Best AI Voice Cloning Tools in 2026: ElevenLabs vs F5-TTS vs OpenVoice
Cloning a voice used to take a Hollywood studio and thousands of dollars. Today it takes 30 seconds and a $5/month plan. That's a creative gift for podcasters, video makers, and product teams — and a scam vector that's already cost real people millions. This guide picks the three tools you actually need to know (most listicles pad to 15), what each is good for, the consent rules you can't skip, and one common case where you should skip a voice cloning tool entirely.
Who this is for
Creators picking a tool to clone their own voice for narration, audiobooks, or a custom TTS feature. Product teams shipping a voice cloning capability in a SaaS. Localization teams considering open-source vs commercial. If you're trying to localize a YouTube video into another language with your own voice, skip ahead to the What if you don't need a voice cloning tool? callout — that's a different problem and a different tool.
Quick buyer's guide — what actually matters
Four dimensions matter; the rest is marketing copy.
1. Consent & legality (the only rule that matters first). Cloning someone else's voice without explicit written consent is a legal disaster — GDPR treats voice as biometric data in the EU; the FCC's 2024 ruling made it illegal in U.S. robocalls. Tools like Descript and Resemble force a consent check before cloning. Tools like F5-TTS leave the policy to you. Pick accordingly.
2. Pricing model. Per-character billing (ElevenLabs, AWS Polly, Azure) scales linearly — fine for low volume, painful at scale. Subscription plans cap your spend. Open-source self-hosted (F5-TTS, OpenVoice) trades dollars for GPU cost + engineering time.
3. Voice fidelity vs sample length. "Instant" clones need 10-30 seconds of reference audio and give you 70-80% fidelity. "Professional" clones need 30+ minutes of clean studio audio and reach 95%+. Pick the tier that matches your use case — a podcast intro needs more fidelity than an internal tool.
4. Where the audio lives. Some vendors grant themselves a "perpetual license" to use your uploaded voice for model R&D. Read the privacy policy. If you can't have your voice data leave your infrastructure, self-host F5-TTS or OpenVoice.
How we picked these three
Most "best voice cloning tools" lists are 15 entries long because padding helps SEO. We disagree. Three buckets cover almost every real use case — commercial polish, open-source self-host, and lightweight open-source alternative. We dropped 12 tools that overlap with these three (Murf, Play.ht, Speechify, Lovo, Listnr, TTSMaker, etc. all sit in the same commercial-polish bucket as ElevenLabs; Fish Audio, Hume, Respeecher target film/empathic niches). If you want the long listicle, those are a Google search away. If you want a decision, read on.
The three tools worth comparing
Past the marketing copy, the voice-cloning space sorts into three buckets: the polished commercial leader (ElevenLabs), the open-source workhorse (F5-TTS), and the lightweight open-source alternative when F5-TTS doesn't fit (OpenVoice). Each owns a different reader. Pick the one that matches your constraints.

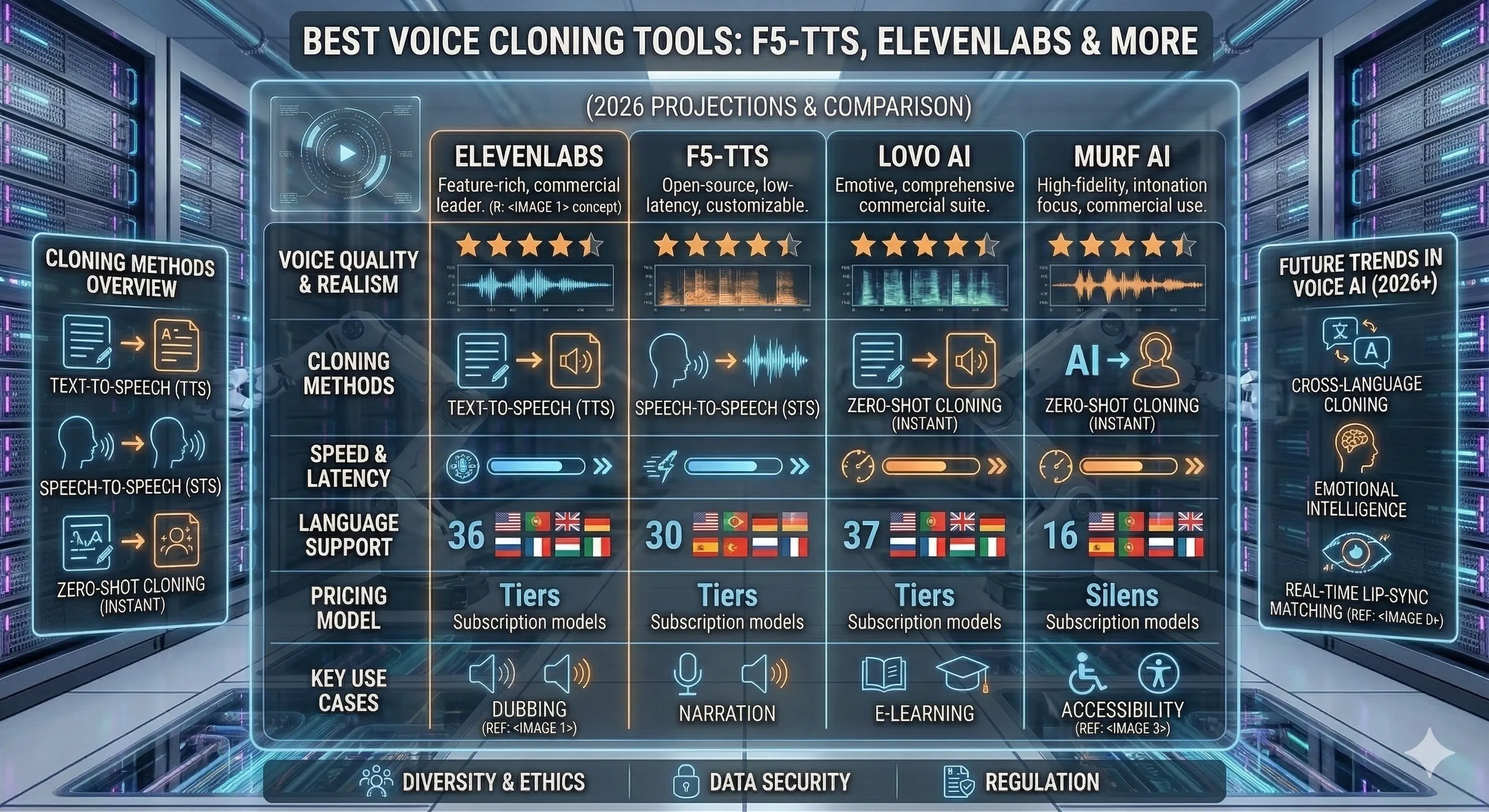
1. ElevenLabs
The commercial leader for polished voice cloning
- Best for: Custom voices for products, audiobooks, IVR, character voice for media
- Pricing: Per-character billing — free tier limited; paid plans start ~$5/mo
