Construire un moteur de recherche multimodal auto-améliorant avec de vraies requêtes utilisateurs chez Curify
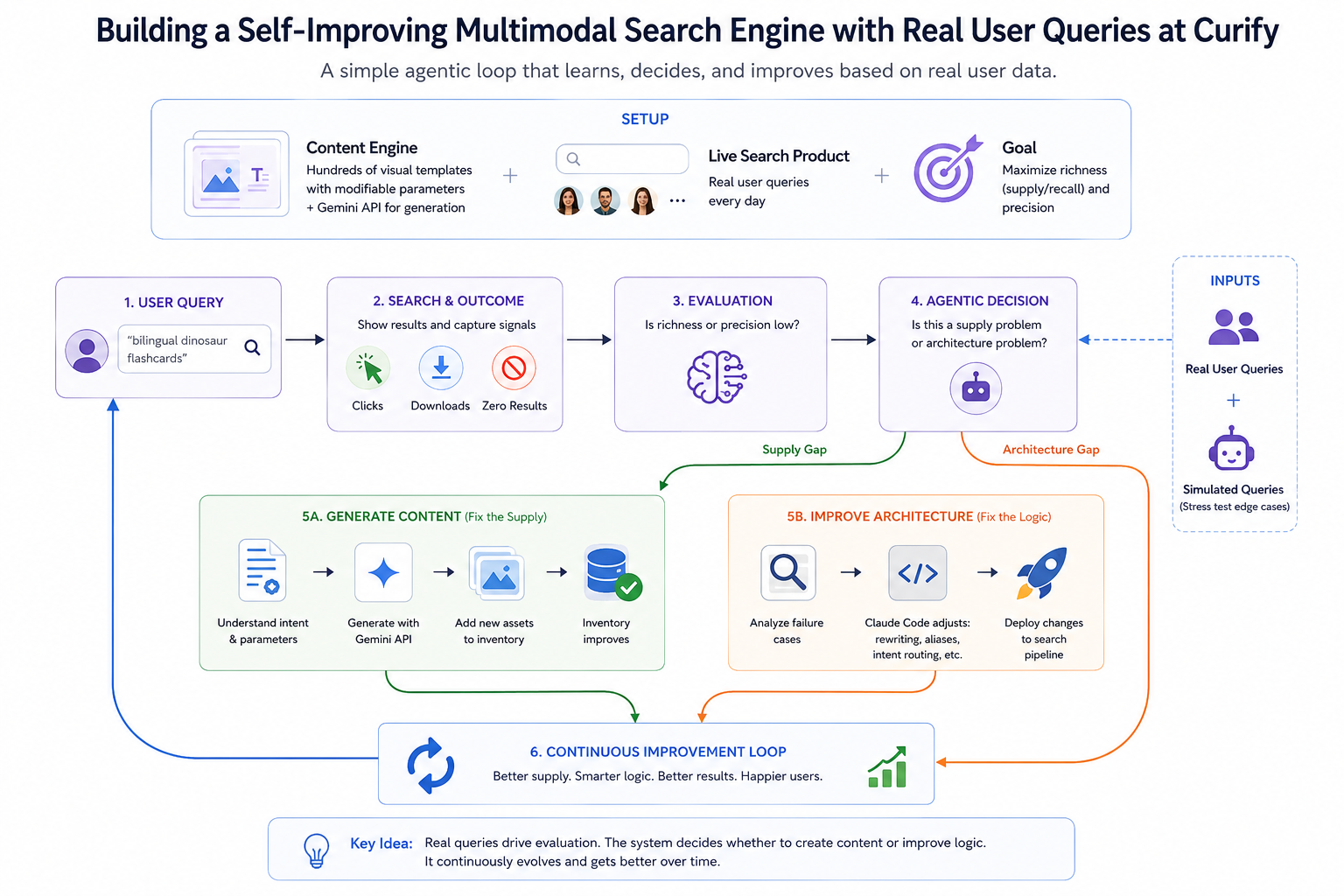
Les moteurs de recherche traditionnels sont des index statiques — ils attendent que le monde les remplisse. À l'ère des flux de travail agentiques et du "vibe coding", construire un système de recherche ne devrait pas seulement consister à optimiser BM25 ou les embeddings vectoriels ; il devrait s'agir de construire une boucle autonome qui apprend, décide et construit son propre approvisionnement. Chez Curify, nous avons récemment transformé notre barre de recherche d'un outil de récupération passif en un moteur multimodal auto-améliorant. Cet article offre un aperçu de la manière dont nous avons conçu une boucle agentique alimentée par des données réelles d'utilisateurs.
