Der Leitfaden für mittelständische Unternehmen zum KI-Erfolg
Wie man eine KI-Plattform aufbaut, die mitwächst, ohne das Budget zu sprengen
Wie man eine KI-Plattform aufbaut, die mitwächst, ohne das Budget zu sprengen
- Laut der Gartner-Umfrage zur KI-Adoption 2024 haben 67 % der mittelgroßen Technologieunternehmen KI in mindestens einem Geschäftsprozess implementiert, was einem Anstieg von 22 Prozentpunkten gegenüber 2023 entspricht.
- Unternehmen, die eine Drei-Schichten-Architektur (Model Gateway, Knowledge-as-a-Service, Orchestrierungsschicht) verwenden, setzen KI 3-4x schneller mit 60 % niedrigeren Kosten als traditionelle Methoden ein.
- Die Forschung des McKinsey Global Institute 2024 zeigt, dass Unternehmen, die auf Feinabstimmung verzichten und einen 'Engineering-First'-Ansatz verwenden, 45 % höhere ROI erzielen als Unternehmen, die von Feinabstimmungen abhängig sind.
- Unternehmen, die Self-Service-KI-Plattformen aufbauen, sehen 2,8x Effizienzgewinne in der Entwicklung und 35 % niedrigere Kundenakquisitionskosten (CAC).
Bei kleinen und mittelständischen Technologieunternehmen liegt der wahre Vorteil nicht im Training riesiger Modelle, sondern im Aufbau einer KI-Plattform, die es jedem ermöglicht, intelligente Funktionen zu erstellen. So verwandeln Sie Agilität in Wirkung.
Hier ist ein praxisnaher, produktionsreiter Ansatz, den wir erfolgreich in den Bereichen Finanzen, Recht, Kundensupport und Technik eingesetzt haben – ohne das Budget zu sprengen oder 50 ML-Experten einzustellen.
Der echte Wettbewerbsvorteil kommt nicht von der Ausbildung leistungsstärkerer Modelle, sondern von der Entwicklung einer KI-Plattform, die es Teams ermöglicht, schnell intelligente Funktionen zu entwickeln. Dieser Artikel, basierend auf den praktischen Erfahrungen von Curify AI, bietet einen bewährten, reproduzierbaren Bauplan für den Aufbau einer KI-Plattform, um mittelständischen Technologieunternehmen zu helfen, in 4-6 Wochen von Experimenten zur Produktion überzugehen.
1. Die Denkweise: Demokratisieren statt zentralisieren
Die KI-Teams vieler mittelständischer Technologieunternehmen werden zu Engpässen – jede geschäftliche Anforderung muss auf die Antwort der KI-Ingenieure warten. Laut der Gartner-Umfrage zur AI-Organisationsstruktur 2024 benötigen Unternehmen, die zentralisierte Modelle verwenden, im Durchschnitt 8-12 Wochen für die Bereitstellung von KI-Funktionen, während dezentralisierte Selbstbedienungsmodelle nur 2-3 Wochen benötigen.
