एआई डेटा कार्यप्रवाह को पुनः आकार दे रहा है: सहायक से एजेंट तक
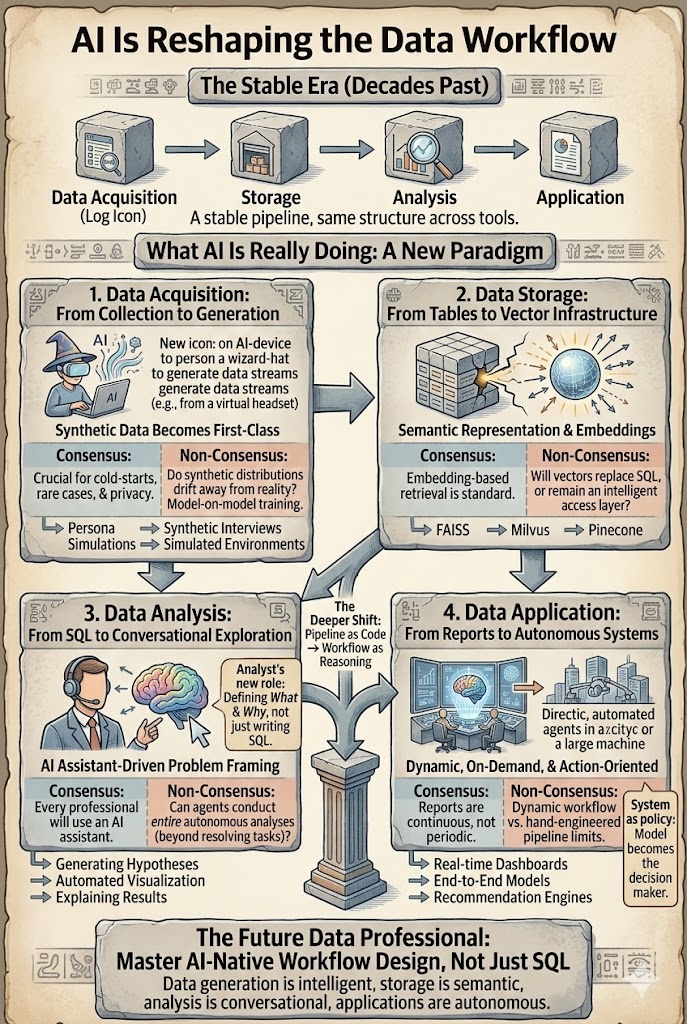
डेटा कार्यप्रवाह एक दशक सेRemarkably स्थिर रहा है। चाहे आप डेटा वैज्ञानिक, विश्लेषक, या सिफारिश इंजीनियर हों, पाइपलाइन लगभग समान दिखती है: अधिग्रहण → भंडारण → विश्लेषण → अनुप्रयोग। एआई केवल इस कार्यप्रवाह को तेज नहीं कर रहा है - यह इसके प्रत्येक स्तर को पुनः आकार देना शुरू कर रहा है। असली सवाल अब यह नहीं है कि क्या एआई डेटा कार्य को बदल देगा। यह है कि कौन से भाग स्पष्ट रूप से बदल रहे हैं, और कौन से अनुमान गलत साबित होंगे।
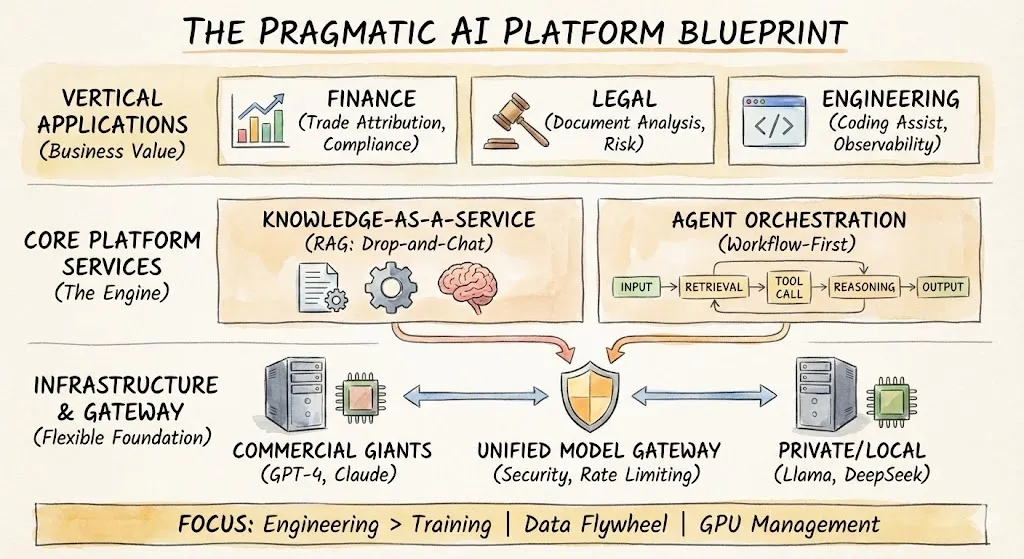
डेटा कार्यप्रवाह के चार स्तर
विभिन्न उपकरण, विभिन्न उद्योग - लेकिन मौलिक रूप से वही चार-चरणीय संरचना: डेटा उत्पन्न करना या एकत्र करना, इसे संग्रहीत करना, इसका विश्लेषण करना, अंतर्दृष्टि लागू करना। यह पाइपलाइन पिछले दस वर्षों से खोज, विज्ञापनों और सिफारिश प्रणाली को अपेक्षाकृत कम परिवर्तन के साथ शक्ति प्रदान करती है। जो बदल गया है वह यह है कि अब प्रत्येक स्तर बड़े मॉडलों और एजेंटों द्वारा पुनः आकार दिया जा