Mejores herramientas de clonación de voz AI en 2026: ElevenLabs vs F5-TTS vs OpenVoice
La mayoría de las publicaciones sobre este tema enumeran más de 10 herramientas en una lista clasificada. Eso no es útil: tres herramientas cubren casi todos los casos de uso reales, y las diferencias entre ellas son marcadas. Esta guía selecciona las tres, nombra en qué es mejor cada una y señala el caso de uso común (doblar un video a otro idioma manteniendo tu voz) donde no necesitas una herramienta de clonación de voz en absoluto.
Para quién es esto
Creadores que eligen una herramienta para clonar su propia voz para narración, audiolibros o una función TTS personalizada. Equipos de producto que lanzan una capacidad de clonación de voz en un SaaS. Equipos de localización considerando opciones de código abierto vs comerciales. Si estás intentando localizar un video de YouTube a otro idioma con tu propia voz, salta a la llamada ¿Qué pasa si no necesitas una herramienta de clonación de voz?: ese es un problema diferente y una herramienta diferente.
Guía rápida de compra: lo que realmente importa
Cuatro dimensiones importan; el resto es marketing.
1. Consentimiento y legalidad (la única regla que importa primero). Clonar la voz de otra persona sin consentimiento escrito explícito es un desastre legal: el GDPR trata la voz como datos biométricos en la UE; la decisión de la FCC de 2024 la hizo ilegal en llamadas automáticas en EE. UU. Herramientas como Descript y Resemble exigen una verificación de consentimiento antes de clonar. Herramientas como F5-TTS dejan la política a tu criterio. Elige en consecuencia.
2. Modelo de precios. La facturación por carácter (ElevenLabs, AWS Polly, Azure) escala linealmente: bien para bajo volumen, doloroso a gran escala. Los planes de suscripción limitan tu gasto. El código abierto autoalojado (F5-TTS, OpenVoice) intercambia dólares por costo de GPU + tiempo de ingeniería.
3. Fidelidad de voz vs longitud de muestra. Los clones "instantáneos" necesitan de 10 a 30 segundos de audio de referencia y te dan un 70-80% de fidelidad. Los clones "profesionales" necesitan más de 30 minutos de audio limpio de estudio y alcanzan más del 95%. Elige el nivel que coincida con tu caso de uso: una introducción de podcast necesita más fidelidad que una herramienta interna.
4. Dónde vive el audio. Algunos proveedores se otorgan a sí mismos una "licencia perpetua" para usar tu voz subida para I+D del modelo. Lee la política de privacidad. Si no puedes permitir que tus datos de voz salgan de tu infraestructura, autoalojar F5-TTS o OpenVoice.
Cómo elegimos estos tres
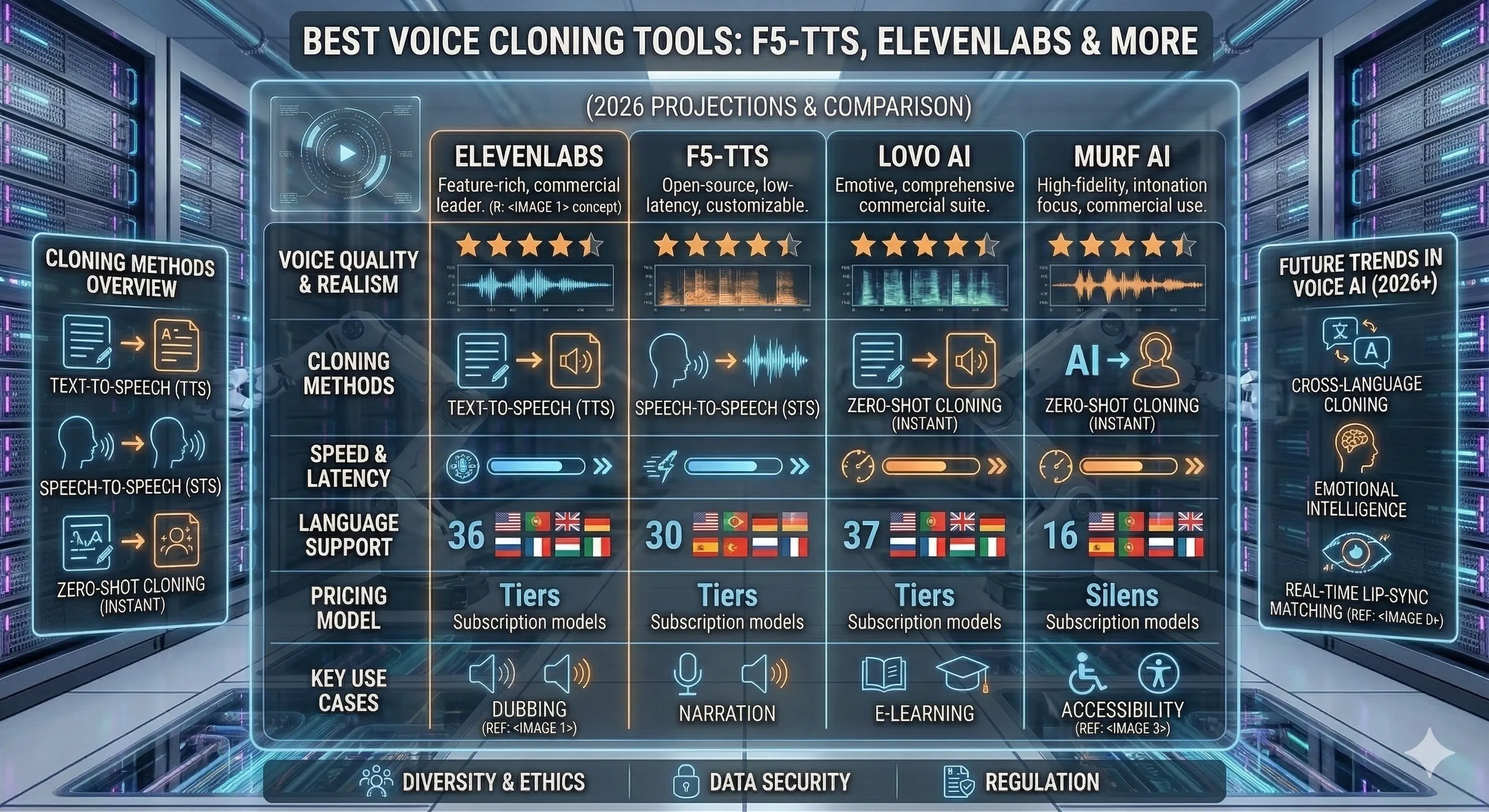