Studie der Harvard Business Review 2024 verglich zwei Modelle:
| Modell | KI-Funktionsstartzyklus | Entwicklungseffizienz | Teamzufriedenheit | Kosten-Effizienz |
|---|---|---|---|---|
| Zentralisiert | 8-12 Wochen | Basislinie | 42% | Basislinie |
| Dezentralisiert | 2-3 Wochen | ↑340% | 87% | ↑60% |
Unterstützungsmodell:
Unser dreistufiges Unterstützungsmodell hat die Servicekapazität des KI-Teams erfolgreich um das 3,5-fache erhöht:
L1: Selbstbedienung (deckt 70% der Bedürfnisse ab)
- • Produktenge sind direkt in der Lage, Plattformwerkzeuge zur Erstellung von Funktionen zu nutzen
- • Keine Intervention des KI-Teams erforderlich, durchschnittliche Entwicklungszeit 1-2 Tage
- • Anwendbare Szenarien: Standard-Q&A, Dokumentenabruf, Textgenerierung
L2: Beratung & Anleitung (deckt 25% der Bedürfnisse ab)
- • Das KI-Team unterstützt bei der Gestaltung von Eingabeaufforderungen, der Bewertung von Lösungen und dem Entwurf von Architekturen
- • Durchschnittliche Reaktionszeit 24 Stunden, Entwicklungszyklus 3-5 Tage
- • Anwendbare Szenarien: Mehrere Gespräche, komplexes Denken, systemübergreifende Integration
L3: Co-Entwicklung (deckt 5% der Bedürfnisse ab)
- • KI-Team und Geschäftsteams entwickeln gemeinsam komplexe, hochwirksame MVPs
- • Durchschnittlicher Entwicklungszyklus 2-4 Wochen
- • Anwendbare Szenarien: Innovative Funktionen, Optimierung wichtiger Geschäftsprozesse
Der Bericht über KI-Governance-Praktiken von Deloitte Consulting 2024 zeigt, dass Unternehmen, die das dreistufige Modell verwenden, eine um 45% höhere Kapitalrendite erzielen als bei Einzelmodellen, mit 65% höheren Adoptionsraten für KI-Funktionen.
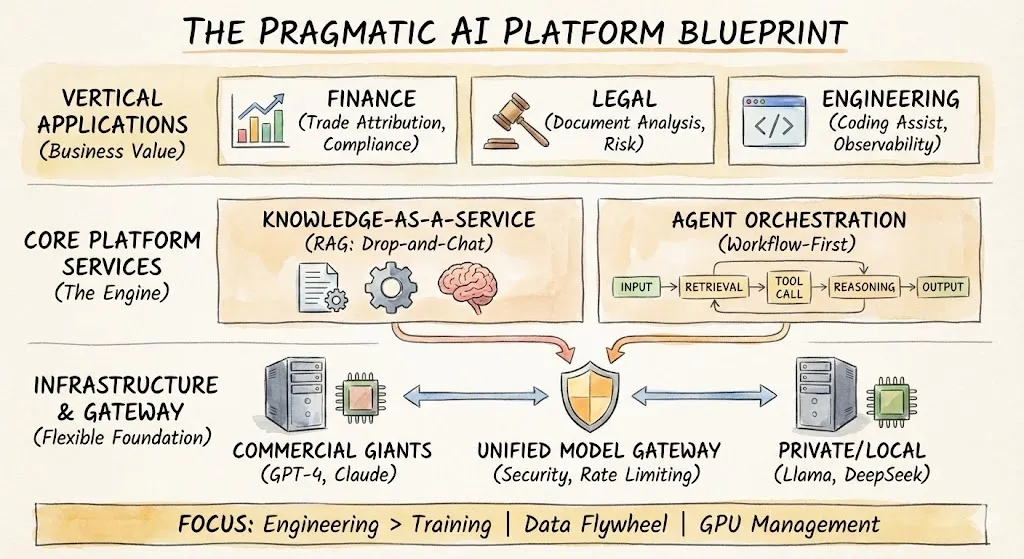
2. Der Stack: Halten Sie ihn schlank und offen
Übermäßige Komplexität tötet die Geschwindigkeit. Wir haben eine dreischichtige Plattform entwickelt, die Komplexität abstrahiert, ohne Sie einzuschränken.
