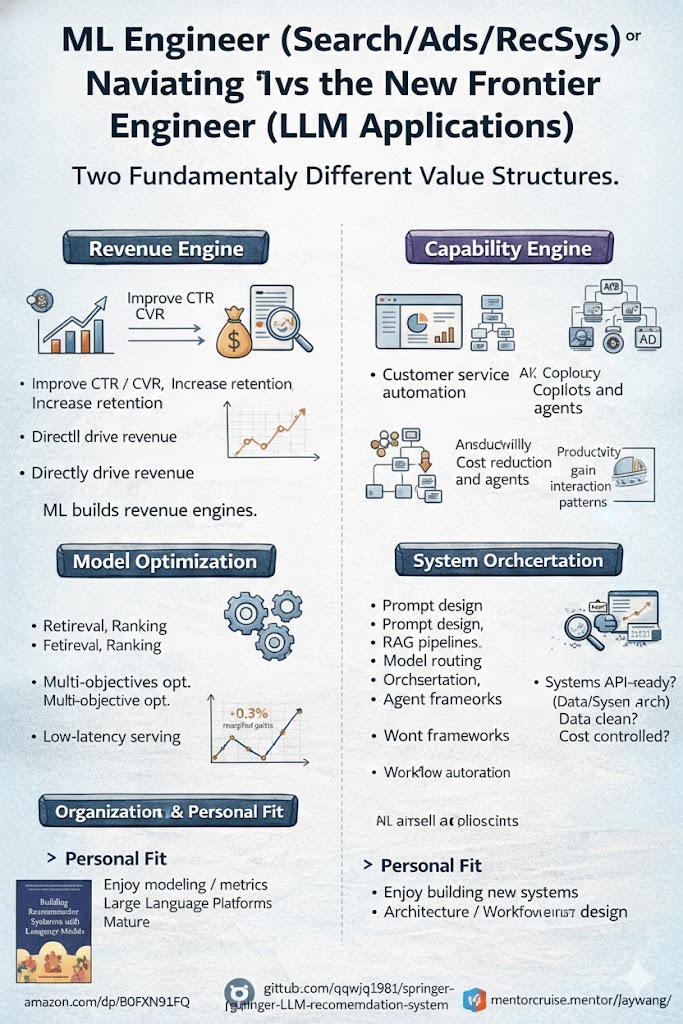
AI가 데이터 워크플로를 재편하고 있습니다: 어시스턴트에서 에이전트로
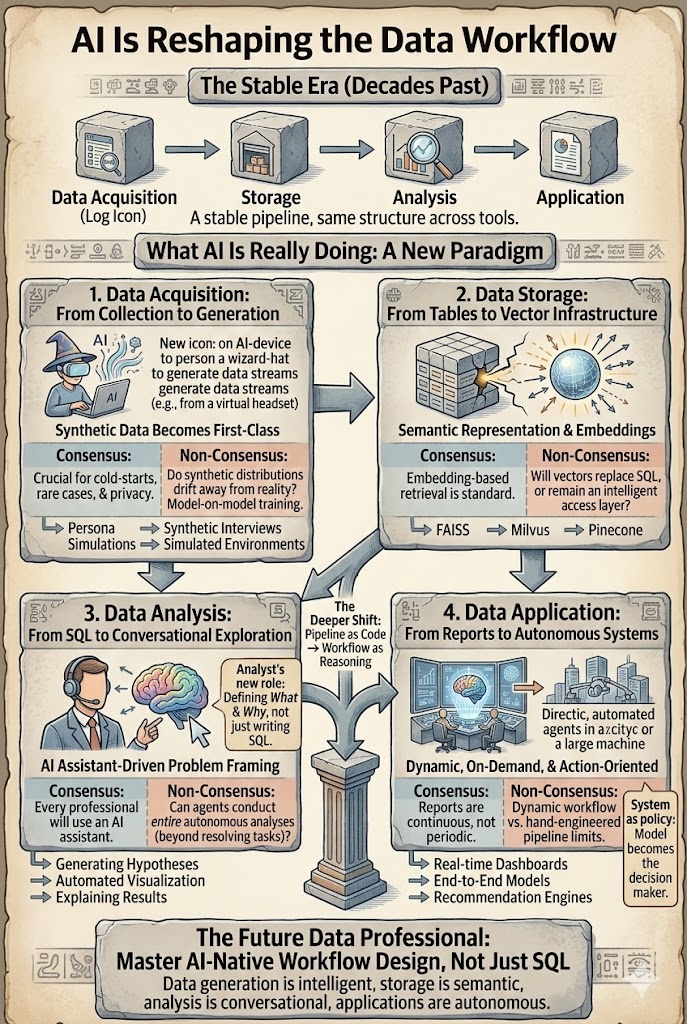
데이터 워크플로는 10년 동안 놀라울 정도로 안정적이었습니다. 데이터 과학자, 분석가 또는 추천 엔지니어이든, 파이프라인은 대략적으로 동일하게 유지되었습니다: 수집 → 저장 → 분석 → 적용. AI는 이 워크플로를 가속화할 뿐만 아니라 각 레이어를 재편하기 시작하고 있습니다. 이제 진짜 질문은 AI가 데이터 작업을 변화시킬 것인가가 아니라, 어떤 부분이 명확하게 변화하고 있으며, 어떤 가정이 잘못될 것인가입니다.