La mayoría de las listas de "mejores herramientas de clonación de voz" tienen 15 entradas porque el relleno ayuda al SEO. No estamos de acuerdo. Tres categorías cubren casi todos los casos de uso reales: pulido comercial, autoalojado de código abierto y alternativa ligera de código abierto. Eliminamos 12 herramientas que se superponen con estas tres (Murf, Play.ht, Speechify, Lovo, Listnr, TTSMaker, etc. están en la misma categoría de pulido comercial que ElevenLabs; Fish Audio, Hume, Respeecher apuntan a nichos de cine/empatía). Si quieres la lista larga, esas están a un Google de distancia. Si quieres una decisión, sigue leyendo.
Las tres herramientas que vale la pena comparar
Más allá del texto publicitario, el espacio de clonación de voz se clasifica en tres categorías: el líder comercial pulido (ElevenLabs), el caballo de batalla de código abierto (F5-TTS) y la alternativa ligera de código abierto cuando F5-TTS no encaja (OpenVoice). Cada uno tiene un lector diferente. Elige el que se ajuste a tus limitaciones.

1. ElevenLabs
El líder comercial en clonación de voz pulida
- Best for: Voces personalizadas para productos, audiolibros, IVR, voz de personaje para medios
- Pricing: Facturación por carácter: nivel gratuito limitado; los planes de pago comienzan en ~$5/mes
- Languages: Más de 30 idiomas con biblioteca de voces madura
- Notable limitation: Plataforma cerrada con políticas de contenido sobre la clonación de voz (se requiere verificación de consentimiento para voces personalizadas); los costos por carácter se acumulan a gran volumen
Elige ElevenLabs cuando necesites una herramienta de clonación de voz con los menores obstáculos de ingeniería y la mayor fidelidad base, y estés cómodo con el bloqueo de proveedor. La API y la biblioteca de voces son las más maduras en la categoría. Si estás construyendo una función de producto donde tus usuarios clonan su propia voz, este es el camino de menor resistencia.
2. F5-TTS
El caballo de batalla de código abierto, multilingüe sin disparo
- Best for: Clonación de voz autohospedada, equipos técnicos, inferencia personalizada, generación por lotes
- Pricing: Gratis (autohospedado): el costo de GPU es el mínimo
- Languages: Transferencia multilingüe sin disparo; ajustes comunitarios para idiomas de bajos recursos
- Notable limitation: Requiere una GPU y una infraestructura de inferencia; la prosodia puede desviarse en clips largos (>30-45s) sin fragmentación; los extremos expresivos (risa, gritos) se debilitan
Elige F5-TTS cuando tengas recursos de ingeniería, quieras economía de costo cero por clip a gran escala, o necesites residencia de datos / autohospedaje por cumplimiento. El modelo utiliza coincidencia de flujo con un Transformador de Difusión: competitivo con la salida comercial una vez que ajustas pasos y precisión. Repositorio de referencia: SWivid/F5-TTS; artículo de 2025 en OpenReview.
