Comment traduire une vidéo YouTube en anglais : 3 méthodes en 2026
Vous tombez sur une vidéo YouTube en espagnol, japonais ou mandarin — et vous la voulez en anglais. Peut-être s'agit-il d'un tutoriel dont vous avez réellement besoin, d'un cours, d'un clip viral partagé par un ami, ou de votre propre vidéo que vous souhaitez publier pour un public plus large. En 2026, vous avez trois options réelles, et la bonne dépend de si vous regardez, apprenez ou publiez. Ce guide passe en revue les trois — sous-titres automatiques, doublage complet avec clonage vocal, et sous-titres bilingues — avec les compromis qui comptent vraiment.
Trois façons de traduire une vidéo YouTube
Il n'existe pas de "traducteur YouTube" unique car il y a trois problèmes différents cachés sous une seule phrase. (1) Vous voulez regarder une vidéo dans votre langue — résolu par des sous-titres, souvent le chemin le plus rapide. (2) Vous voulez une version publiable dans une autre langue — résolu par un doublage complet avec clonage vocal, plus lent mais plus partageable. (3) Vous voulez apprendre la langue source en regardant — résolu par des sous-titres bilingues, le point idéal pour l'apprentissage des langues.
Ce guide couvre les trois. Chaque méthode a une option gratuite ou presque gratuite pour un usage occasionnel et une option payante qui gère le polissage que vous voudriez pour la production. Choisissez par cas d'utilisation, pas par celle qui est "meilleure" — elles résolvent des problèmes différents.
Pourquoi une méthode unique ne fonctionnera pas pour tout
L'auto-traduction intégrée de YouTube est pratique mais approximative — elle gère les dialogues courants correctement et s'effondre sur les idiomes, l'argot, les accents, le jargon technique, et tout endroit où le contexte compte. Pour un clip de 5 minutes, c'est acceptable ; pour un cours de 90 minutes, la dérive cumulative le rend inregardable.
Le doublage est le commerce opposé : plus lent à produire mais plus facile à regarder. Si vous publiez pour un public qui ne lira pas les sous-titres (enfants, spectateurs plus âgés, quiconque regardant en faisant autre chose), le doublage est non négociable.
Les sous-titres bilingues sont l'arme secrète de l'apprenant en langues — montrez les deux langues empilées ensemble afin que vous lisiez la traduction tout en entendant l'original. C'est la seule méthode qui vous *enseigne* réellement la langue source pendant que vous regardez.
Les trois méthodes ci-dessous ne sont pas classées. Chacune résout un problème spécifique mieux que les deux autres.