데이터 워크플로의 네 가지 레이어
다양한 도구, 다양한 산업 — 그러나 근본적으로 동일한 네 단계 구조: 데이터 생성 또는 수집, 저장, 분석, 통찰력 적용. 이 파이프라인은 지난 10년 동안 검색, 광고 및 추천 시스템을 상대적으로 변화 없이 지원해왔습니다. 변화한 것은 각 레이어가 대규모 모델과 에이전트에 의해 재편되고 있는 깊이입니다. 아래 섹션에서는 각 레이어를 살펴보고 합의(명확하게 변화하는 것)와 비합의(여전히 논의 중인 것)를 구분합니다.
각 레이어가 변화하는 방법
1. 데이터 수집 — 합성 데이터가 1급 소스가 되다
전통적으로 유용한 데이터는 실제 세계에서 나왔습니다: 로그, 거래, 센서, 설문조사. 그 가정은 깨지기 시작하고 있습니다. 이제 점점 더 많은 데이터가 수집되는 것이 아니라 생성되고 있습니다 — 페르소나 시뮬레이션, 행동 모델링, 합성 인터뷰, A/B 테스트 데이터 생성 및 강화 학습 훈련과 평가에 사용되는 시뮬레이션 환경을 통해.
합의: 합성 데이터는 실제 데이터, 특히 콜드 스타트 문제, 드문 시나리오 및 개인 정보 보호가 제한된 환경에서 점점 더 보완될 것입니다.
비합의: 모델이 점점 더 다른 모델이 생성한 데이터로 훈련될 때 어떤 일이 발생할까요? 합성 분포가 현실에서 점차 멀어지고 피드백 루프를 형성할까요?
데이터 수집은 *수집*에서 *생성 + 보정*으로 이동하고 있습니다.
2. 데이터 저장 — 테이블에서 벡터 인프라로
전통적인 데이터 시스템은 구조화된 저장소를 중심으로 구축되었습니다: 관계형 데이터베이스, 데이터 웨어하우스 및 열 저장소. AI는 새로운 레이어를 도입합니다 — 벡터 표현. 텍스트, 이미지, 비디오, 사용자 행동 궤적 및 지식 조각은 점점 더 임베딩으로 저장되어 의미 검색, 검색 보강 생성 및 다중 모드 추론을 지원합니다. FAISS, Milvus 및 Pinecone과 같은 벡터 데이터베이스는 핵심 인프라가 되고 있습니다.
합의: 임베딩 기반 검색은 이제 표준 디자인 패턴입니다. RAG는 LLM을 독점 데이터에 접지하기 위한 기본 아키텍처입니다.
비합의: 벡터가 결국 전통적인 저장소 레이어를 대체할까요? 아니면 원시 데이터 위에 인덱싱 레이어로 남을까요? 임베딩에서 원래 데이터를 충분히 재구성할 수 있어 벡터가 기본 저장소가 될 수 있을까요?
현재로서는 임베딩이 저장소로서의 기능보다는 지능형 접근 레이어로서의 기능을 하고 있습니다. 그러나 그 레이어는 이미 데이터 접근 방식을 재편했습니다.
3. 데이터 분석 — SQL에서 대화형 탐색으로
분석 레이어는 가장 빠르게 변화하고 있습니다. 전통적인 워크플로는 다음과 같았습니다:
문제 정의 → SQL → 기능 엔지니어링 → 모델링 → 해석
오늘날 AI 시스템은 거의 모든 단계에서 도움을 줄 수 있습니다: LLM은 SQL을 자동 생성하고, 가설을 제안하며, 시각화를 구축하고, 기준 모델을 구성하고, 결과를 설명합니다. 분석가의 역할은 *쿼리 작성자*에서 *문제 정의자 및 검증자*로 이동합니다.
합의: 모든 데이터 전문가는 곧 AI 어시스턴트와 함께 작업할 것입니다. 코파일럿과 채팅 기반 분석이 기본 요소가 되고 있습니다.
비합의: 에이전트가 결국 전체 분석을 끝까지 수행할까요? 고객 지원에서는 에이전트가 이미 80%의 티켓을 처리할 수 있습니다. 데이터 분석은 더 어렵습니다 — 질문 자체가 종종 모호하고 목표가 조사 중에 변경됩니다. 자동화는 실행을 가속화하겠지만, 인간은 여전히 문제를 정의하는 책임을 질 가능성이 높습니다.