- Languages: 30+ languages with mature voice library
- Notable limitation: Closed platform with content-policy gates on voice cloning (consent verification required for custom voices); per-character costs add up at high volume
Pick ElevenLabs when you need a voice cloning tool with the fewest engineering hurdles and the highest baseline fidelity, and you're comfortable with vendor lock-in. The API and voice library are the most mature in the category. If you're building a product feature where your users clone their own voice, this is the path of least resistance.
2. F5-TTS
The open-source workhorse, zero-shot multilingual
- Best for: Self-hosted voice cloning, technical teams, custom inference, batch generation
- Pricing: Free (self-hosted) — GPU cost is the floor
- Languages: Multilingual zero-shot transfer; community finetunes for low-resource languages
- Notable limitation: Requires a GPU and inference infrastructure; prosody can drift on long clips (>30-45s) without chunking; expressive extremes (laughter, shouting) weaken
Pick F5-TTS when you have engineering resources, want zero-cost-per-clip economics at scale, or need data residency / self-hosting for compliance. The model uses flow-matching with a Diffusion Transformer — competitive with commercial output once you tune steps and precision. Reference repo: SWivid/F5-TTS; 2025 paper on OpenReview.
3. OpenVoice
Lightweight open-source alternative, MIT license
- Best for: Single-clip clone, lower-resource environments, permissive licensing
- Pricing: Free (MIT license, self-hosted)
- Languages: 4+ languages out of the box; voice style transfer across them
- Notable limitation: Smaller voice fidelity than commercial leaders; lower-resource model, so fewer of the finetuning levers F5-TTS exposes
Pick OpenVoice when F5-TTS doesn't fit your constraints — you want a smaller model that runs on weaker hardware, a more permissive license for commercial use, or the simpler API. The fidelity tradeoff is real but manageable for non-hero use cases (rough drafts, internal tools, accessibility prototypes).
Side-by-side
The same four dimensions across the three tools. Use this to triangulate the call after you've read the per-tool boxes.
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | Custom voices for products, audiobooks, IVR, character voice for media | Self-hosted voice cloning, technical teams, custom inference, batch generation | Single-clip clone, lower-resource environments, permissive licensing |
| Pricing | Per-character billing — free tier limited; paid plans start ~$5/mo | Free (self-hosted) — GPU cost is the floor | Free (MIT license, self-hosted) |
| Languages | 30+ languages with mature voice library | Multilingual zero-shot transfer; community finetunes for low-resource languages | 4+ languages out of the box; voice style transfer across them |
| Limitation | Closed platform with content-policy gates on voice cloning (consent verification required for custom voices); per-character costs add up at high volume | Requires a GPU and inference infrastructure; prosody can drift on long clips (>30-45s) without chunking; expressive extremes (laughter, shouting) weaken | Smaller voice fidelity than commercial leaders; lower-resource model, so fewer of the finetuning levers F5-TTS exposes |
Which one for which use case
- Custom voice for a SaaS feature, audiobook, or IVR → ElevenLabs. Mature, polished, low engineering surface.