La configuration : Une chaîne d'approvisionnement dynamique
Pour comprendre le moteur, commencez par l'inventaire. Curify n'indexe pas le web ouvert — la configuration est hautement contrôlée et déterministe :
Le moteur de contenu : Des centaines de modèles visuels structurés avec des paramètres modifiables, directement connectés à l'API Gemini pour une génération d'images haute fidélité.
Le signal : Un produit de recherche en direct capturant quotidiennement de vraies requêtes utilisateurs.
L'objectif d'optimisation est simple : maximiser la *richesse* des résultats de recherche (approvisionnement / rappel) et la *précision*. Mais au lieu d'ajuster manuellement les poids, nous transformons les requêtes utilisateurs en direct en un ensemble d'évaluation dynamique et continu. Chaque requête sous-performante devient un signal d'entraînement — pas dans le sens de la descente de gradient, mais dans le sens de la décision agentique. Le pipeline réfléchit à *pourquoi* une requête a échoué et dirige vers la bonne correction.
La boucle Évaluer → Raisonner → Agir
Étape 1 : Capturer de vraies requêtes (et simuler les cas limites)
Chaque recherche sur Curify capture la requête ainsi que le résultat immédiat : clics, téléchargements ou la redoutée page sans résultat. Cela nous donne un flux de signaux réels.
Nous injectons également des réponses utilisateurs *simulées* pour tester les cas limites avant que de vrais utilisateurs ne les rencontrent — un petit générateur de trafic synthétique qui explore les coins du catalogue comme le ferait un agent piloté par un LLM. Les vraies requêtes révèlent ce dont les utilisateurs ont réellement besoin ; les requêtes simulées révèlent ce dont ils *auront* besoin en fonction des modèles que nous anticipons. Les deux alimentent le même pipeline d'évaluation.
Étape 2 : Évaluer chaque requête sous-performante
Toute requête qui génère une faible richesse ou une mauvaise précision déclenche un nœud d'évaluation. L'évaluateur combine des signaux d'engagement réels (clics, temps de consultation, téléchargements) avec des scores de pertinence jugés par Gemini pour les requêtes qui ont renvoyé des résultats mais où l'engagement est ambigu.
L'évaluateur ne se contente pas d'enregistrer l'erreur. Il pose la question agentique : *s'agit-il d'un problème d'approvisionnement ou d'un problème d'architecture ?* Ce bifurcation est le cœur de la boucle et détermine quel des deux chemins d'action se déclenche ensuite.
Étape 3 : Bifurcation de décision — Générer du contenu (corriger l'approvisionnement)
Si l'évaluation détermine que l'intention de l'utilisateur est valide (par exemple, "cartes flash bilingues de dinosaures") mais que la base de données est réellement vide, le système agit en tant que créateur autonome.
Action : Il dirige les paramètres de la requête vers le moteur de modèles, déclenche l'API Gemini et génère en lot les actifs visuels manquants — le même pipeline basé sur des modèles qui alimente les livraisons de contenu régulières, maintenant invoqué à la demande par une recherche échouée.
Au moment où le prochain utilisateur (ou agent simulé) effectue la même recherche, l'inventaire s'est réparé. Le moteur de recherche a littéralement construit ce qui manquait.
Étape 4 : Bifurcation de décision — Améliorer l'architecture (corriger la logique)
Si le contenu existe ("affiches éducatives de T-Rex") mais que la requête de l'utilisateur ("matériaux d'apprentissage jurassiques") n'a pas réussi à le faire ressortir, le moteur signale un écart architectural.
