実ユーザーのクエリを用いた自己改善型マルチモーダル検索エンジンの構築 - Curify
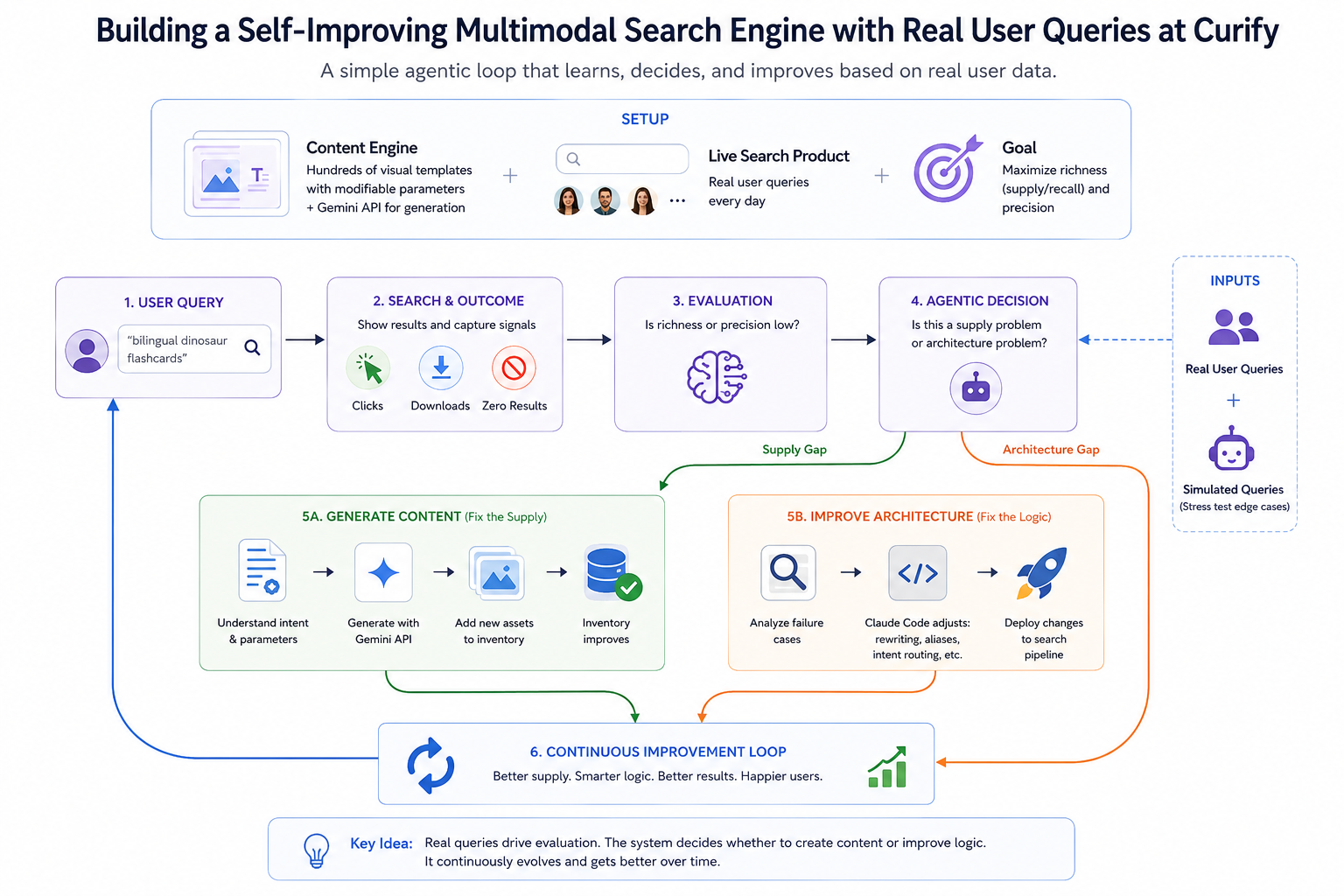
従来の検索エンジンは静的なインデックスであり、世界がそれらを埋めるのを待っています。エージェントワークフローと「バイブコーディング」の時代において、検索システムの構築はBM25やベクトル埋め込みの最適化だけではなく、自律的なループを構築し、学習し、決定し、自らの供給を構築することが重要です。Curifyでは、最近検索バーを受動的な情報取得ツールから自己改善型マルチモーダルエンジンに変革しました。この投稿では、実ユーザーデータに基づいてエージェントループをどのように設計したかを紹介します。
セットアップ:ダイナミックサプライチェーン
エンジンを理解するためには、まず在庫から始めます。Curifyはオープンウェブをインデックス化しているわけではなく、セットアップは非常に制御された決定論的なものです:
コンテンツエンジン:変更可能なパラメータを持つ数百の構造化されたビジュアルテンプレートが、Gemini APIに直接接続され、高忠実度の画像生成を行います。
シグナル:毎日、実世界のユーザーのクエリをキャプチャするライブ検索製品です。
最適化の目標は明確です:検索結果の*豊かさ*(供給/リコール)と*精度*を最大化します。しかし、手動で重みを調整するのではなく、ライブユーザーのクエリを動的で継続的な評価セットに変えます。各パフォーマンスが低いクエリはトレーニングシグナルとなります — 勾配降下の意味ではなく、エージェント的な意思決定の意味で。パイプラインは*なぜ*クエリが失敗したのかを考え、適切な修正にルーティングします。
評価 → 理由付け → 行動ループ
ステップ1:実際のクエリをキャプチャ(エッジケースをシミュレート)
Curifyでのすべての検索は、クエリと即時の結果(クリック、ダウンロード、または恐ろしいゼロ結果ページ)をキャプチャします。これにより、実際のシグナルのストリームが得られます。
また、実ユーザーがそれに遭遇する前にエッジケースをストレステストするために*シミュレートされた*ユーザー応答を注入します — LLM駆動のエージェントがカタログの隅々を探るような小さな合成トラフィック生成器です。実際のクエリはユーザーが実際に必要とするものを浮き彫りにし、シミュレートされたクエリは私たちが期待するパターンに基づいて彼らが*必要とする*ものを浮き彫りにします。両方とも同じ評価パイプラインに供給されます。
ステップ2:各パフォーマンスが低いクエリを評価
低い豊かさや精度をもたらすクエリは評価ノードをトリガーします。評価者は、実際のエンゲージメントシグナル(クリック、滞在時間、ダウンロード)を、結果を返したがエンゲージメントがあいまいなクエリに対するGeminiによる関連性スコアリングと組み合わせます。
評価者は単にエラーを記録するだけではありません。エージェント的な質問をします:*これは供給の問題か、アーキテクチャの問題か?* その分岐がループの中心であり、次にどちらのアクションパスが発火するかを決定します。
ステップ3:意思決定の分岐 — コンテンツを生成(供給を修正)
評価がユーザーの意図が有効であると判断した場合(例:「バイリンガル恐竜フラッシュカード」)でも、データベースが本当に空であれば、システムは自律的なクリエイターとして行動します。
アクション:クエリパラメータをテンプレートエンジンにルーティングし、Gemini APIをトリガーし、欠けているビジュアルアセットをバッチ生成します — 通常のコンテンツドロップを駆動する同じテンプレート駆動のパイプラインが、失敗した検索によってオンデマンドで呼び出されます。
次のユーザー(またはシミュレートされたエージェント)が同じ検索を実行する頃には、在庫は自己修復されています。検索エンジンは文字通り欠けていたものを構築しました。
ステップ4:意思決定の分岐 — アーキテクチャを改善(ロジックを修正)
