Meilleurs outils de clonage vocal IA en 2026 : ElevenLabs vs F5-TTS vs OpenVoice
La plupart des articles sur ce sujet présentent plus de 10 outils dans une liste classée. Ce n'est pas utile : trois outils couvrent presque tous les cas d'utilisation réels, et les différences entre eux sont marquées. Ce guide sélectionne les trois, indique ce que chacun fait le mieux et signale le cas d'utilisation commun (doublage d'une vidéo dans une autre langue tout en gardant votre voix) où vous n'avez pas besoin d'un outil de clonage vocal.
Pour qui c'est
Créateurs choisissant un outil pour cloner leur propre voix pour la narration, les livres audio ou une fonctionnalité TTS personnalisée. Équipes produit lançant une capacité de clonage vocal dans un SaaS. Équipes de localisation considérant open-source vs commercial. Si vous essayez de localiser une vidéo YouTube dans une autre langue avec votre propre voix, passez directement à l'appel Que faire si vous n'avez pas besoin d'un outil de clonage vocal ? — c'est un problème différent et un outil différent.
Guide d'achat rapide — ce qui compte vraiment
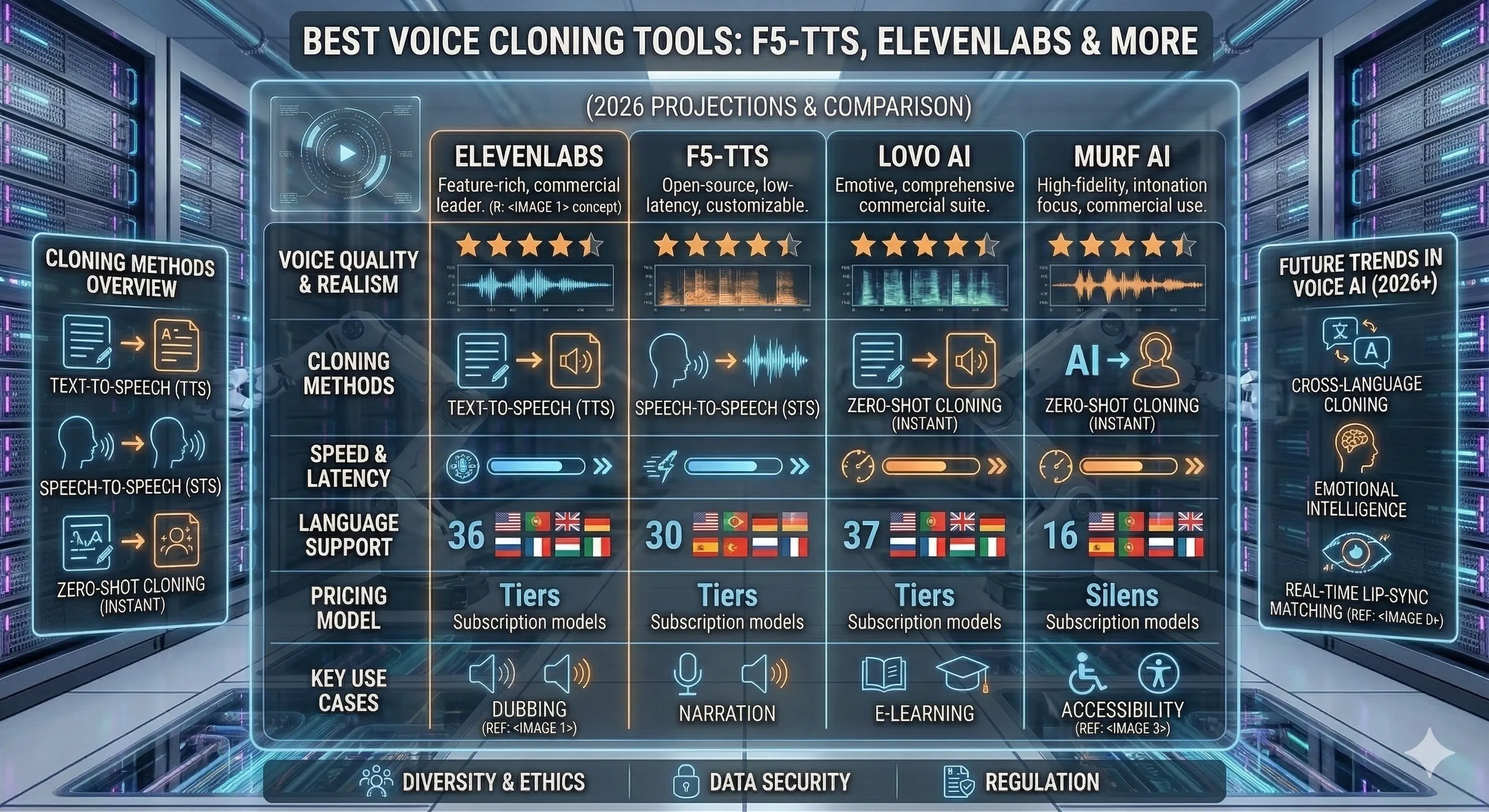
Quatre dimensions comptent ; le reste est du marketing.
1. Consentement et légalité (la seule règle qui compte d'abord). Cloner la voix de quelqu'un d'autre sans consentement écrit explicite est un désastre légal — le RGPD considère la voix comme des données biométriques dans l'UE ; la décision de la FCC de 2024 l'a rendue illégale dans les appels automatisés aux États-Unis. Des outils comme Descript et Resemble imposent une vérification de consentement avant le clonage. Des outils comme F5-TTS laissent la politique à votre charge. Choisissez en conséquence.