Trois méthodes, côte à côte
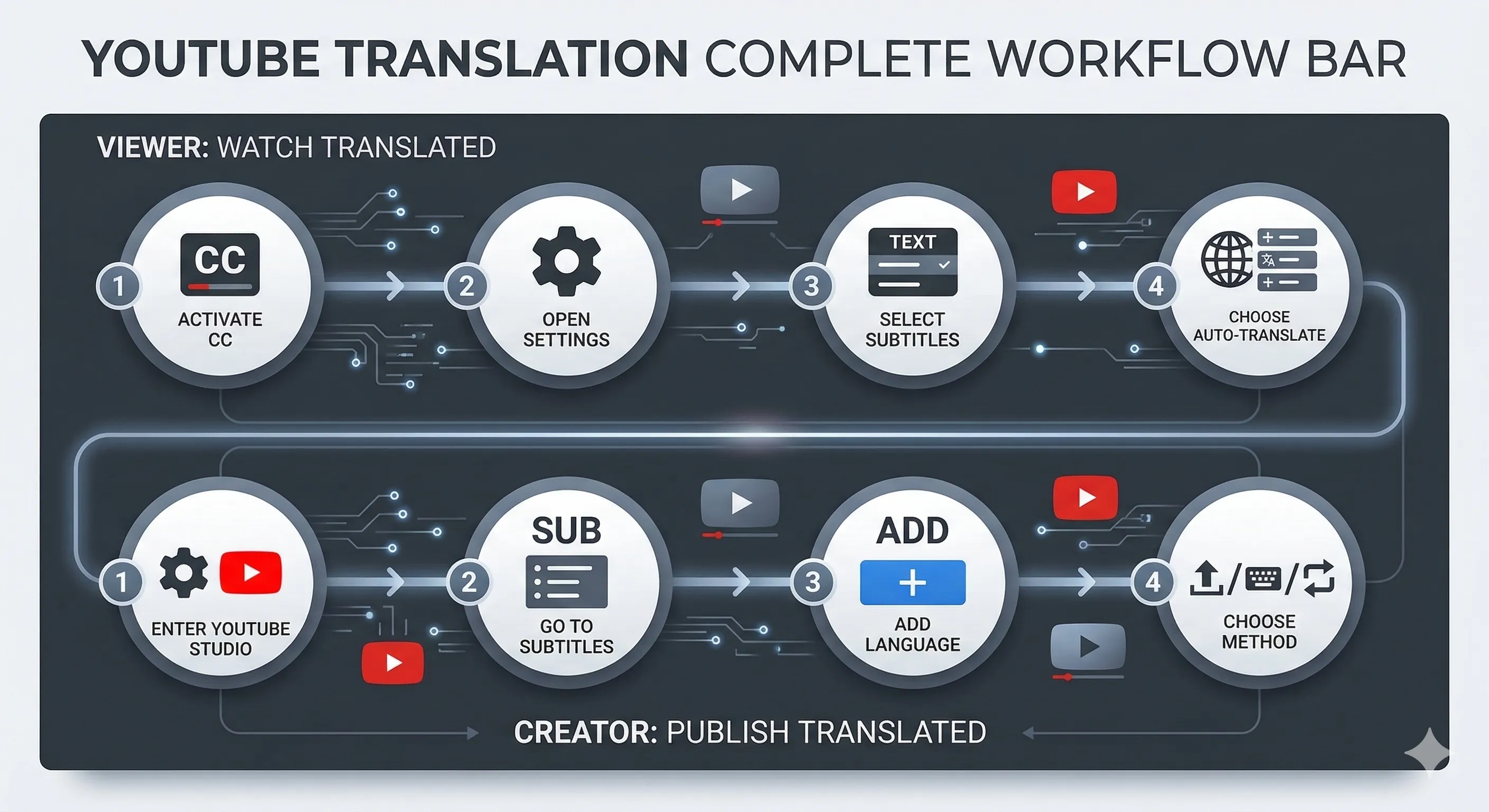
Méthode 1 : Sous-titres automatiques + Traduction par navigateur (Gratuit, le plus rapide)
Meilleur pour : regarder rapidement une seule vidéo dans une autre langue. Investissement en temps : 30 secondes.
Chaque vidéo YouTube qui a des sous-titres activés peut être auto-traduite par YouTube lui-même. Activez le bouton CC, ouvrez le paramètre → Sous-titres → Auto-traduire → Anglais. YouTube génère une traduction anglaise à la volée en utilisant le backend de traduction de Google.
Ce qui fonctionne : dialogue conversationnel dans les principales paires de langues (espagnol, français, allemand, japonais, coréen, chinois se déchiffrent bien). Le pipeline est gratuit, instantané, et fonctionne sur chaque vidéo où le créateur n'a pas désactivé les sous-titres.
Ce qui casse : jargon technique (termes de programmation, vocabulaire médical, hobbies de niche), accents prononcés, idiomes, discours rapide. Les traductions sont au niveau des mots, donc la structure des phrases peut sembler du mauvais anglais. Et sur les vidéos où le créateur a complètement désactivé les sous-titres, cette méthode ne s'applique pas du tout.
Chemin de mise à niveau : si l'auto-traduction de YouTube manque trop, collez l'URL de la vidéo dans /tools/video-transcription pour obtenir une transcription plus soignée — plus lente mais de bien meilleure qualité, surtout sur le contenu technique.
Méthode 2 : Doublage complet avec clonage vocal (Payant, partageable)
Meilleur pour : republier la vidéo dans une autre langue pour un public qui ne lira pas les sous-titres. Investissement en temps : 5-15 minutes de traitement par minute de vidéo.
Le doublage complet remplace l'audio original par une piste anglaise dans la voix de l'orateur original (clonée), puis aligne les mouvements des lèvres via le synchronisme labial afin que cela ne semble pas être un doublage. Le résultat est une vidéo regardable qui sonne comme si l'orateur avait réellement dit la version anglaise.
Le flux de travail sur Curify à /tools/video-dubbing : collez une URL YouTube ou téléchargez la vidéo, choisissez la langue cible, et le pipeline fonctionne en cinq étapes — séparez la parole de la musique de fond, transcrivez l'audio, traduisez la transcription, clonez la voix de l'orateur, et réalignez les mouvements des lèvres. Un téléchargement produit trois artefacts : l'audio doublé, la nouvelle vidéo avec des mouvements de lèvres alignés, et un fichier de sous-titres correspondant.