3. OpenVoice
Alternativa ligera de código abierto, licencia MIT
- Best for: Clonación de un solo clip, entornos de bajos recursos, licencias permisivas
- Pricing: Gratis (licencia MIT, autoalojado)
- Languages: Más de 4 idiomas desde el principio; transferencia de estilo de voz entre ellos
- Notable limitation: Menor fidelidad de voz que los líderes comerciales; modelo de bajos recursos, por lo que tiene menos palancas de ajuste fino que F5-TTS expone
Elige OpenVoice cuando F5-TTS no se ajuste a tus restricciones: quieres un modelo más pequeño que funcione en hardware más débil, una licencia más permisiva para uso comercial, o una API más simple. La compensación de fidelidad es real pero manejable para casos de uso no críticos (borradores, herramientas internas, prototipos de accesibilidad).
Comparación lado a lado
Las mismas cuatro dimensiones en las tres herramientas. Usa esto para triangulizar la llamada después de haber leído las cajas por herramienta.
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | Voces personalizadas para productos, audiolibros, IVR, voz de personaje para medios | Clonación de voz autohospedada, equipos técnicos, inferencia personalizada, generación por lotes | Clonación de un solo clip, entornos de bajos recursos, licencias permisivas |
| Pricing | Facturación por carácter: nivel gratuito limitado; los planes de pago comienzan en ~$5/mes | Gratis (autohospedado): el costo de GPU es el mínimo | Gratis (licencia MIT, autoalojado) |
| Languages | Más de 30 idiomas con biblioteca de voces madura | Transferencia multilingüe sin disparo; ajustes comunitarios para idiomas de bajos recursos | Más de 4 idiomas desde el principio; transferencia de estilo de voz entre ellos |
| Limitation | Plataforma cerrada con políticas de contenido sobre la clonación de voz (se requiere verificación de consentimiento para voces personalizadas); los costos por carácter se acumulan a gran volumen | Requiere una GPU y una infraestructura de inferencia; la prosodia puede desviarse en clips largos (>30-45s) sin fragmentación; los extremos expresivos (risa, gritos) se debilitan | Menor fidelidad de voz que los líderes comerciales; modelo de bajos recursos, por lo que tiene menos palancas de ajuste fino que F5-TTS expone |
Cuál para qué caso de uso
- Voz personalizada para una función SaaS, audiolibro o IVR → ElevenLabs. Maduro, pulido, bajo superficie de ingeniería.
- Clonación de voz a gran escala, autoalojado → F5-TTS. Gratis por clip, control total, GPU es el mínimo.
- Entorno de bajos recursos o licencia permisiva necesaria → OpenVoice. Modelo más ligero, MIT.
- Localizando un video en otro idioma mientras se mantiene la voz del hablante → omite las tres. Lee la siguiente sección.
¿Qué pasa si no necesitas una *herramienta* de clonación de voz?
La mayoría de los lectores que llegan a "mejores herramientas de clonación de voz" en realidad están tratando de resolver un problema específico: hacer que un video suene como el hablante original en otro idioma. Si ese eres tú, no necesitas una herramienta de clonación de voz, necesitas una herramienta de doblaje que use clonación de voz internamente.
Curify Video Dubbing clona la voz del hablante original del video fuente, traduce el audio, lo alinea con el tiempo de origen y entrega una pista doblada en el idioma objetivo con la identidad del hablante preservada. La clonación de voz es invisible: sube un video, elige un idioma, obtén un doblaje. La pipeline está construida sobre la misma línea de F5-TTS cubierta arriba; la diferencia es que manejamos la alineación, sincronización labial y generación de subtítulos para que no tengas que ensamblar esas piezas tú mismo.
Cuándo es la opción correcta: localizando un video de YouTube, un módulo de curso, una demostración de producto, un seminario web, un tutorial.
Cuándo no lo es: clonando una voz para una API de TTS, IVR, narración de audiolibros, o una función SaaS donde los usuarios clonan su propia voz; para esos, mantente con ElevenLabs o F5-TTS arriba. Diferente categoría, diferente herramienta.