2. Modèle de tarification. La facturation par caractère (ElevenLabs, AWS Polly, Azure) évolue de manière linéaire — bon pour un faible volume, douloureux à grande échelle. Les plans d'abonnement limitent vos dépenses. L'auto-hébergement open-source (F5-TTS, OpenVoice) échange des dollars contre le coût du GPU + le temps d'ingénierie.
3. Fidélité de la voix vs durée de l'échantillon. Les clones "instantanés" nécessitent 10-30 secondes d'audio de référence et vous donnent 70-80 % de fidélité. Les clones "professionnels" nécessitent 30 minutes ou plus d'audio studio propre et atteignent 95 % ou plus. Choisissez le niveau qui correspond à votre cas d'utilisation — une introduction de podcast nécessite plus de fidélité qu'un outil interne.
4. Où se trouve l'audio. Certains fournisseurs s'octroient une "licence perpétuelle" pour utiliser votre voix téléchargée pour la R&D du modèle. Lisez la politique de confidentialité. Si vous ne pouvez pas faire sortir vos données vocales de votre infrastructure, auto-hébergez F5-TTS ou OpenVoice.
Comment nous avons choisi ces trois
La plupart des listes des "meilleurs outils de clonage vocal" comptent 15 entrées parce que le remplissage aide le SEO. Nous ne sommes pas d'accord. Trois catégories couvrent presque tous les cas d'utilisation réels — finition commerciale, auto-hébergement open-source et alternative open-source légère. Nous avons éliminé 12 outils qui se chevauchent avec ces trois (Murf, Play.ht, Speechify, Lovo, Listnr, TTSMaker, etc. se trouvent tous dans la même catégorie de finition commerciale qu'ElevenLabs ; Fish Audio, Hume, Respeecher ciblent des niches cinématographiques/empathiques). Si vous voulez la longue liste, elle est à portée de recherche Google. Si vous voulez une décision, continuez à lire.