Ce qui fonctionne : contenu de type tête parlante filmé de face — interviews, enregistrements de cours, démonstrations de produits, vidéo de podcast. La sortie est prête à être publiée pour des séquences de tête parlante.
Ce qui casse : angles de profil (le modèle de synchronisme labial est entraîné sur des orateurs de face), barbes épaisses ou occlusions main-visage (le modèle perd la limite de la bouche), et longues pauses de bouche maintenue. Pour le B-roll de style documentaire avec l'orateur hors caméra, prévoyez de revenir à la localisation uniquement par sous-titres sur ces coupes.
Coût : paiement par minute. Une vidéo de 10 minutes de tête parlante prend à peu près le même temps total de traitement qu'un doublage manuel prendrait en heures humaines, à une petite fraction du coût.
Méthode 3 : Sous-titres bilingues (Gratuit ou Payant, Meilleur pour l'apprentissage)
Meilleur pour : les apprenants de langues, les enseignants d'ESL, les parents utilisant des vidéos pour l'exposition à une seconde langue pour les enfants. Investissement en temps : 2-5 minutes.
Les sous-titres bilingues montrent les deux langues empilées ensemble — l'original sur une ligne, la traduction anglaise directement en dessous. Vous entendez la langue source tout en lisant les deux, ce qui est la façon dont l'acquisition de la langue fonctionne réellement en pratique.
Le flux de travail Curify à /tools/bilingual-subtitles : collez une URL YouTube, choisissez les langues source et cible, et l'outil génère un fichier .srt avec les deux langues alignées sur les mêmes horodatages. Brûlez-le dans la vidéo pour un affichage permanent, ou attachez-le comme une piste de sous-titres commutable.
Pourquoi cette méthode est importante : la traduction uniquement par sous-titres supprime complètement les indices audio source. Les sous-titres bilingues les préservent. Si votre objectif est d'apprendre la langue *tout en regardant*, c'est la seule méthode qui le fait réellement. Les parents enseignant une langue d'héritage aux enfants trouvent cela particulièrement utile — l'enfant entend l'audio original et voit les deux formes écrites côte à côte.
Alternative gratuite : activez le CC dans la langue originale sur YouTube + utilisez une extension de navigateur comme Language Reactor ou Subadub pour superposer une traduction dans une seconde langue. Moins précise qu'un .srt généré, mais gratuite et fonctionne dans le navigateur sans aucun téléchargement.
Comment choisir entre les trois méthodes
Choisissez la méthode 1 (sous-titres automatiques) si vous voulez juste regarder une seule vidéo tout de suite, dans les 30 prochaines secondes, et que cela ne vous dérange pas que certaines lignes puissent être légèrement incorrectes.
Choisissez la méthode 2 (doublage complet) si vous republiez la vidéo pour un public — votre propre chaîne YouTube, une vidéo de formation interne pour une équipe mondiale, un cours que vous vendez. Partout où le spectateur ne lira pas les sous-titres.
Choisissez la méthode 3 (sous-titres bilingues) si vous apprenez la langue source, l'enseignez, ou créez du contenu pour les apprenants en langues.
Vous pouvez également les empiler : doublez les segments principaux de tête parlante (méthode 2), utilisez des sous-titres bilingues pour les sections éducatives (méthode 3), et revenez à l'auto-traduction pour le B-roll où l'orateur est hors caméra (méthode 1). Le pipeline de Curify produit les trois artefacts à partir d'un seul téléchargement, donc la même vidéo source peut servir les trois publics sans re-téléchargement.
Étape 5 : Vérification de la qualité avant de publier
Quelle que soit la méthode que vous choisissez, faites ces trois vérifications avant de publier ou de partager :
1. Vérifiez la traduction à au moins 3 horodatages aléatoires. Choisissez un près du début, un au milieu, un près de la fin. Lisez la traduction tout en écoutant l'original. Si cela semble nettement incorrect à l'un des trois, l'ensemble de la transcription a probablement le même problème — retraduisez ou acceptez la qualité.
2. Écoutez l'audio doublé (méthode 2 uniquement) pour le rythme. Si les phrases anglaises sont plus courtes ou plus longues que la source, le synchronisme labial dérivera dans une direction ou l'autre. La plupart des pipelines ajoutent automatiquement ou compressent pour compenser, mais le résultat peut sembler précipité ou étiré. Re-render avec une stratégie de rythme différente si c'est perceptible.