रहा है। नीचे के अनुभाग प्रत्येक स्तर को चलाते हैं और सहमति (जो स्पष्ट रूप से बदल रहा है) को गैर-सहमति (जो अभी भी बहस के लिए खुला है) से अलग करते हैं।
प्रत्येक स्तर कैसे बदल रहा है
1. डेटा अधिग्रहण - सिंथेटिक डेटा एक प्रथम श्रेणी के स्रोत के रूप में
परंपरागत रूप से, उपयोगी डेटा वास्तविक दुनिया से आया: लॉग, लेनदेन, सेंसर, सर्वेक्षण। यह धारणा टूटने लगी है। अब अधिक से अधिक डेटा उत्पन्न किया जा रहा है बजाय इसके कि इसे एकत्र किया जाए - व्यक्तित्व सिमुलेशन, व्यवहार मॉडलिंग, सिंथेटिक इंटरव्यू, A/B परीक्षण डेटा उत्पन्न करने, और सिमुलेटेड वातावरण का उपयोग करके जो पुनर्बलन सीखने के प्रशिक्षण और मूल्यांकन के लिए उपयोग किया जाता है।
सहमति: सिंथेटिक डेटा धीरे-धीरे वास्तविक दुनिया के डेटा को पूरा करेगा, विशेष रूप से ठंडे प्रारंभ समस्याओं, दुर्लभ परिदृश्यों, और गोपनीयता-सीमित वातावरण में।
गैर-सहमति: जब मॉडल अधिक से अधिक डेटा पर प्रशिक्षित होते हैं जो अन्य मॉडलों द्वारा उत्पन्न होता है तो क्या होता है? क्या सिंथेटिक वितरण धीरे-धीरे वास्तविकता से दूर हो जाएंगे और फीडबैक लूप बनाएंगे?