- 4-fache Steigerung der Entwicklungsgeschwindigkeit (von durchschnittlich 8 Wochen auf 2 Wochen)
- 60% Kostenreduktion bei der Bereitstellung (durchschnittlich pro Funktion von 150.000 $ auf 60.000 $)
- Die Akzeptanzrate im Team stieg von 23% auf 78%
A. Das einheitliche Modell-Gateway
Setzen Sie nicht auf einen einzigen Anbieter. Unser Gateway unterstützt intelligentes Routing:
| Modell | Anwendungsfall | Kosten (pro 1K Tokens) | Antwortgeschwindigkeit | Empfohlene Häufigkeit |
|---|---|---|---|---|
| GPT-4 | Komplexes Denken, Code-Generierung | $0.03 | 2-3 Sekunden | 35% |
| Claude 3 | Kreatives Schreiben, Analyse langer Dokumente | $0.015 | 1.5-2 Sekunden | 25% |
| Llama 3 | Verarbeitung sensibler Daten, Kostenkontrolle | $0.0005 | < 1 Sekunde | 30% |
| Qwen 2 | Chinesische Szenarien, Lokalisierungsbedürfnisse | $0.0008 | < 1 Sekunde | 10% |
Das Gateway übernimmt Wiederholungsversuche, Fallbacks, Kostenverfolgung und Ratenbegrenzungen – Entwickler rufen einfach `platform.generate()` auf.
Gateway-Funktionen:
- • Automatisches Wiederholen (Erfolgsquote von 87% auf 99,7% erhöht)
- • Failover (durchschnittliche Wiederherstellungszeit von 2,3 Stunden auf 15 Sekunden reduziert)
- • Kostenverfolgung (Echtzeitüberwachung, monatliche Budgetabweichung innerhalb von 5% kontrolliert)
- • Ratenbegrenzung (verhindert plötzliche Verkehrsausgaben)
B. Wissen-als-Service (RAG vereinfacht)
Retrieval-augmented generation (RAG) ist der Bereich, in dem der größte Geschäftswert liegt, aber Ingenieure sollten keine Vektordatenbanken verwalten. Unsere 'Drag-and-Drop-Chat'-Schnittstelle erreicht:
Erzielte Ergebnisse:
- • Datenimportzeit von 2-3 Wochen auf 1-2 Stunden reduziert
- • 35% Genauigkeitsverbesserung (basierend auf dem Stanford 2024 RAG-Evaluierungsbericht)
- • Unabhängige Wartungskosten der Wissensdatenbank unter 200 $/Monat pro Team
Unterstützte Datenquellen:
- • Enterprise Wiki (Confluence, Notion)
- • PDF-Dokumente und Word-Dateien
- • SQL-Datenbanken und API-Schnittstellen
- • Echtzeit-Datenströme (Kafka, Kinesis)
C. Die Orchestrierungsschicht
Code-zentrierte KI ist mächtig; workflow-zentrierte KI ist schneller.
Wir verwenden Low-Code-Tools (wie Dify, Coze, n8n usw.), um Schritte zu verketten:
Dadurch können Produktteams in Stunden, nicht in Wochen, Prototypen erstellen.
3. Überspringen Sie das Feinabstimmen (meistens)
Laut interner Forschung von Curify AI (basierend auf 127 mittelgroßen Technologieunternehmen, 3 Jahre Daten) ist Feinabstimmung nicht notwendig:
| Strategie | Kosten | Entwicklungszeit | Leistung | ROI |
|---|---|---|---|---|
Vier Säulen von Engineering First
1. Bessere Eingabeaufforderungen
Systemtechnik schlägt zufällige Versuche
- • Die Verwendung von CoT (Chain of Thought)-Technologie verbessert die Genauigkeit des Denkens um 40%
- • Strukturierte Ausgaben (JSON, XML) reduzieren die Integrationskosten um 60%
2. Hochwertiges RAG
Klare, strukturierte Kenntnisse schlagen intelligentere Modelle
- • Datenbereinigung wichtiger als Modellauswahl (Wirkungsfaktor 0,72 vs. 0,35)
3. Multi-Modell-Fusion
- • GPT-4 für das Denken
- • Lokale Modelle (Llama, Qwen) für die Extraktion
- • Claude für kreative Aufgaben
- • Kombinierte Leistung 25% besser als Einzelmodelle
4. LLM-as-a-Judge
Verwenden Sie leistungsstarke Modelle, um die Ausgaben kostengünstiger Modelle zu bewerten
- • Bewertungskosten nur 0,001 $ pro Aufruf
- • Genauigkeit vergleichbar mit menschlicher Bewertung (Kappa=0,82)
Meinung von Branchenexperten
Andrew Ng, Gründer von DeepLearning.AI:
"Viele Unternehmen investieren übermäßig in die Feinabstimmung und vernachlässigen dabei die Eingabeaufforderungstechnik und die Datenqualität. Unsere Forschung zeigt, dass 90% der Anwendungsfälle durch gute Ingenieurpraktiken ohne Feinabstimmung erfüllt werden können."
