는 작업 — 스키마 검증, 대체 계층, 의미론적 캐싱, 비용 제어, 상태 기반 오케스트레이션, 자동 평가, 가시성 — 이 AI 엔지니어링이 실제로 무엇인지입니다.
AI가 "우리는 아직 준비가 되지 않았다"고 생각하고 떠난 SMB 소유자라면, 더 정확한 해석은: "엔지니어링 레이어 없이는 우리에게 적합하지 않다"입니다. 그 엔지니어링 레이어는 투자 가능하고, 반복 가능하며, 점점 더 잘 이해되고 있습니다. 향후 12개월 내에 이를 해결하는 기업은 최고의 프롬프트를 가진 기업이 아닐 것입니다. 그들은 모델 주위에 최고의 containment 시스템을 가진 기업이 될 것입니다.
AI는 매 분기마다 더 똑똑해집니다. 자신의 비즈니스에서 AI를 신뢰할 수 있게 만드는 리더는 귀중한 자산이 됩니다.
Take the next step
Putting what you read into practice.