डेटा अधिग्रहण *एकत्रण* से *उत्पादन + कैलिब्रेशन* की ओर बढ़ रहा है।
2. डेटा भंडारण - तालिकाओं से वेक्टर अवसंरचना तक
परंपरागत डेटा सिस्टम संरचित भंडारण के चारों ओर बनाए गए थे: संबंधपरक डेटाबेस, गोदाम, और कॉलम स्टोर। एआई एक नया स्तर पेश करता है - वेक्टर प्रतिनिधित्व। टेक्स्ट, छवियाँ, वीडियो, उपयोगकर्ता व्यवहार की पथरेखा, और ज्ञान के टुकड़े अब अधिक से अधिक एम्बेडिंग के रूप में संग्रहीत किए जा रहे हैं जो अर्थपूर्ण खोज, पुनर्प्राप्ति-संवर्धित पीढ़ी, और मल्टीमोडल तर्क को शक्ति प्रदान करते हैं। FAISS, Milvus, और Pinecone जैसे वेक्टर डेटाबेस मुख्य अवसंरचना बन रहे हैं।
सहमति: एम्बेडिंग-आधारित पुनर्प्राप्ति अब एक मानक डिज़ाइन पैटर्न है। RAG विशेष डेटा में LLMs को ग्राउंड करने के लिए डिफ़ॉल्ट आर्किटेक्चर है।
गैर-सहमति: क्या वेक्टर अंततः पारंपरिक भंडारण स्तरों को प्रतिस्थापित करेंगे? या क्या वे कच्चे डेटा के ऊपर एक अनुक्रमण स्तर बने रहेंगे? क्या हम एम्बेडिंग से मूल डेटा को इस हद तक पुनर्निर्माण कर सकते हैं कि वेक्टर प्राथमिक भंडारण बन जाएं?
अभी के लिए, एम्बेडिंग भंडारण के रूप में कम और एक बुद्धिमान पहुंच स्तर के रूप में अधिक कार्य करती हैं। लेकिन वह स्तर पहले से ही डेटा तक पहुंचने के तरीके को पुनः आकार दे चुका है।
3. डेटा विश्लेषण - SQL से संवादात्मक अन्वेषण तक
विश्लेषण स्तर सबसे तेजी से बदल रहा है। पारंपरिक कार्यप्रवाह इस तरह दिखता था:
समस्या परिभाषा → SQL → विशेषता इंजीनियरिंग → मॉडलिंग → व्याख्या
आज, एआई सिस्टम लगभग हर कदम में सहायता कर सकते हैं: LLMs स्वचालित रूप से SQL उत्पन्न करते हैं, परिकल्पनाएँ प्रस्तावित करते हैं, दृश्य प्रस्तुतियाँ बनाते हैं, आधारभूत मॉडल बनाते हैं, और परिणामों की व्याख्या करते हैं। विश्लेषक की भूमिका *क्वेरी लेखक* से *समस्या फ्रेमर और मान्यकर्ता* में बदल जाती है।
सहमति: हर डेटा पेशेवर जल्द ही एक एआई सहायक के साथ काम करेगा। सह-पायलट और चैट-आधारित विश्लेषण अब टेबल स्टेक बन रहे हैं।
गैर-सहमति: क्या एजेंट अंततः संपूर्ण विश्लेषण को अंत-से-अंत तक करेंगे? ग्राहक सहायता में, एजेंट पहले से ही 80% टिकट संभाल सकते हैं। डेटा विश्लेषण कठिन है - प्रश्न स्वयं अक्सर अस्पष्ट होते हैं और लक्ष्य मध्य-जांच में बदलते हैं। स्वचालन निष्पादन को तेज करेगा, लेकिन मनुष्य शायद समस्या को फ्रेम करने के लिए जिम्मेदार रहेंगे।
