KI formt den Datenworkflow neu: Vom Assistenten zum Agenten
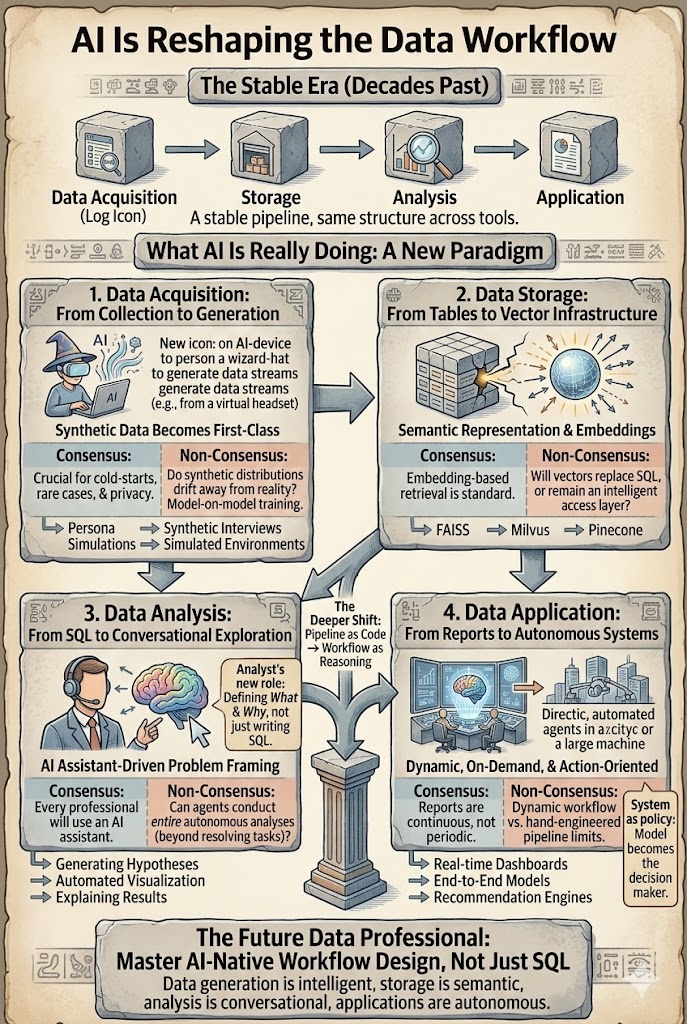
Der Datenworkflow war ein Jahrzehnt lang bemerkenswert stabil. Egal, ob Sie Datenwissenschaftler, Analyst oder Empfehlungstechniker sind, die Pipeline sah ungefähr gleich aus: Akquisition → Speicherung → Analyse → Anwendung. KI beschleunigt diesen Workflow nicht nur, sondern beginnt, jede Schicht davon neu zu gestalten. Die eigentliche Frage ist nicht mehr, ob KI die Datenarbeit verändern wird. Es ist, welche Teile sich eindeutig ändern und welche Annahmen sich als falsch herausstellen werden.