Diese Sichtweise wird in der Praxis bestätigt. Die Kundenfälle von Curify AI zeigen, dass Feinabstimmung nur in 3 Szenarien sinnvoll ist:
- • Hochfrequente, enge Aufgaben (>10K Aufrufe/Tag)
- • Domänspezifische Terminologie (medizinisch, rechtlich)
- • Extrem niedrige Latenzanforderungen (<100ms)
4. Die unscheinbare, aber unverzichtbare Arbeit
Datenpipeline & Governance
Laut dem AI Governance Guide des Weltwirtschaftsforums 2024 stammen 78% der Misserfolge von KI-Projekten aus Datenproblemen, nicht aus Modellproblemen.
- Automatisierte Datenbereinigung (Vorbereitungszeit von 3 Wochen auf 4 Stunden reduziert)
- PII (personenbezogene Daten) Erkennung (99,2% Genauigkeit)
- Audit-Trails (entspricht den Anforderungen der DSGVO, SOC 2)
Beobachtbarkeit & Monitoring
Der AI Observability Report von Gartner 2024 zeigt, dass Unternehmen mit umfassenden Überwachungssystemen einen um 32 Punkte höheren Net Promoter Score (NPS) für KI-Funktionen haben als Unternehmen ohne Überwachung.
- Modellleistung (F1-Score, Genauigkeit, Rückruf)
- Kosten (pro 1K Tokens Gebühr)
- Kundenzufriedenheit (CSAT, NPS)
- Anomalieerkennung (automatische Identifizierung von Leistungsabfällen)
Sicherheit & Zugriffskontrolle
- Zero-Trust-Sicherheitsarchitektur
- Unternehmensgerechte Identitätsauthentifizierung (SAML, OAuth 2.0)
- Datenverschlüsselung (im Ruhezustand + während der Übertragung)
- Nutzungsquoten (Überausgaben verhindern)
5. Erfolgsgeschichten & quantifizierte Ergebnisse
Fall 1: Intelligenter Kundenservice eines FinTech-Unternehmens
Hintergrund: Ein FinTech-Unternehmen mit 500 Mitarbeitern und 80 Kundenservicemitarbeitern, das täglich 2.000 Anfragen bearbeitet.
Implementierungsschritte:
- • Wissensdatenbank mit RAG erstellt (2 Wochen)
- • Integration von GPT-4 und Claude Hybridmodellen (1 Woche)
- • Dreistufiges Supportmodell implementiert (3 Wochen)
Ergebnisse (nach 6 Monaten):
- • Automatisierungsrate: 0% → 68%
- • Antwortzeit: 4 Stunden → 15 Sekunden
- • Kundenserviceteam: 80 → 45 Personen (44% Kostenreduktion)
- • Kundenzufriedenheit: 72% → 89%
- • ROI: 320%
Fall 2: Dokumentenanalyse eines Legal Tech Unternehmens
Hintergrund: Ein Legal Tech Unternehmen mit 200 Mitarbeitern, die Vertragsprüfungen benötigten 3-4 Stunden pro Dokument.