Les trois outils qui valent la peine d'être comparés
Au-delà du texte marketing, le domaine du clonage vocal se divise en trois catégories : le leader commercial poli (ElevenLabs), le cheval de bataille open-source (F5-TTS), et l'alternative open-source légère lorsque F5-TTS ne convient pas (OpenVoice). Chacun attire un lecteur différent. Choisissez celui qui correspond à vos contraintes.

1. ElevenLabs
Le leader commercial pour un clonage vocal poli
- Best for: Voix personnalisées pour produits, livres audio, IVR, voix de personnage pour les médias
- Pricing: Facturation par caractère — niveau gratuit limité ; les plans payants commencent à environ 5 $/mois
- Languages: Plus de 30 langues avec une bibliothèque vocale mature
- Notable limitation: Plateforme fermée avec des barrières de politique de contenu sur le clonage vocal (vérification du consentement requise pour les voix personnalisées) ; les coûts par caractère s'accumulent à volume élevé
Choisissez ElevenLabs lorsque vous avez besoin d'un outil de clonage vocal avec le moins d'obstacles d'ingénierie et la plus haute fidélité de base, et que vous êtes à l'aise avec le verrouillage fournisseur. L'API et la bibliothèque vocale sont les plus matures de la catégorie. Si vous construisez une fonctionnalité produit où vos utilisateurs clonent leur propre voix, c'est le chemin de la moindre résistance.
2. F5-TTS
Le cheval de bataille open-source, multilingue sans échantillonnage
- Best for: Clonage vocal auto-hébergé, équipes techniques, inférence personnalisée, génération par lots
- Pricing: Gratuit (auto-hébergé) — le coût du GPU est le minimum
- Languages: Transfert multilingue sans échantillonnage ; ajustements communautaires pour les langues à faibles ressources
- Notable limitation: Nécessite un GPU et une infrastructure d'inférence ; la prosodie peut dériver sur de longs clips (>30-45s) sans découpage ; les extrêmes expressifs (rire, cri) s'affaiblissent
Choisissez F5-TTS lorsque vous avez des ressources d'ingénierie, souhaitez une économie de coût par clip nulle à grande échelle, ou avez besoin de résidence des données / auto-hébergement pour la conformité. Le modèle utilise un appariement de flux avec un Transformateur de Diffusion — compétitif avec la sortie commerciale une fois que vous ajustez les étapes et la précision. Référentiel de référence : SWivid/F5-TTS ; article de 2025 sur OpenReview.
3. OpenVoice
Alternative open-source légère, licence MIT
- Best for: Clone de clip unique, environnements à faibles ressources, licences permissives
- Pricing: Gratuit (licence MIT, auto-hébergé)
- Languages: 4+ langues prêtes à l'emploi ; transfert de style vocal entre elles
- Notable limitation: Fidélité vocale inférieure à celle des leaders commerciaux ; modèle à faibles ressources, donc moins de leviers de réglage fins que F5-TTS expose
Choisissez OpenVoice lorsque F5-TTS ne correspond pas à vos contraintes — vous voulez un modèle plus petit qui fonctionne sur du matériel moins puissant, une licence plus permissive pour un usage commercial, ou une API plus simple. Le compromis de fidélité est réel mais gérable pour des cas d'utilisation non critiques (brouillons, outils internes, prototypes d'accessibilité).
Comparaison côte à côte
Les mêmes quatre dimensions à travers les trois outils. Utilisez ceci pour trianguler l'appel après avoir lu les sections par outil.