3. Vérifiez le synchronisme labial sur les prises de profil (méthode 2 uniquement). C'est là que le modèle échoue le plus souvent. Si un moment émotionnel clé est filmé de côté, acceptez que le synchronisme labial semblera légèrement décalé là — ou coupez à un angle différent pour cette ligne.
Pour un usage occasionnel, la méthode 1 n'a pas besoin de vérification de qualité (c'est assez bon ou ce n'est pas le cas, et vous le saurez en 10 secondes). Les méthodes 2 et 3 récompensent un scan de 2 minutes avant publication.
Comparaison des outils : Ce dont chaque méthode a besoin
| Méthode | Outil | Coût | Temps | Meilleur pour |
|---|---|---|---|---|
| Sous-titres automatiques | CC intégré de YouTube + auto-traduction | Gratuit | 30 sec | Visionnage occasionnel, vidéos uniques |
| Sous-titres automatiques (meilleur) | Curify Video Transcription | Paiement par minute | 2-5 min | Lorsque le CC de YouTube manque trop |
| Doublage complet | Curify Video Dubbing | Paiement par minute | 5-15 min/min | Republier pour des spectateurs non-lecteurs |
| Doublage complet (alternative) | ElevenLabs Voice Studio | Abonnement | Configuration manuelle | Lorsque vous avez besoin d'un contrôle vocal précis |
| Sous-titres bilingues | Curify Bilingual Subtitles | Paiement par minute | 2-5 min | Apprentissage des langues, enseignement d'ESL |
| Sous-titres bilingues (gratuits) | Language Reactor + CC YouTube | Gratuit | Extension de navigateur | Apprendre en regardant, sans production |
Les trois outils Curify partagent une seule infrastructure de pipeline — collez une URL YouTube une fois, choisissez les formats de sortie dont vous avez besoin, et le même téléchargement produit le fichier de sous-titres, l'audio doublé, ou le
.srt bilingue. Évite le ré-encodage et le re-téléchargement pour chaque format.Comment Curify réunit les trois méthodes
Les /tools/video-dubbing et /tools/bilingual-subtitles de Curify fonctionnent sur un pipeline partagé, vous pouvez donc produire toutes les sorties des trois méthodes à partir d'un seul téléchargement d'URL YouTube :
1. La transcription (chemin de mise à niveau de la méthode 1) — propre, alignée dans le temps, prête à être traduite ou remise à ChatGPT pour un passage de polissage.
2. La vidéo doublée (méthode 2) — audio traduit dans une voix clonée, alignée sur les lèvres, avec un fichier de sous-titres correspondant produit en même temps.
3. Le fichier de sous-titres bilingues (méthode 3) — langue originale + cible alignée sur les mêmes horodatages, prête à être brûlée dans la vidéo ou attachée comme une piste commutable.
Les outils partagent des entrées mais produisent des sorties différentes, vous pouvez donc adapter l'artefact au public sans re-téléchargement de la source. La tarification est par minute de vidéo source ; pas d'abonnement, pas de minimum mensuel.
Si vous voulez la vue de l'ingénieur sur le fonctionnement de chaque étape du pipeline — séparation de la source audio, traduction neuronale, clonage vocal, alignement labial — consultez la répartition de l'architecture de production à /blog/video-transcription-technical-deep-dive. Ce guide est la vue de l'utilisateur sur le même pipeline.
Choisissez la méthode, passez le pipeline
"Comment traduire une vidéo YouTube en anglais" est trois questions différentes en une. Méthode 1 (sous-titres automatiques) gère le visionnage occasionnel. Méthode 2 (doublage complet) gère la publication. Méthode 3 (sous-titres bilingues) gère l'apprentissage. Les outils pour les trois se sont considérablement améliorés depuis 2024 — ce qui nécessitait auparavant cinq scripts distincts et un GPU est maintenant un simple collage d'URL en 2026.
Le seul avertissement à prendre au sérieux : chaque pipeline de traduction AI a des cas particuliers. Accents prononcés, jargon technique, discours rapide, synchronisme labial en angle de profil — ce sont des modes de défaillance réels, pas théoriques. Vérifiez la sortie avant de vous engager à publier. La révision de 2 minutes fait la différence entre une vidéo traduite de grande qualité et une qui perd des spectateurs dans les 30 premières secondes.
Take the next step
Putting what you read into practice.
Articles Connexes
Video Translation
Traduction de vidéos YouTube par IA : Meilleurs outils, méthodes et résultats 2026
