Emotion TTS Film: Lassen Sie Ihre Narrative emotionaler klingen

Verwandeln Sie flache Narrative in emotionale Meisterwerke
Was wäre, wenn Ihre Videoerzählung nicht nur Informationen, sondern auch echte Emotionen vermitteln könnte? Unser emotionsverbessertes TTS-Tool nimmt vorhandene Videoinhalte und verstärkt sie mit energiegeladener, emotional ausdrucksvoller Sprachsynthese. Mit der fortschrittlichen SSML-Auszeichnung von Azure Cognitive Services und der Transkription von ElevenLabs verwandelt dieses Tool flache, monotone Erzählungen in fesselnde, emotional resonante Darbietungen, die das Publikum begeistern.
Was dieses Emotion Enhancement Tool tut
Dieses Python-Tool stellt einen Durchbruch in der Audio-Nachbearbeitung dar - es extrahiert Audio aus vorhandenen Videos, transkribiert es präzise und synthetisiert dann jedes Segment mit emotionaler Intelligenz neu. Das Ergebnis ist eine neue Audiospur, die perfekten Lippen-Sync beibehält und gleichzeitig dramatischen Ausdruck, Energie und emotionale Nuancen hinzufügt, die mit traditionellen TTS-Systemen unmöglich waren.
🎭 Kernfähigkeiten
Wie die Emotion Pipeline funktioniert
Das Tool folgt einem ausgeklügelten sechs Schritte umfassenden Prozess, der flache Erzählungen in emotional ansprechende Darbietungen verwandelt und dabei perfekte technische Synchronisation aufrechterhält.
📥Audioextraktion
Extrahieren Sie qualitativ hochwertiges Audio aus vorhandenen MP4-Videos mit MoviePy und bewahren Sie die ursprüngliche Zeit und Qualität.
Audioextraktionsprozess
Verwendet MoviePy, um PCM-Audio mit den richtigen Codec-Einstellungen für maximale Kompatibilität zu extrahieren.
clip = VideoFileClip(video_path) clip.audio.write_audiofile(audio_path, codec='pcm_s16le', logger=None)
📝Intelligente Transkription
ElevenLabs Scribe bietet zeitliche Markierungen auf Wortebene und Zeichenerkennung für präzise Segmentierung.
Transkriptions-API
Direkte API-Integration mit zeitlichen Markierungen auf Wortebene und automatischer Zeichenerkennung.
resp = requests.post(ELEVENLABS_URL, headers={'xi-api-key': ELEVENLABS_KEY}, files={'file': ('audio.wav', f, 'audio/wav')}, data={'model_id': 'scribe_v1'})🎭Emotionale SSML-Erstellung
Konvertieren Sie Textsegmente in SSML mit ausdrucksvoller Auszeichnung für energiegeladene Lieferstile.
SSML-Generierung
Erstellt SSML im Stil 'advertisement_upbeat', mit Steuerungen für Geschwindigkeit/Höhe/Lautstärke für emotionalen Ausdruck.
def build_emotional_ssml(text: str) -> str:
return f'''<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts='https://www.w3.org/2001/mstts' xml:lang='en-US'>
<voice name='{voice}'>
<mstts:express-as style='advertisement_upbeat' styledegree='2'>
<prosody rate='+15%' pitch='+8%' volume='+15%'>
{escaped}
</prosody>
</mstts:express-as>
</voice>
</speak>'''🔊Azure TTS-Synthese
Azure Cognitive Services erzeugt qualitativ hochwertiges emotionales Audio mit natürlicher Prosodie und Ausdruck.
Azure TTS-API
Verwendet Azures neuronale TTS mit SSML-Unterstützung für ausdrucksvolle Sprachsynthese.
headers = {'Ocp-Apim-Subscription-Key': AZURE_API_KEY, 'Content-Type': 'application/ssml+xml', 'X-Microsoft-OutputFormat': 'riff-24khz-16bit-mono-pcm'}
resp = requests.post(AZURE_TTS_URL, headers=headers, data=ssml.encode('utf-8'), timeout=30)🔗Audio-Konkatenation
Kombinieren Sie einzelne emotionale Segmente zu einer einzigen kontinuierlichen Audiospur.
WAV-Konkatenation
Bewahrt Audio-Parameter bei der Konkatenation mehrerer WAV-Dateien in der endgültigen Spur.
def concat_wavs(wav_paths: list[str], out_path: str) -> None:
params = None
frames = []
for p in wav_paths:
if not os.path.exists(p):
continue
with wave.open(p, 'rb') as wf:
if params is None:
params = wf.getparams()
frames.append(wf.readframes(wf.getnframes()))
if not frames:
logger.warning('Keine WAV-Frames zum Konkatenieren.')
return
with wave.open(out_path, 'wb') as out_wf:
out_wf.setparams(params)
for f in frames:
out_wf.writeframes(f)🎬Video-Muxing
Ersetze den Originalton durch eine emotionale Spur, während die Videoqualität erhalten bleibt.