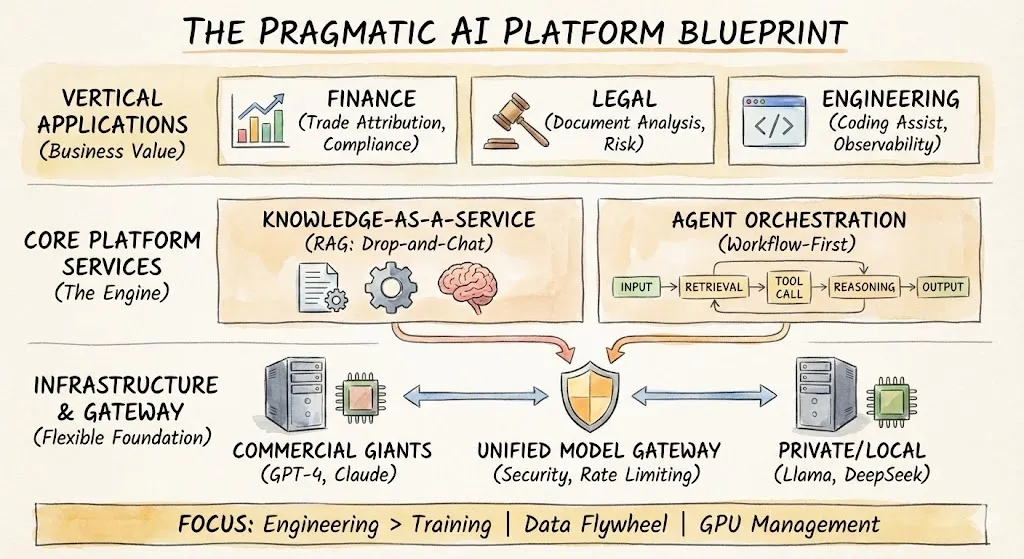
Die vier Schichten des Datenworkflows
Verschiedene Werkzeuge, verschiedene Branchen – aber grundsätzlich die gleiche vierstufige Struktur: Daten generieren oder sammeln, speichern, analysieren, Erkenntnisse anwenden. Diese Pipeline hat zehn Jahre lang Suche, Werbung und Empfehlungssysteme mit relativ wenig Veränderung in der Form betrieben. Was sich geändert hat, ist die Tiefe, in der jede Schicht jetzt von großen Modellen und Agenten neu gestaltet wird. Die folgenden Abschnitte behandeln jede Schicht und trennen den Konsens (was sich eindeutig ändert) vom Nicht-Konsens (was noch zur Debatte steht).
Wie sich jede Schicht verändert
1. Datenakquisition – Synthetische Daten werden zu einer erstklassigen Quelle
Traditionell kamen nützliche Daten aus der realen Welt: Protokolle, Transaktionen, Sensoren, Umfragen. Diese Annahme beginnt zu brechen. Immer mehr Daten werden jetzt generiert, anstatt gesammelt – durch Personasimulationen, Verhaltensmodellierung, synthetische Interviews, A/B-Testdatengenerierung und simulierte Umgebungen, die für das Training und die Bewertung von Reinforcement Learning verwendet werden.
Konsens: Synthetische Daten werden zunehmend reale Daten ergänzen, insbesondere bei Kaltstartproblemen, seltenen Szenarien und datenschutzbeschränkten Umgebungen.
Nicht-Konsens: Was passiert, wenn Modelle zunehmend auf Daten trainiert werden, die von anderen Modellen erzeugt werden? Werden synthetische Verteilungen langsam von der Realität abweichen und Rückkopplungsschleifen bilden?
Die Datenakquisition verschiebt sich von *Sammlung* zu *Generierung + Kalibrierung*.
2. Datenspeicherung – Von Tabellen zu Vektor-Infrastrukturen
Traditionelle Datensysteme wurden um strukturierte Speicherung herum aufgebaut: relationale Datenbanken, Data Warehouses und Spaltenläden. KI führt eine neue Schicht ein – Vektor-Repräsentationen. Texte, Bilder, Videos, Benutzerverhalten und Wissensfragmente werden zunehmend als Einbettungen gespeichert, die semantische Suche, retrieval-unterstützte Generierung und multimodales Denken ermöglichen. Vektordatenbanken wie FAISS, Milvus und Pinecone werden zur Kerninfrastruktur.
Konsens: Einbettungsbasierte Abfragen sind jetzt ein Standarddesignmuster. RAG ist die Standardarchitektur, um LLMs in proprietären Daten zu verankern.
Nicht-Konsens: Werden Vektoren schließlich traditionelle Speicherschichten ersetzen? Oder werden sie eine Indizierungsschicht über Rohdaten bleiben? Können wir ursprüngliche Daten aus Einbettungen so gut rekonstruieren, dass Vektoren zum primären Speicher werden?
Im Moment fungieren Einbettungen weniger als Speicher und mehr als eine intelligente Zugriffsschicht. Aber diese Schicht hat bereits die Art und Weise, wie auf Daten zugegriffen wird, neu gestaltet.