Cumplimiento que debes conocer antes de clonar una voz
No es asesoría legal: habla con un abogado de tu jurisdicción. Dicho esto, tres prácticas defendibles aparecen en todas partes:
- Consentimiento y derechos. Obtén el consentimiento escrito explícito del propietario de la voz. Documenta la procedencia del audio de referencia. Los derechos de publicidad persisten más allá de la muerte en algunos estados de EE. UU.; un abogado puede aclarar esto para ti.
- Divulgación. Etiqueta voces sintéticas o significativamente alteradas donde la plataforma o jurisdicción lo requiera. YouTube proporciona un camino de divulgación durante la carga: úsalo.
- Precaución telefónica. La decisión declarativa de la FCC de EE. UU. de 2024 hizo que las voces generadas por AI en llamadas automáticas fueran ilegales bajo el TCPA sin consentimiento expreso previo. Si tu caso de uso toca la telefonía, este es el obstáculo.
Preguntas frecuentes
¿Es legal la clonación de voz por IA en 2026?
Es un mosaico jurisdiccional. EE. UU.: no hay ley federal contra la clonación de voz per se, pero las leyes estatales de derecho de publicidad entran en juego para el uso no consensuado; la decisión de la FCC de 2024 hace que las voces de IA sean ilegales en llamadas automáticas. UE: el GDPR trata la voz como datos biométricos: se requiere consentimiento explícito y debes divulgar el uso de entrenamiento del modelo. Siempre obtén consentimiento escrito explícito del propietario de la voz, documenta y etiqueta el contenido sintético donde la plataforma lo requiera (YouTube, TikTok).
¿Cuánto audio necesito para clonar una voz?
Depende del nivel. Clones instantáneos (ElevenLabs Instant, OpenVoice) necesitan de 10 a 30 segundos de audio de referencia y te dan un 70-80% de fidelidad. Clones profesionales (ElevenLabs Professional, F5-TTS finetune) necesitan más de 30 minutos de audio limpio de estudio y alcanzan más del 95% de fidelidad. Si estás clonando tu propia voz para una introducción de podcast, el nivel instantáneo está bien. Si estás lanzando una función de producto, elige profesional.
¿Puedo clonar la voz de una celebridad para un proyecto personal?
No. Cada plataforma reputada (ElevenLabs, Resemble, Respeecher) prohíbe esto en sus TOS. Viola las leyes de derecho de publicidad en la mayoría de los estados de EE. UU. y derechos de autor en muchas jurisdicciones. Incluso si autoalojas un modelo de código abierto, distribuir la salida de un clon de celebridad es procesable. No lo hagas.
¿Cuál es la diferencia entre la clonación de voz y el texto a voz (TTS)?
TTS convierte texto escrito en habla usando una voz preexistente (a menudo una voz de stock curada). La clonación de voz genera habla en la voz de una persona específica, capturada de una muestra de referencia. La mayoría de las plataformas modernas (ElevenLabs, F5-TTS) hacen ambas cosas: son motores TTS con la clonación como una característica. "Herramienta de clonación de voz" generalmente significa "el motor TTS que estoy usando para clonar una voz."
¿Qué es el habla a habla (STS)?
Mecánica diferente: grabas tu voz interpretando una línea (con tu tono, ritmo, emoción), y la herramienta mapea tu interpretación a una voz objetivo diferente. Útil para doblaje donde quieres que la voz doblada herede la entrega emocional del actor original. Respeecher se especializa en esto; ElevenLabs y otros lo tienen como una característica. Problema diferente de la clonación de voz directa.
Solo quiero doblar un video de YouTube en mi propia voz. ¿Qué herramienta?
Ninguna de las tres anteriores por sí sola: estarías ensamblando un pipeline. Necesitarías: (1) extraer el audio original, (2) clonar la voz del hablante, (3) traducir el guion, (4) generar audio doblado en la voz clonada, (5) alinearlo con el tiempo del video original, (6) opcionalmente sincronizar los labios. Curify Video Dubbing hace los seis pasos de principio a fin. La clonación de voz es interna; subes un video, eliges un idioma, obtienes un doblaje. Categoría diferente de "una herramienta de clonación de voz."
La versión corta
Tres herramientas, una decisión: ElevenLabs si estás lanzando un producto y quieres pulido + bajo esfuerzo de ingeniería; F5-TTS si tienes una GPU y quieres costo cero por clip a gran escala; OpenVoice si necesitas un modelo más ligero con licencias permisivas. Y si tu verdadero problema es doblar un video con tu propia voz, prueba Curify: la clonación de voz es automática y no tienes que aprender ninguna de las tres anteriores.
Take the next step
Putting what you read into practice.