FFmpeg-Integration
Verwendet FFmpeg für professionelles Video-/Audio-Muxing mit automatischer Daueranpassung.
cmd = ['ffmpeg', '-y', '-i', video_path, '-i', audio_path, '-map', '0:v:0', '-map', '1:a:0', '-c:v', 'copy', '-c:a', 'aac', '-b:a', '192k', '-shortest', out_path]
Die Wissenschaft der emotionalen Sprache
Traditionelle TTS-Systeme erzeugen flache, monotone Sprache, die das Publikum nicht anspricht. Unsere Emotionserweiterung nutzt modernste SSML-Markup und Azures neuronales TTS, um Aufführungen mit natürlicher emotionaler Variation, dynamischem Bereich und ausdrucksvoller Lieferung zu schaffen, die professionellem Voice Acting entspricht.
🎯 SSML-Markup für Ausdruck
Werbung Optimistische Stil
<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts='https://www.w3.org/2001/mstts' xml:lang='de-DE'>
<voice name='de-DE-AndrewNeural'>
<mstts:express-as style='advertisement_upbeat' styledegree='2'>
<prosody rate='+15%' pitch='+8%' volume='+15%'>
Ihr emotionaler Text hier
</prosody>
</mstts:express-as>
</voice>
</speak>- •styledegree: Steuert die Intensitätsstufe (0-2, höher = ausdrucksvoller)
- •rate: Anpassung der Sprechgeschwindigkeit (-100% bis +100%)
- •pitch: Tonhöhenänderung für emotionale Betonung (-50% bis +50%)
- •volume: Lautstärkeregelung für Wirkung (0% bis +100%)
🔊 Andrew Neural - Hochenergetische Stimme
- •Natürlich ausdrucksvoller Ton, perfekt für Werbung und Aufregung
- •Unterstützt den Stil advertisement_upbeat für maximale Energie
- •Integrierte Prosodie-Kontrollen für fein abgestimmte emotionale Lieferung
- •Optimiert für fesselnde, wirkungsvolle Inhalte
Technische Architektur
🧠 KI-Komponenten
- •Azure Cognitive Services TTS mit SSML-Unterstützung
- •ElevenLabs Scribe für Transkription auf Wortebene
- •Intelligente Textsegmentierung mit Grenzerkennung
- •Generierung emotionaler Markups mit Stilkontrollen
- •Professionelle Audioverarbeitung und Verkettung
⚙️ Verarbeitungspipeline
- •MoviePy-Audioextraktion mit Codec-Optimierung
- •Echtzeit-Transkription mit Zeitstempeln auf Wortebene
- •SSML-Erstellung mit ausdrucksvollen Prosodie-Kontrollen
- •Azure TTS-Synthese mit neuronalen Sprachmodellen
- •WAV-Verkettung unter Beibehaltung der Audioparameter
- •FFmpeg Video-/Audio-Muxing mit automatischer Daueranpassung
Anwendungen in der realen Welt
🎬 Film- & Videoproduktion
Verwandle die Erzählung von Dokumentarfilmen von flacher Lieferung zu emotional fesselnden Aufführungen.
- • Verbesserung der Dokumentarfilm-Synchronisation für dramatische Wirkung
- • Bildungsinhalte mit fesselnder emotionaler Lieferung
- • Marketingvideos mit energiegeladener, überzeugender Erzählung
📚 Bildungsinhalte
Erstelle fesselnde Lernmaterialien mit ausdrucksvoller, emotional resonanter Erzählung.
- • Online-Kursvideos mit dynamischer emotionaler Betonung
- • Bildungsinhalte für Kinder mit ausdrucksvoller Erzählweise
- • Unterweisungsvideos für Unternehmen mit fesselnder emotionaler Variation
🎮 Gaming & Interaktive Medien
Füge der Spielnarration und den Charakterstimmen emotionale Tiefe hinzu.
- • Charakterstimmen mit emotionaler Bandbreite und Ausdruck
- • Interaktive Geschichtenerzählung mit dynamischer emotionaler Lieferung
- • Spielanleitungsvideos mit fesselnder emotionaler Betonung
🎭 Digitale Geschichtenerzählung
Erstelle Hörbücher und Geschichten mit professionellen emotionalen Aufführungen.
