AIがデータワークフローを再構築する:アシスタントからエージェントへ
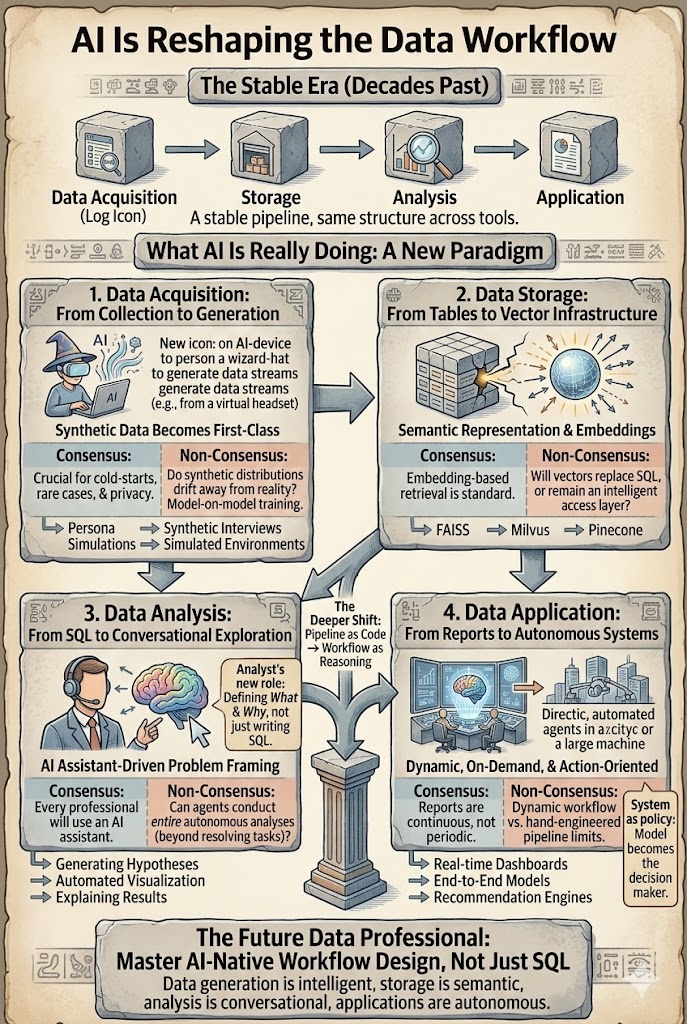
データワークフローは10年間非常に安定していました。データサイエンティスト、アナリスト、またはレコメンデーションエンジニアであっても、パイプラインは大体同じように見えました:取得 → 保存 → 分析 → 適用。AIはこのワークフローを加速させるだけでなく、各層を再構築し始めています。本当の問題は、AIがデータ作業を変えるかどうかではなく、どの部分が明らかに変わり、どの仮定が間違っていることが判明するかです。
データワークフローの四つの層
異なるツール、異なる業界 — しかし基本的には同じ四段階の構造:データを生成または収集し、保存し、分析し、洞察を適用します。このパイプラインは、比較的形状に変化が少ないまま、10年間の検索、広告、レコメンデーションシステムを支えてきました。変わったのは、各層が大規模モデルやエージェントによって再構築される深さです。以下のセクションでは、各層を歩き、コンセンサス(明らかに変わっていること)と非コンセンサス(まだ議論の余地があること)を分けます。
各層がどのように変わっているか
1. データ取得 — 合成データが第一級のソースに
従来、有用なデータは現実世界から来ていました:ログ、トランザクション、センサー、調査。その仮定は崩れ始めています。ますます多くのデータが収集されるのではなく生成されています — ペルソナシミュレーション、行動モデリング、合成インタビュー、A/Bテストデータ生成、強化学習のトレーニングと評価に使用されるシミュレーション環境を通じて。
コンセンサス: 合成データは、特にコールドスタート問題、希少なシナリオ、プライバシー制約のある環境において、現実世界のデータを補完するようになります。
非コンセンサス: モデルが他のモデルによって生成されたデータでますますトレーニングされると、どうなりますか?合成分布は現実から徐々に逸脱し、フィードバックループを形成するのでしょうか?
データ取得は*収集*から*生成 + キャリブレーション*に移行しています。
2. データ保存 — テーブルからベクトルインフラストラクチャへ
従来のデータシステムは、構造化ストレージを中心に構築されていました:リレーショナルデータベース、データウェアハウス、カラムストア。AIは新しい層を導入します — ベクトル表現。テキスト、画像、動画、ユーザー行動の軌跡、知識の断片は、セマンティック検索、リトリーバル拡張生成、マルチモーダル推論を支える埋め込みとしてますます保存されています。FAISS、Milvus、Pineconeなどのベクトルデータベースがコアインフラストラクチャになりつつあります。
コンセンサス: 埋め込みベースのリトリーバルは現在の標準設計パターンです。RAGは、独自データに基づいてLLMをグラウンディングするためのデフォルトアーキテクチャです。
非コンセンサス: ベクトルは最終的に従来のストレージ層を置き換えるのでしょうか?それとも、生データの上にインデックス層として残るのでしょうか?埋め込みから元のデータを十分に再構築できるのでしょうか?それによってベクトルが主要なストレージになるのでしょうか?