Action : C'est ici que le vibe coding montre son utilité. Au lieu qu'un développeur écrive manuellement des règles regex, nous alimentons les cas d'évaluation échoués à Claude Code et lui demandons de :
- mettre à jour les règles de réécriture de requêtes
- générer de nouvelles expansions d'alias
- affiner l'invite de routage d'intention LLM
Les ajustements architecturaux au pipeline de recherche sont expédiés en quelques minutes, entièrement basés sur les points de friction réels des utilisateurs. L'ingénieur reste dans la boucle pour examiner les différences, mais l'agent fait le brouillon contre des cas réels au lieu de spéculer sur des requêtes hypothétiques.
Ce que cela remplace
Trois modèles que la boucle remplace :
Remplissage de contenu manuel : les équipes de recherche traditionnelles maintiennent un backlog de "requêtes avec un faible rappel" et dispatchent des commandes de contenu pour combler les lacunes. Le retard est de plusieurs semaines ; beaucoup ne sont jamais comblées. La boucle agentique ferme l'écart en quelques heures.
Règles de réécriture écrites à la main : les ingénieurs de recherche écrivent des alias par mot-clé ou maintiennent des dictionnaires de racines. Nécessaire mais lent, et les règles dérivent à mesure que de nouveaux modèles de requêtes émergent. Les réécritures codées par le vibe évoluent linéairement avec le volume de cas, pas avec les heures d'ingénieur.
Ensembles d'évaluation statiques : des benchmarks de pertinence rédigés une fois et figés. Les vraies requêtes utilisateurs changent chaque semaine — un ensemble d'évaluation statique mesure la réalité du trimestre dernier. Traiter les requêtes en direct comme l'ensemble d'évaluation signifie que le système s'optimise pour ce que les utilisateurs recherchent réellement *cette semaine*.
Tools & Resources
Learn about the best tools available...
Comment l'ensemble s'assemble
Quatre composants, reliés par la couche agent :
Front-end de recherche capture les requêtes + signaux d'engagement et les expédie à l'évaluateur en temps quasi réel.
Moteur de modèles est la bibliothèque Nano Banana de Curify — des centaines de modèles visuels paramétrés que la bifurcation côté approvisionnement appelle pour générer du contenu manquant. Le même moteur qui alimente les livraisons de contenu manuelles ; la boucle devient un autre appelant.
API Gemini gère à la fois la génération d'images (côté approvisionnement) et le scoring de pertinence (côté évaluation). Une seule famille de modèles, deux rôles.
Claude Code gère les mises à jour côté architecture — règles de réécriture, expansions d'alias, invites de routage d'intention. L'agent obtient le contexte sur les cas échoués ainsi que l'état du pipeline existant, renvoie une différence, l'ingénieur examine, expédie.
Le coût d'intégration était inférieur aux attentes car le moteur de modèles et le front-end de recherche étaient déjà des systèmes autonomes. La boucle agentique est une couche de coordination au-dessus des outils que nous avions déjà — pas une réécriture — c'est pourquoi nous avons pu expédier la première version en quelques jours plutôt qu'en semaines.
La recherche comme orchestration
La recherche n'est plus seulement une question de récupération et de classement ; c'est un problème d'orchestration. En traitant les vraies requêtes utilisateurs non seulement comme des métriques mais comme des déclencheurs actifs pour un décideur agentique, nous avons construit un système qui lutte activement contre sa propre entropie.
Chez Curify, le moteur de recherche ne se contente plus de trouver du contenu. Si le contenu est manquant, il le crée. Si la logique est défaillante, il la réécrit. Le côté approvisionnement et le côté architecture s'améliorent tous deux à partir du même signal — les requêtes qui n'ont pas fonctionné hier.
C'est le modèle pour la prochaine génération de systèmes de recherche : pas des index plus grands, mais des boucles plus serrées.
Take the next step
Putting what you read into practice.
Articles Connexes
DS & AI Engineering
L'usine de contenu IA : Pourquoi les agences de marketing doivent arrêter d'acheter des outils et commencer à construire des pipelines

Des mois à des minutes : Un pipeline IA multi-modal pour l'édition éducative bilingue