4. डेटा अनुप्रयोग - रिपोर्टों से स्वायत्त प्रणालियों तक
अंतिम चरण - अंतर्दृष्टियों को लागू करना - दो मोर्चों पर विकसित हो रहा है।
रिपोर्ट। एआई पहले से ही रिपोर्टिंग को बदलता है: स्वचालित सारांश, चार्ट, डैशबोर्ड, और टेक्स्ट, छवि, और वीडियो के बीच प्रस्तुतियाँ। गहरा बदलाव यह है कि रिपोर्ट अब आवधिक होने की आवश्यकता नहीं है। उन्हें लगातार और मांग पर उत्पन्न किया जा सकता है। असली उत्पादकता लाभ "तेजी से लिखना" नहीं है बल्कि "रिपोर्ट जो तब मौजूद होती हैं जब प्रश्न पूछा जाता है।"
स्वायत्त प्रणालियाँ। सिफारिश, खोज, विज्ञापन, और स्वायत्त ड्राइविंग हाथ से इंजीनियर किए गए मॉड्यूलर पाइपलाइनों से अंत-से-अंत मॉडल की ओर बढ़ रहे हैं जहाँ मॉडल स्वयं निर्णय नीति बन जाता है। बदलाव *विशेषता उपभोक्ता* से *रणनीति जनरेटर* की ओर है।
सहायक बनाम एजेंट - सहमति और गैर-सहमति
एक उभरती हुई सहमति: सहायक और एजेंट दीर्घकालिक सह-अस्तित्व में रहेंगे। लेकिन संतुलन क्षेत्रों के बीच तेज़ी से भिन्न होता है।
| क्षेत्र | सहायक हिस्सा | एजेंट हिस्सा |
|---|---|---|
| ग्राहक सहायता | 20% | 80% |
| डेटा विश्लेषण | 70% | 30% (अनिश्चित) |
| सिफारिश नीति अनुकूलन | 50% | 50% |
| स्वायत्त ड्राइविंग | 10% | 90% |
मुख्य अनिश्चितता डेटा विश्लेषण है। उन क्षेत्रों में जहाँ समस्या परिभाषा स्वयं सबसे कठिन भाग है, एजेंटों को लूप बंद करने में कठिनाई होती है। सबसे संभावित परिणाम: विश्लेषण सहायक-भारी रहता है, लेकिन निष्पादन अत्यधिक स्वचालित हो जाता है। मनुष्य फ्रेम करते हैं; एजेंट अन्वेषण करते हैं।
गहरा बदलाव यह नहीं है कि तेज़ SQL या बेहतर डैशबोर्ड। यह है कौन कार्यप्रवाह को नियंत्रित करता है। हम *पाइपलाइन कोड के रूप में* से *कार्यप्रवाह को तर्क के रूप में* की ओर बढ़ रहे हैं - पूर्व-निर्धारित चरणों को निष्पादित करने से लेकर ऐसे सिस्टम तक जो क्रियाएँ योजना बनाते हैं, परिकल्पनाओं का अन्वेषण करते हैं, और पुनरावृत्ति करते हैं।
Tools & Resources
Learn about the best tools available...