現時点では、埋め込みはストレージとして機能するのではなく、インテリジェントアクセス層として機能しています。しかし、その層はすでにデータへのアクセス方法を再構築しています。
3. データ分析 — SQLから会話型探索へ
分析層は最も早く変化しています。従来のワークフローは次のようになっていました:
問題定義 → SQL → 特徴エンジニアリング → モデリング → 解釈
今日、AIシステムはほぼすべてのステップを支援できます:LLMはSQLを自動生成し、仮説を提案し、視覚化を構築し、ベースラインモデルを構築し、結果を説明します。アナリストの役割は*クエリライター*から*問題のフレーマーおよびバリデーター*に移行します。
コンセンサス: すべてのデータ専門家はすぐにAIアシスタントと共に働くことになるでしょう。コパイロットとチャットベースの分析がテーブルステークスになりつつあります。
非コンセンサス: エージェントは最終的にエンドツーエンドで全体の分析を実施するのでしょうか?カスタマーサポートでは、エージェントがすでに80%のチケットを処理できます。データ分析はより難しいです — 質問自体がしばしば曖昧で、目標が調査の途中で変わります。自動化は実行を加速しますが、人間はおそらく問題をフレーミングする責任を持ち続けるでしょう。
4. データ適用 — レポートから自律システムへ
最終段階 — 洞察の適用 — は二つの前線で進化しています。
レポート。 AIはすでに報告を変革しています:自動要約、チャート、ダッシュボード、テキスト、画像、動画にわたるプレゼンテーション。より深い変化は、レポートが定期的である必要がなくなったことです。レポートは継続的に生成され、オンデマンドで生成できます。本当の生産性の向上は「速く書く」ことではなく、「質問がされたときに存在するレポート」です。
自律システム。 レコメンデーション、検索、広告、自律運転は、手動で設計されたモジュラーなパイプラインから、モデル自体が意思決定ポリシーになるエンドツーエンドモデルへと移行しています。変化は*特徴消費者*から*戦略生成者*への移行です。
アシスタント対エージェント — コンセンサスと非コンセンサス
一つの新たなコンセンサス:アシスタントとエージェントは長期的に共存するでしょう。 しかし、バランスはドメインによって大きく異なります。
| ドメイン | アシスタントの割合 | エージェントの割合 |
|---|---|---|
| カスタマーサポート | 20% | 80% |
| データ分析 | 70% | 30%(不確実) |
| レコメンデーションポリシー最適化 | 50% | 50% |
| 自律運転 | 10% | 90% |
重要な不確実性はデータ分析です。問題定義自体が最も難しい部分であるドメインでは、エージェントはループを閉じるのが難しいです。最も可能性の高い結果:分析はアシスタント重視のままですが、実行は高度に自動化されます。人間がフレームを作り、エージェントが探索します。
より深い変化は、より速いSQLやより良いダッシュボードではありません。それはワークフローを制御するのは誰かです。私たちは*パイプラインをコードとして*から*推論としてのワークフロー*へと移行しています — 事前定義されたステップを実行することから、行動を計画し、仮説を探索し、反復するシステムへと。
Tools & Resources
Learn about the best tools available...
Curifyがこの変化の中で果たす役割
Curifyは*推論としてのワークフロー*パターンを中心に構築されています。現在プラットフォーム上にある三つの具体例:
- ワークフローとしてのコンテンツ生成、単発ではない。 /nano-templateライブラリは172のパラメータ化されたテンプレートで、プロンプト → 画像生成 → バリアントタグ付け → CDN同期 — 生成ワークフローであり、一回限りのプロンプトではありません。
- ギャラリー層での埋め込みバックアクセス。 /nano-banana-pro-promptsコーパスは4,000以上のプロンプトがタグ、トピック、セマンティック類似性で検索可能 — ベクトル層がアクセスパスであり、生のJSONが真実のソースです。
- 音声 + 動画のトランスクリプションを上流入力として。 /tools/video-transcript-generatorはスピーカータグ付きのトランスクリプトを出力し、それが/tools/video-dubbingと/tools/translate-subtitlesに流れ込む — 一つの入力が三つのローカライズされた出力を駆動するワークフローです。
データ専門家にとっての本当の質問
従来のデータワークフローは消えません。しかし、それは進化しています:データ生成はよりインテリジェントになり、保存はよりセマンティックになり、分析はより会話型になり、アプリケーションはより自律的になります。
より過激な非コンセンサスの見解:将来のデータシステムは二つに分かれるかもしれません — 人間が解釈可能な分析システム(世界を理解するための)とブラックボックス最適化システム(結果を最適化するための)。二つが分かれると、データ専門家は消えるのではなく、データオペレーターではなく*戦略の解釈者*になります。
今日のデータ専門家にとっての本当の質問はもはや「SQLを書けますか?」ではありません。それは:AIネイティブのワークフローを設計できますか?
Take the next step
Putting what you read into practice.