3. Datenanalyse – Von SQL zu konversationeller Erkundung
Die Analyseebene verändert sich am schnellsten. Der traditionelle Workflow sah so aus:
Problemdefinition → SQL → Merkmalsengineering → Modellierung → Interpretation
Heute können KI-Systeme fast jeden Schritt unterstützen: LLMs generieren automatisch SQL, schlagen Hypothesen vor, erstellen Visualisierungen, konstruieren Basismodelle und erklären Ergebnisse. Die Rolle des Analysten verschiebt sich von *Abfrageautor* zu *Problemgestalter und Validator*.
Konsens: Jeder Datenprofi wird bald mit einem KI-Assistenten arbeiten. Co-Piloten und chatbasierte Analysen werden zum Standard.
Nicht-Konsens: Werden Agenten schließlich gesamte Analysen von Anfang bis Ende durchführen? Im Kundenservice können Agenten bereits 80 % der Tickets bearbeiten. Datenanalyse ist schwieriger – die Fragen selbst sind oft mehrdeutig und die Ziele ändern sich während der Untersuchung. Automatisierung wird die Ausführung beschleunigen, aber Menschen werden wahrscheinlich weiterhin für die Problemdefinition verantwortlich sein.
4. Datenanwendung – Von Berichten zu autonomen Systemen
Die letzte Phase – die Anwendung von Erkenntnissen – entwickelt sich in zwei Richtungen weiter.
Berichte. KI transformiert bereits das Reporting: automatische Zusammenfassungen, Diagramme, Dashboards und Präsentationen über Text, Bild und Video. Der tiefere Wandel besteht darin, dass Berichte nicht mehr periodisch sein müssen. Sie können kontinuierlich und auf Abruf generiert werden. Der eigentliche Produktivitätsgewinn besteht nicht darin, "schneller zu schreiben", sondern "Berichte, die existieren, wenn die Frage gestellt wird."
Autonome Systeme. Empfehlungen, Suche, Werbung und autonomes Fahren bewegen sich weg von handgefertigten modularen Pipelines hin zu End-to-End-Modellen, bei denen das Modell selbst zur Entscheidungsrichtlinie wird. Der Wandel vollzieht sich vom *Merkmalsverbraucher* zum *Strategiegenerator*.
Assistent vs Agent – Konsens und Nicht-Konsens
Ein aufkommender Konsens: Assistenten und Agenten werden langfristig koexistieren. Aber das Gleichgewicht variiert stark zwischen den Bereichen.
| Bereich | Anteil Assistent | Anteil Agent |
|---|---|---|
| Kundenservice | 20 % | 80 % |
| Datenanalyse | 70 % | 30 % (unsicher) |
| Optimierung der Empfehlungspolitik | 50 % | 50 % |
| Autonomes Fahren | 10 % | 90 % |
Die zentrale Unsicherheit liegt in der Datenanalyse. In Bereichen, in denen die Problemdefinition selbst der schwierigste Teil ist, haben Agenten Schwierigkeiten, den Kreis zu schließen. Das wahrscheinlichste Ergebnis: Die Analyse bleibt assistentenschwer, aber die Ausführung wird stark automatisiert. Menschen definieren; Agenten erkunden.
Der tiefere Wandel besteht nicht in schnellerem SQL oder besseren Dashboards. Es geht darum, wer den Workflow kontrolliert. Wir bewegen uns von *Pipeline als Code* zu *Workflow als Denken* – von der Ausführung vordefinierter Schritte zu Systemen, die Aktionen planen, Hypothesen erkunden und iterieren.
Tools & Resources
Learn about the best tools available...
Wo Curify in diesen Wandel passt
Curify basiert auf dem Muster *Workflow als Denken*. Drei konkrete Beispiele auf der Plattform heute:
- Inhaltserstellung als Workflow, nicht als Einmalaktion. Die /nano-template Bibliothek umfasst 172 parametrisierten Vorlagen, die Prompt → Bildgenerierung → Varianten-Tagging → CDN-Synchronisierung verknüpfen – ein Generierungsworkflow, kein einmaliger Prompt.