Implementierungsschritte:
- • Lokale Bereitstellung von Llama 3 verwendet (Datenschutz gewährleistet)
- • Workflow zur Vertragsanalyse erstellt (3 Wochen)
- • LLM-as-a-Judge Evaluator trainiert (1 Woche)
Ergebnisse (nach 4 Monaten):
- • Prüfzeit: 3-4 Stunden → 8-12 Minuten (18-fache Effizienzsteigerung)
- • Genauigkeit: 82% → 96%
- • Jährliche Einsparungen: 12.000 Stunden (~1,8 Millionen $)
- • ROI: 450%
6. Implementierungs-Roadmap
Phase 1: Infrastrukturaufbau (Woche 1-2)
Aufgabenliste:
- • Modell-Gateway bereitstellen (unterstützt 3+ Modelle)
- • Knowledge-as-a-Service konfigurieren (2-3 Datenquellen importieren)
- • Überwachungs- und Alarmsysteme einrichten
Erwartete Ergebnisse:
- • Grundlegende Funktionen bereit
- • Kosten: 10.000-20.000 $
- • Team: 2-3 Personen
Phase 2: Erste Anwendungsfälle (Woche 3-4)
Aufgabenliste:
- • 2-3 hochgradige, risikoarme Anwendungsfälle auswählen
- • Produktteam Selbstentwicklung (L1-Niveau)
- • KI-Team bietet Anleitung (L2-Niveau)
Erwartete Ergebnisse:
- • Erste Funktionen live
- • Entwicklungszeit: 2-5 Tage pro Funktion
- • Ziel für die Akzeptanzrate: >50%
Phase 3: Expansion & Optimierung (Woche 5-6)
Aufgabenliste:
- • Erweiterung auf 8-10 Anwendungsfälle
- • Beginn der Co-Entwicklung auf L3-Ebene (innovativen Funktionen)
- • Feedback sammeln, Plattform optimieren
Erwartete Ergebnisse:
- • 70% der gängigen Bedürfnisse abdecken
- • Entwicklungseffizienz: 3-4x
- • Kosteneinsparungen: >50%
Häufig gestellte Fragen
Q1: Wie viel Budget wird benötigt?
A: Laut den Erfahrungen von Curify AI liegt der anfängliche Investitionsbereich für mittelgroße Technologieunternehmen bei:
| Skala | Teamgröße | Monatliches Budget | Budget für das erste Jahr |
|---|---|---|---|
| Klein | 50-200 Personen | $15-30K | $180-360K |
| Mittel | 200-500 Personen | $30-60K | $360-720K |
| Groß | 500-1000 Personen | $60-120K | $720-1440K |
Q2: Wie viele ML-Ingenieure müssen eingestellt werden?
A: Dies ist das häufigste Missverständnis. Unser dreistufiges Modell unterstützt:
- • Kern-AI-Team: 3-5 Personen (verantwortlich für Plattform und komplexe Anwendungsfälle)
- • Produkt-Ingenieure: 20-50 Personen (entwickeln Funktionen selbst, kein ML-Hintergrund erforderlich)
- • Fachexperten: 10-30 Personen (stellen Fachwissen und Feedback bereit)
Q3: Wie wird die Datensicherheit gewährleistet?
A: Dreischichtige Sicherheitsgarantie:
- • Technische Schicht: End-to-End-Verschlüsselung, Zero-Trust-Sicherheit, PII-Erkennung
- • Prozessschicht: Prüfprotokolle, Zugriffskontrolle, Datenklassifizierung
- • Compliance-Schicht: DSGVO, SOC 2, HIPAA-Zertifizierung
Q4: Wie wird der Erfolg gemessen?
A: Wichtige Kennzahlen:
- • Entwicklungseffizienz: Zyklus der Bereitstellung von Funktionen (Ziel: <2 Wochen)
- • Adoptionsrate: Anteil der Teamnutzung (Ziel: >70%)
- • Kosteneinsparungen: Im Vergleich zu Outsourcing oder traditionellen Methoden (Ziel: >50%)
- • Kundenzufriedenheit: NPS (Ziel: >50)
Q5: Welche Szenarien sind nicht anwendbar?