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | Voix personnalisées pour produits, livres audio, IVR, voix de personnage pour les médias | Clonage vocal auto-hébergé, équipes techniques, inférence personnalisée, génération par lots | Clone de clip unique, environnements à faibles ressources, licences permissives |
| Pricing | Facturation par caractère — niveau gratuit limité ; les plans payants commencent à environ 5 $/mois | Gratuit (auto-hébergé) — le coût du GPU est le minimum | Gratuit (licence MIT, auto-hébergé) |
| Languages | Plus de 30 langues avec une bibliothèque vocale mature | Transfert multilingue sans échantillonnage ; ajustements communautaires pour les langues à faibles ressources | 4+ langues prêtes à l'emploi ; transfert de style vocal entre elles |
| Limitation | Plateforme fermée avec des barrières de politique de contenu sur le clonage vocal (vérification du consentement requise pour les voix personnalisées) ; les coûts par caractère s'accumulent à volume élevé | Nécessite un GPU et une infrastructure d'inférence ; la prosodie peut dériver sur de longs clips (>30-45s) sans découpage ; les extrêmes expressifs (rire, cri) s'affaiblissent | Fidélité vocale inférieure à celle des leaders commerciaux ; modèle à faibles ressources, donc moins de leviers de réglage fins que F5-TTS expose |
Lequel pour quel cas d'utilisation
- Voix personnalisée pour une fonctionnalité SaaS, un livre audio ou un IVR → ElevenLabs. Mature, poli, faible surface d'ingénierie.
- Clonage vocal à grande échelle, auto-hébergé → F5-TTS. Gratuit par clip, contrôle total, GPU comme minimum.
- Environnement à faibles ressources ou licence permissive nécessaire → OpenVoice. Modèle plus léger, MIT.
- Localiser une vidéo dans une autre langue tout en conservant la voix du locuteur → passez les trois. Lisez la section suivante.
Que faire si vous n'avez pas besoin d'un *outil* de clonage vocal ?
La plupart des lecteurs atterrissant sur "meilleurs outils de clonage vocal" essaient en réalité de résoudre un problème spécifique : faire sonner une vidéo comme le locuteur original dans une autre langue. Si c'est votre cas, vous n'avez pas besoin d'un outil de clonage vocal — vous avez besoin d'un outil de doublage qui utilise le clonage vocal en interne.
Doublage vidéo Curify clone la voix du locuteur original à partir de la vidéo source, traduit l'audio, l'aligne sur le timing source, et livre une piste doublée dans la langue cible avec l'identité du locuteur préservée. Le clonage vocal est invisible — téléchargez une vidéo, choisissez une langue, obtenez un doublage. Le pipeline est construit sur la même lignée F5-TTS couverte ci-dessus ; la différence est que nous gérons l'alignement, le synchronisme labial et la génération de sous-titres autour de cela afin que vous n'ayez pas à assembler ces éléments vous-même.
Quand c'est le bon choix : localiser une vidéo YouTube, un module de cours, une démonstration de produit, un webinaire, un tutoriel.
Quand ce n'est pas le cas : cloner une voix pour une API TTS, un IVR, une narration de livre audio, ou une fonctionnalité SaaS où les utilisateurs clonent leur propre voix — pour ceux-là, restez avec ElevenLabs ou F5-TTS ci-dessus. Catégorie différente, outil différent.
Conformité à connaître avant de cloner une voix
Ce n'est pas un avis juridique — parlez à un conseiller pour votre juridiction. Cela dit, trois pratiques défendables apparaissent partout :
- Consentement et droits. Obtenez un consentement écrit explicite du propriétaire de la voix. Documentez la provenance de l'audio de référence. Les droits de publicité persistent au-delà de la mort dans certains États américains ; un conseiller peut vous aider à clarifier cela.
- Divulgation. Étiquetez les voix synthétiques ou significativement modifiées lorsque la plateforme ou la juridiction l'exige. YouTube propose un chemin de divulgation lors du téléchargement — utilisez-le.
- Précaution téléphonique. La décision déclaratoire de la FCC de 2024 a rendu les voix générées par IA dans les appels automatisés illégales en vertu du TCPA sans consentement exprès préalable. Si votre cas d'utilisation touche à la téléphonie, c'est un obstacle.
Questions fréquentes
Le clonage vocal par IA est-il légal en 2026 ?