- Einbettungsunterstützter Zugriff auf der Galerieebene. Der /nano-banana-pro-prompts Korpus von über 4.000 Prompts ist nach Tag, Thema und semantischer Ähnlichkeit durchsuchbar – die Vektorschicht ist der Zugriffsweg, rohes JSON ist die Quelle der Wahrheit.
- Audio- und Video-Transkription als Eingabe. /tools/video-transcript-generator gibt sprechergetaggte Transkripte aus, die in /tools/video-dubbing und /tools/translate-subtitles fließen – ein Workflow, bei dem ein Eingang drei lokalisierte Ausgaben antreibt.
Die eigentliche Frage für Datenprofis
Der traditionelle Datenworkflow verschwindet nicht. Aber er entwickelt sich weiter: Datenproduktion wird intelligenter, Speicherung wird semantischer, Analyse wird konversationeller, Anwendungen werden autonomer.
Eine radikalere Nicht-Konsens-Ansicht: Zukünftige Datensysteme könnten sich in zwei Teile spalten – menschlich interpretierbare Analysesysteme (zum Verständnis der Welt) und Black-Box-Optimierungssysteme (zur Optimierung von Ergebnissen). Wenn sich die beiden trennen, verschwinden Datenprofis nicht; sie werden zu *Strategie-Interpreten* anstelle von Datenbetreibern.
Die eigentliche Frage für jeden Datenprofi heute ist nicht mehr "können Sie SQL schreiben." Es ist: können Sie KI-native Workflows entwerfen?
Take the next step
Putting what you read into practice.
Verwandte Artikel
DS & AI Engineering
Von probabilistisch zu deterministisch: Harte Wahrheiten über KI-Engineering in der Produktion
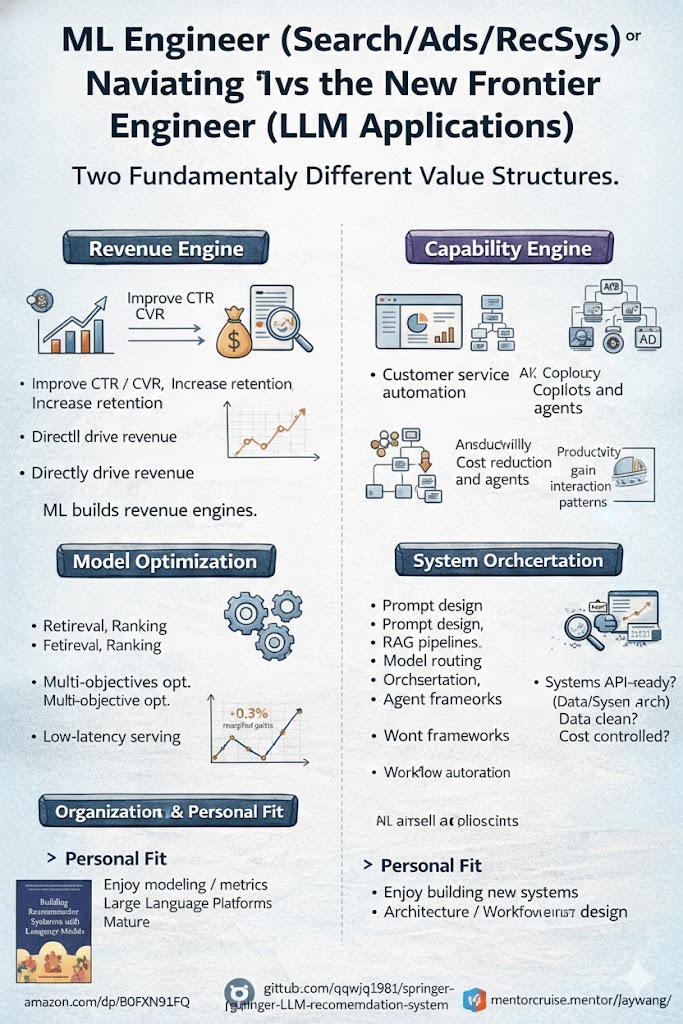
ML-Ingenieur oder KI-Ingenieur? Zwei Karrierewege, zwei Wertstrukturen