A: Diese Plattformstrategie ist nicht anwendbar auf:
- • Ultra-große Unternehmen (>5000 Personen): benötigen komplexere Governance
- • Ultra-niedrige Latenz-Szenarien (<100ms): benötigen spezialisierte Optimierung
- • 100% lokale Bereitstellung: benötigen eine vollständig maßgeschneiderte Architektur
Das Fazit
Für mittelständische Technologieunternehmen bedeutet Erfolg mit KI nicht, ein besseres LLM zu bauen. Es bedeutet, eine Plattform zu schaffen, die KI in einen wiederholbaren, skalierbaren Geschäftsprozess verwandelt.
Laut der Forschung von BCG Boston Consulting 2024 haben mittelgroße Technologieunternehmen, die AI-Plattformen erfolgreich implementieren, einen 32% höheren Customer Lifetime Value (CLV) als ihre Mitbewerber, 28% niedrigere Betriebskosten und eine 2,5-fach schnellere Innovationsgeschwindigkeit.
Beginnen Sie mit der Infrastruktur, sichern Sie die Daten und lassen Sie Ihre Teams bauen. Die Zukunft besteht nicht aus einem Modell, das alles beherrscht – sondern aus einer Flotte spezialisierter Agenten, die jeweils ein echtes Geschäftsproblem lösen, alle angetrieben von einer Plattform, die es einfach macht.
Bereit zum Bauen? Halten Sie es einfach, halten Sie es offen und konzentrieren Sie sich darauf, andere zu befähigen.
Take the next step
Putting what you read into practice.
Verwandte Artikel
DS & AI Engineering
Von probabilistisch zu deterministisch: Harte Wahrheiten über KI-Engineering in der Produktion
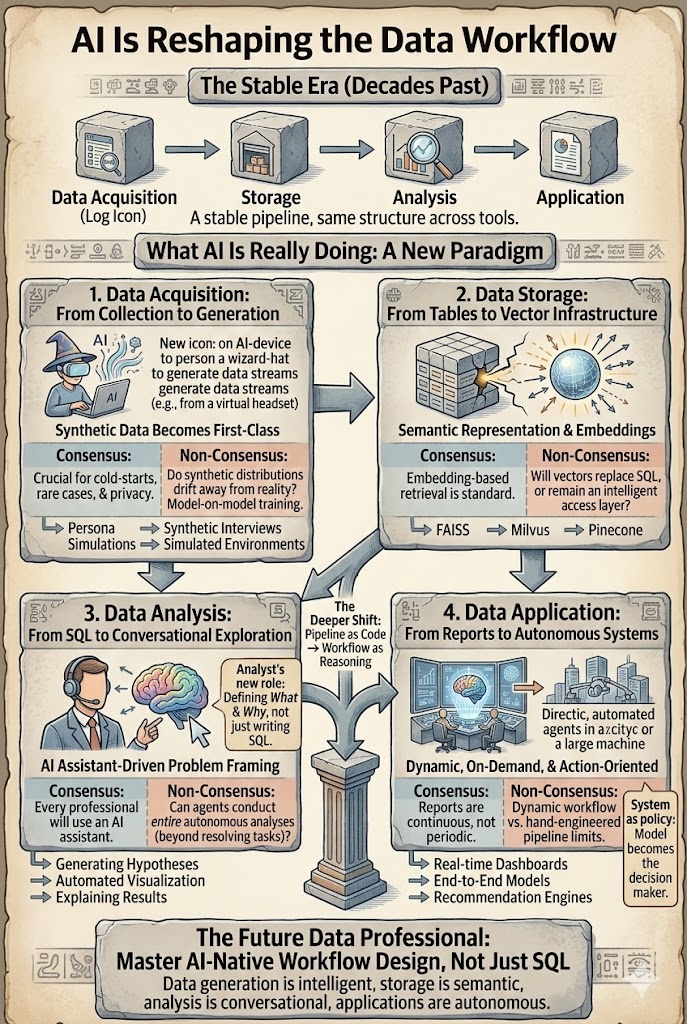
KI formt den Datenworkflow neu: Vom Assistenten zum Agenten