4. 데이터 적용 — 보고서에서 자율 시스템으로
마지막 단계 — 통찰력 적용 — 는 두 가지 측면에서 진화하고 있습니다.
보고서. AI는 이미 보고서를 변형합니다: 자동 요약, 차트, 대시보드 및 텍스트, 이미지 및 비디오 전반에 걸친 프레젠테이션. 더 깊은 변화는 보고서가 더 이상 주기적으로 생성될 필요가 없다는 것입니다. 보고서는 지속적으로 생성되고 필요에 따라 생성될 수 있습니다. 진정한 생산성 향상은 "더 빠르게 쓰는 것"이 아니라 "질문이 제기될 때 존재하는 보고서"입니다.
자율 시스템. 추천, 검색, 광고 및 자율 주행은 수작업으로 설계된 모듈식 파이프라인에서 모델 자체가 의사 결정 정책이 되는 엔드 투 엔드 모델로 이동하고 있습니다. 변화는 *기능 소비자*에서 *전략 생성자*로 이동하고 있습니다.
어시스턴트 대 에이전트 — 합의와 비합의
하나의 새로운 합의: 어시스턴트와 에이전트는 장기적으로 공존할 것입니다. 그러나 균형은 도메인에 따라 크게 다릅니다.
| 도메인 | 어시스턴트 비율 | 에이전트 비율 |
|---|---|---|
| 고객 지원 | 20% | 80% |
| 데이터 분석 | 70% | 30% (불확실) |
| 추천 정책 최적화 | 50% | 50% |
| 자율 주행 | 10% | 90% |
핵심 불확실성은 데이터 분석입니다. 문제 정의 자체가 가장 어려운 부분인 도메인에서는 에이전트가 루프를 닫는 데 어려움을 겪습니다. 가장 가능성이 높은 결과: 분석은 어시스턴트 중심으로 남아 있지만, 실행은 고도로 자동화됩니다. 인간은 문제를 정의하고, 에이전트는 탐색합니다.
더 깊은 변화는 더 빠른 SQL이나 더 나은 대시보드가 아닙니다. 그것은 워크플로를 누가 제어하는가입니다. 우리는 *코드로서의 파이프라인*에서 *추론으로서의 워크플로*로 이동하고 있습니다 — 미리 정의된 단계를 실행하는 것에서 행동을 계획하고, 가설을 탐색하고, 반복하는 시스템으로 이동하고 있습니다.
Tools & Resources
Learn about the best tools available...
Curify가 이 변화에서 차지하는 위치
Curify는 *추론으로서의 워크플로* 패턴을 중심으로 구축되었습니다. 오늘 플랫폼에서의 세 가지 구체적인 예:
- 워크플로로서의 콘텐츠 생성, 단일 샷이 아닌. /nano-template 라이브러리는 프롬프트 → 이미지 생성 → 변형 태깅 → CDN 동기화의 172개 매개변수화된 템플릿으로 구성되어 있습니다 — 생성 워크플로, 일회성 프롬프트가 아닙니다.
- 갤러리 레이어에서의 임베딩 기반 접근. /nano-banana-pro-prompts 4,000개 이상의 프롬프트 코퍼스는 태그, 주제 및 의미적 유사성으로 검색할 수 있습니다 — 벡터 레이어가 접근 경로이며, 원시 JSON이 진실의 출처입니다.
- 오디오 + 비디오 전사로서의 상류 입력. /tools/video-transcript-generator 는 /tools/video-dubbing 및 /tools/translate-subtitles로 흐르는 화자 태그가 있는 전사를 출력합니다 — 하나의 입력이 세 개의 현지화된 출력을 이끄는 워크플로입니다.
데이터 전문가를 위한 진짜 질문
전통적인 데이터 워크플로는 사라지지 않습니다. 그러나 진화하고 있습니다: 데이터 생성이 더 지능적으로 변하고, 저장이 더 의미 있게 변하며, 분석이 더 대화형으로 변하고, 응용이 더 자율적으로 변하고 있습니다.
더 급진적인 비합의적 관점: 미래의 데이터 시스템은 두 가지로 나뉠 수 있습니다 — 인간이 해석할 수 있는 분석 시스템 (세상을 이해하기 위한)과 블랙박스 최적화 시스템 (결과 최적화를 위한). 두 가지가 분리될 때, 데이터 전문가는 사라지지 않고 데이터 운영자가 아닌 *전략 해석자*가 됩니다.
오늘날 모든 데이터 전문가에게 진짜 질문은 더 이상 "SQL을 쓸 수 있습니까?"가 아닙니다. 그것은: AI 네이티브 워크플로를 설계할 수 있습니까?
Take the next step
Putting what you read into practice.