C'est un patchwork juridictionnel. États-Unis : pas de loi fédérale contre le clonage vocal en soi, mais les lois d'État sur le droit à l'image s'appliquent pour une utilisation non consensuelle ; la décision de la FCC de 2024 rend les voix IA illégales dans les appels automatisés. UE : le RGPD considère la voix comme des données biométriques — consentement explicite requis, et vous devez divulguer l'utilisation de l'entraînement du modèle. Obtenez toujours un consentement écrit explicite du propriétaire de la voix, documentez-le et étiquetez le contenu synthétique là où la plateforme l'exige (YouTube, TikTok).
Combien d'audio ai-je besoin pour cloner une voix ?
Cela dépend du niveau. Clones instantanés (ElevenLabs Instant, OpenVoice) nécessitent 10-30 secondes d'audio de référence et vous donnent 70-80 % de fidélité. Clones professionnels (ElevenLabs Professional, F5-TTS finetune) nécessitent 30 minutes ou plus d'audio studio propre et atteignent 95 % ou plus de fidélité. Si vous clonez votre propre voix pour une introduction de podcast, le niveau instantané est suffisant. Si vous expédiez une fonctionnalité de produit, optez pour le professionnel.
Puis-je cloner la voix d'une célébrité pour un projet personnel ?
Non. Chaque plateforme réputée (ElevenLabs, Resemble, Respeecher) interdit cela dans ses conditions d'utilisation. Cela viole les lois sur le droit à l'image dans la plupart des États américains et le droit d'auteur dans de nombreuses juridictions. Même si vous auto-hébergez un modèle open-source, distribuer la sortie d'un clone de célébrité est passible de poursuites. Ne le faites pas.
Quelle est la différence entre le clonage vocal et la synthèse vocale (TTS) ?
La TTS convertit le texte écrit en parole en utilisant une voix préexistante (souvent une voix de stock sélectionnée). Le clonage vocal génère de la parole dans la voix d'une personne spécifique, capturée à partir d'un échantillon de référence. La plupart des plateformes modernes (ElevenLabs, F5-TTS) font les deux — ce sont des moteurs TTS avec le clonage comme fonctionnalité. "Outil de clonage vocal" signifie généralement "le moteur TTS que j'utilise pour cloner une voix."
Qu'est-ce que la synthèse vocale à vocale (STS) ?
Mécanique différente : vous enregistrez votre performance d'une phrase (avec votre ton, rythme, émotion), et l'outil mappe votre performance sur une voix cible différente. Utile pour le doublage où vous souhaitez que la voix doublée hérite de la livraison émotionnelle de l'acteur original. Respeecher se spécialise dans cela ; ElevenLabs et d'autres l'ont comme fonctionnalité. Problème différent du clonage vocal direct.
Je veux juste doubler une vidéo YouTube avec ma propre voix. Quel outil ?
Aucun des trois ci-dessus à lui seul — vous assembleriez un pipeline. Vous auriez besoin de : (1) extraire l'audio original, (2) cloner la voix du locuteur, (3) traduire le script, (4) générer l'audio doublé dans la voix clonée, (5) l'aligner sur le timing de la vidéo source, (6) éventuellement synchroniser les lèvres. Curify Video Dubbing fait les six étapes de bout en bout. Le clonage vocal est interne ; vous téléchargez une vidéo, choisissez une langue, obtenez un doublage. Catégorie différente de "un outil de clonage vocal."
La version courte
Trois outils, une décision : ElevenLabs si vous lancez un produit et souhaitez un rendu soigné + une surface d'ingénierie réduite ; F5-TTS si vous avez un GPU et souhaitez un coût nul par clip à grande échelle ; OpenVoice si vous avez besoin d'un modèle plus léger avec une licence permissive. Et si votre véritable problème est de doubler une vidéo avec votre propre voix, essayez Curify — le clonage vocal est automatique et vous n'avez pas à apprendre l'un des trois ci-dessus.
Take the next step
Putting what you read into practice.