コンテンツが存在する場合(「T-Rex教育ポスター」)でも、ユーザーのクエリ(「ジュラ紀の学習資料」)がそれを浮き彫りにできなかった場合、エンジンはアーキテクチャのギャップを示します。
アクション:ここでバイブコーディングがその価値を発揮します。開発者が手動で正規表現ルールを書くのではなく、失敗した評価ケースをClaude Codeに供給し、次のように促します:
- クエリの書き換えルールを更新
- 新しいエイリアスの拡張を生成
- LLM意図ルーティングプロンプトを洗練
検索パイプラインへのアーキテクチャの調整は数分で出荷され、完全に実ユーザーの摩擦ポイントに基づいています。エンジニアは差分をレビューしながらループに留まりますが、エージェントは仮想的なクエリについて推測するのではなく、実際のケースに対してドラフトを行います。
これが置き換えるもの
ループが置き換える3つのパターン:
手動コンテンツバックフィル:従来の検索チームは「リコールが低いクエリ」のバックログを維持し、ギャップを埋めるためにコンテンツ委託を行います。遅延は数週間で、多くは埋まることがありません。エージェントループは数時間でギャップを埋めます。
手書きの書き換えルール:検索エンジニアがキーワードごとのエイリアスを書いたり、ステミング辞書を維持したりします。必要ですが遅く、新しいクエリパターンが出現するにつれてルールが漂流します。バイブコーディングされた書き換えはケースのボリュームに対して線形にスケールし、エンジニアの時間ではありません。
静的評価セット:一度作成されて凍結された関連性ベンチマーク。実ユーザーのクエリは毎週変化します — 静的な評価セットは前四半期の現実を測定しています。ライブクエリを評価セットとして扱うことで、システムはユーザーが*今週*実際に検索するものに最適化されます。
Tools & Resources
Learn about the best tools available...
スタックの接続方法
エージェントレイヤーによって接続された4つのコンポーネント:
検索フロントエンドはクエリとエンゲージメントシグナルをキャプチャし、ほぼリアルタイムで評価者に送信します。
テンプレートエンジンはCurifyのNano Bananaライブラリです — 欠けているコンテンツを生成するために供給側の分岐が呼び出す数百のパラメータ化されたビジュアルテンプレート。手動コンテンツドロップを駆動する同じエンジンで、ループは別の呼び出し元になります。
Gemini APIは画像生成(供給側)と関連性スコアリング(評価側)の両方を処理します。単一のモデルファミリー、2つの役割。
Claude Codeはアーキテクチャ側の更新を処理します — 書き換えルール、エイリアスの拡張、意図ルーティングプロンプト。エージェントは失敗したケースに関するコンテキストと既存のパイプライン状態を取得し、差分を返し、エンジニアがレビューして出荷します。
統合コストは予想よりも低く、テンプレートエンジンと検索フロントエンドはすでに独立したシステムでした。エージェントループは、すでに持っているツールの上にある調整レイヤーであり、書き換えではなく、最初のバージョンを数日で出荷できた理由です。
オーケストレーションとしての検索
検索はもはや情報の取得やランキングだけではなく、オーケストレーションの問題です。実ユーザーのクエリを単なるメトリクスとしてではなく、エージェント的な意思決定者のためのアクティブなトリガーとして扱うことで、自己のエントロピーと戦うシステムを構築しました。
Curifyでは、検索エンジンはもはやコンテンツを見つけるだけではありません。コンテンツが欠けている場合は、それを作成します。ロジックに欠陥がある場合は、それを再構築します。供給側とアーキテクチャ側は、両方とも同じシグナル — 昨日機能しなかったクエリから改善されます。
それが次世代の検索システムのモデルです:より大きなインデックスではなく、より密なループです。
Take the next step
Putting what you read into practice.