- • Hörbuchproduktion mit emotionalem Ausdruck der Charaktere
- • Podcast-Verbesserung mit fesselnder emotionaler Lieferung
- • Digitale Geschichtenerzählung mit dynamischer emotionaler Variation
Beispiel für die Kernimplementierung
Hier ist die grundlegende Code-Struktur, die die Emotionserweiterung antreibt:
def main():
if not AZURE_API_KEY:
logger.error('AZURE_AI_API_KEY not set. Check curify_background/.env')
sys.exit(1)
# Step 1: Extract audio
if not os.path.exists(AUDIO_PATH):
if not extract_audio(VIDEO_PATH, AUDIO_PATH):
sys.exit(1)
# Step 2: Transcribe
segments = transcribe(AUDIO_PATH)
# Step 3: TTS per segment
wav_paths: list[str] = []
for i, seg in enumerate(segments):
text = seg['text'].strip()
if not text:
continue
out_path = os.path.join(OUTPUT_DIR, f'segment_{i:03d}.wav')
if os.path.exists(out_path):
logger.info('[%02d] Segment WAV already exists, skipping TTS.', i)
wav_paths.append(out_path)
continue
ssml = build_emotional_ssml(text)
logger.info('[%02d] Generating TTS: %s…', i, text[:60])
if azure_tts(ssml, out_path):
wav_paths.append(out_path)
# Step 4: Concatenate
if not wav_paths:
logger.error('No segments synthesised.')
sys.exit(1)
concat_wavs(wav_paths, FULL_WAV)
# Step 5: Mux onto original video
if not mux_audio_video(VIDEO_PATH, FULL_WAV, OUTPUT_MP4):
sys.exit(1)
logger.info('All done!')Warum emotionale Verbesserung funktioniert
Wesentliche Vorteile
- ✓Perfekte Lippen-Synchronisation mit der Originalvideo-Zeit
- ✓Natürlicher emotionaler Ausdruck und Variation
- ✓Hochwertige neuronale TTS-Synthese
- ✓Intelligente Textsegmentierung und Grenzerkennung
- ✓Professionelle Audioverarbeitungspipeline
- ✓Batch-Verarbeitung mit konsistenter emotionaler Lieferung
Erste Schritte
Schnellstartanleitung
⚠️ Systemanforderungen
- •Azure AI API-Schlüssel mit Zugriff auf Cognitive Services
- •ElevenLabs API-Schlüssel für Transkriptionsdienste
- •Python 3.7+ mit MoviePy- und Requests-Bibliotheken
- •FFmpeg installiert und im PATH verfügbar
- •Vorhandenes MP4-Video zur Audioextraktion
- •Ausreichend Speicherplatz für Zwischen-Audiodateien
Erwartete Ergebnisse
Das Tool produziert emotional verbesserte Videos, die perfekte technische Qualität beibehalten und gleichzeitig dramatische Ausdruckskraft hinzufügen.
🎭 Emotionaler Audioausgang
Hochenergetischer, ausdrucksstarker Audio mit natürlicher Prosodie und emotionaler Variation
Azure neuronale TTS, SSML-Markup, 24kHz/16bit PCM WAV-Format
🎬 Technische Spezifikationen
Professionelle Videoausgabe mit verbessertem Audiotrack und perfekter Synchronisation
H.264 Video-Codec, AAC Audio-Codierung, automatische Daueranpassung
Zukunft der emotionalen Verbesserung
Wir erweitern die emotionalen Fähigkeiten mit fortschrittlichen Sprachprofilen, Echtzeit-Emotionserkennung und Integration in Video-Editing-Workflows für nahtlose Inhaltserstellung.
Demnächst
Verwandte Artikel
Creator Tools
Mini-Tool: Bilder in narrative Videos umwandeln
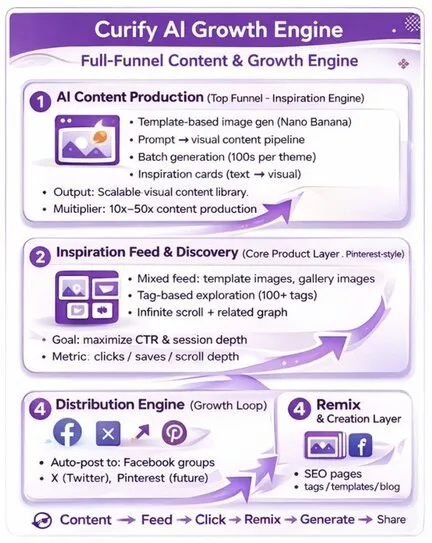
The Curify AI Growth Engine: Transforming Content Creation for UGC Creators and Marketers