इस बदलाव में Curify की भूमिका
Curify *कार्यप्रवाह को तर्क के रूप में* पैटर्न के चारों ओर बनाया गया है। आज प्लेटफ़ॉर्म पर तीन ठोस उदाहरण:
- सामग्री उत्पन्न करना कार्यप्रवाह के रूप में, एकल-शॉट के रूप में नहीं। /nano-template पुस्तकालय 172 पैरामीटरयुक्त टेम्पलेट हैं जो प्रॉम्प्ट → छवि उत्पन्न करना → विविधता टैगिंग → CDN समन्वय - एक उत्पन्न कार्यप्रवाह, न कि एक बार का प्रॉम्प्ट।
- गैलरी स्तर पर एम्बेडिंग-समर्थित पहुंच। /nano-banana-pro-prompts 4,000+ प्रॉम्प्ट्स का संग्रह है जिसे टैग, विषय, और अर्थपूर्ण समानता द्वारा खोजा जा सकता है - वेक्टर स्तर पहुंच का मार्ग है, कच्चा JSON सत्य का स्रोत है।
- ऑडियो + वीडियो ट्रांसक्रिप्शन को अपस्ट्रीम इनपुट के रूप में। /tools/video-transcript-generator स्पीकर-टैग किए गए ट्रांसक्रिप्ट उत्पन्न करता है जो /tools/video-dubbing और /tools/translate-subtitles में प्रवाहित होते हैं - एक कार्यप्रवाह जहाँ एक इनपुट तीन स्थानीयकृत आउटपुट को चलाता है।
डेटा पेशेवरों के लिए असली सवाल
पारंपरिक डेटा कार्यप्रवाह गायब नहीं हो रहा है। लेकिन यह विकसित हो रहा है: डेटा उत्पन्न करना अधिक बुद्धिमान होता जा रहा है, भंडारण अधिक अर्थपूर्ण होता जा रहा है, विश्लेषण अधिक संवादात्मक होता जा रहा है, अनुप्रयोग अधिक स्वायत्त होते जा रहे हैं।
एक अधिक कट्टर गैर-सहमति दृष्टिकोण: भविष्य के डेटा सिस्टम दो में विभाजित हो सकते हैं - मानव-व्याख्यायित विश्लेषण प्रणाली (दुनिया को समझने के लिए) और ब्लैक-बॉक्स अनुकूलन प्रणाली (परिणामों को अनुकूलित करने के लिए)। जब दोनों अलग होते हैं, डेटा पेशेवर गायब नहीं होते; वे डेटा ऑपरेटर के बजाय *रणनीति व्याख्याकार* बन जाते हैं।
आज किसी भी डेटा पेशेवर के लिए असली सवाल अब यह नहीं है कि "क्या आप SQL लिख सकते हैं।" यह है: क्या आप एआई-नैटिव कार्यप्रवाह डिजाइन कर सकते हैं?
Take the next step
Putting what you read into practice.
संबंधित लेख
DS & AI Engineering
संभाव्य से निश्चित: उत्पादन में एआई इंजीनियरिंग के बारे में कठिन सच्चाइयाँ
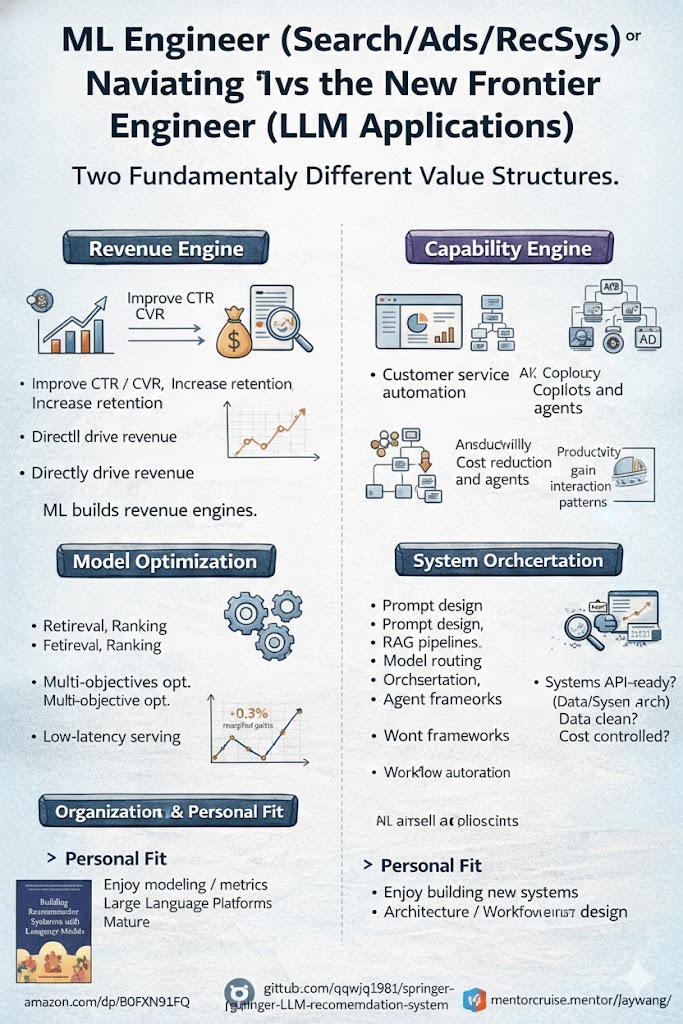
ML इंजीनियर या AI इंजीनियर? दो करियर पथ, दो मूल्य संरचनाएँ