- Voice cloning at scale, self-hosted → F5-TTS. Free per clip, full control, GPU is the floor.
- Lower-resource environment or permissive license needed → OpenVoice. Lighter model, MIT.
- Localizing a video into another language while keeping the speaker's voice → skip all three. Read the next section.
What if you don't need a voice cloning *tool*?
Most readers landing on "best voice cloning tools" are actually trying to solve one specific problem: make a video sound like the original speaker in another language. If that's you, you don't need a voice cloning tool — you need a dubbing tool that uses voice cloning internally.
Curify Video Dubbing clones the original speaker's voice from the source video, translates the audio, aligns it to the source timing, and ships a dubbed track in the target language with the speaker's identity preserved. The voice cloning is invisible — upload a video, pick a language, get a dub. The pipeline is built on the same F5-TTS lineage covered above; the difference is we handle alignment, lip-sync, and subtitle generation around it so you don't have to assemble those pieces yourself.
When this is the right fit: localizing a YouTube video, a course module, a product demo, a webinar, a tutorial.
When it's not: cloning a voice for a TTS API, IVR, audiobook narration, or a SaaS feature where users clone their own voice — for those, stick with ElevenLabs or F5-TTS above. Different category, different tool.
Compliance worth knowing before you clone a voice
Not legal advice — talk to counsel for your jurisdiction. That said, three defensible practices show up everywhere:
- Consent and rights. Get explicit written consent from the voice owner. Document the provenance of the reference audio. Rights of publicity persist beyond death in some U.S. states; counsel can scope this for you.
- Disclosure. Label synthetic or meaningfully altered voices where the platform or jurisdiction requires it. YouTube provides a disclosure path during upload — use it.
- Telephony caution. The U.S. FCC's 2024 declaratory ruling made AI-generated voices in robocalls illegal under the TCPA without prior express consent. If your use case touches telephony, this is the blocker.
Frequently asked questions
Is AI voice cloning legal in 2026?
It's a jurisdictional patchwork. U.S.: no federal law against voice cloning per se, but state right-of-publicity laws kick in for non-consensual use; the FCC's 2024 ruling makes AI voices illegal in robocalls. EU: GDPR treats voice as biometric data — explicit consent required, and you have to disclose model training use. Always get explicit written consent from the voice owner, document it, and label synthetic content where the platform requires (YouTube, TikTok).
How much audio do I need to clone a voice?
Depends on the tier. Instant clones (ElevenLabs Instant, OpenVoice) need 10-30 seconds of reference audio and give you 70-80% fidelity. Professional clones (ElevenLabs Professional, F5-TTS finetune) need 30+ minutes of clean studio audio and reach 95%+ fidelity. If you're cloning your own voice for a podcast intro, instant tier is fine. If you're shipping a product feature, go professional.
Can I clone a celebrity's voice for a personal project?
No. Every reputable platform (ElevenLabs, Resemble, Respeecher) bans this in their TOS. It violates right-of-publicity laws in most U.S. states and copyright in many jurisdictions. Even if you self-host an open-source model, distributing the output of a celebrity clone is actionable. Don't do it.
What's the difference between voice cloning and text-to-speech (TTS)?
TTS converts written text into speech using a pre-existing voice (often a curated stock voice). Voice cloning generates speech in a specific person's voice, captured from a reference sample. Most modern platforms (ElevenLabs, F5-TTS) do both — they're TTS engines with cloning as a feature. "Voice cloning tool" usually means "the TTS engine I'm using to clone a voice."
What's speech-to-speech (STS)?
Different mechanic: you record yourself performing a line (with your tone, pacing, emotion), and the tool maps your performance onto a different target voice. Useful for dubbing where you want the dubbed voice to inherit the original actor's emotional delivery. Respeecher specializes in this; ElevenLabs and others have it as a feature. Different problem from straight voice cloning.
I just want to dub a YouTube video in my own voice. Which tool?
None of the three above on their own — you'd be assembling a pipeline. You'd need: (1) extract the original audio, (2) clone the speaker's voice, (3) translate the script, (4) generate dubbed audio in the cloned voice, (5) align it to the source video timing, (6) optionally lip-sync. Curify Video Dubbing does all six steps end-to-end. Voice cloning is internal; you upload a video, pick a language, get a dub. Different category from "a voice cloning tool".
The short version
Three tools, one decision: ElevenLabs if you're shipping a product and want polish + low engineering surface; F5-TTS if you have a GPU and want zero cost per clip at scale; OpenVoice if you need a lighter model with permissive licensing. And if your real problem is dubbing a video in your own voice, try Curify — the voice cloning is automatic and you don't have to learn any of the three above.
Take the next step
Putting what you read into practice.
Browse related topics
More templates and prompts in these areas.

