Building a Self-Improving Multimodal Search Engine with Real User Queries at Curify
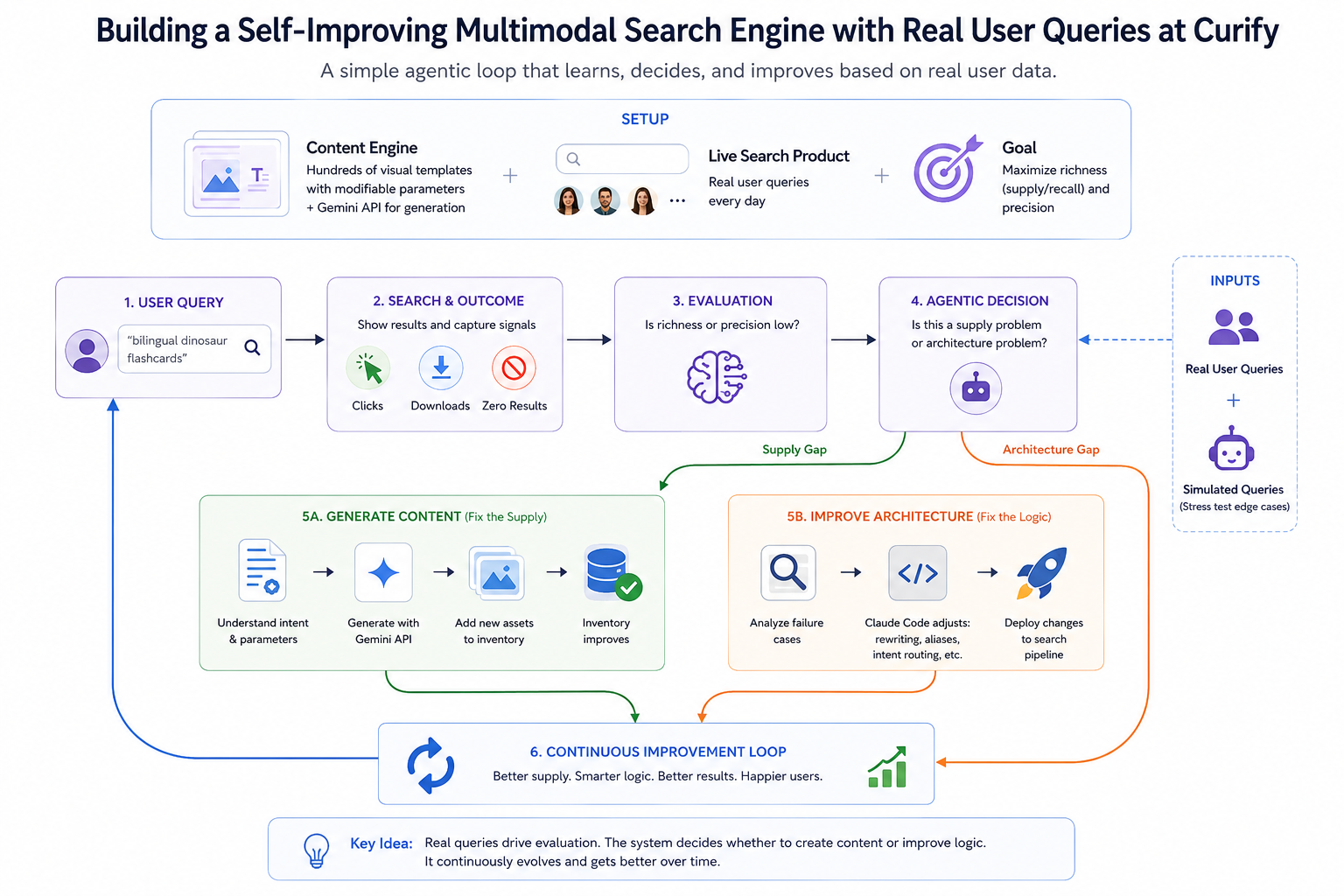
Traditional search engines are static indexes — they wait for the world to populate them. In the era of agentic workflows and "vibe coding," building a search system shouldn't just be about optimizing BM25 or vector embeddings; it should be about building an autonomous loop that learns, decides, and builds its own supply. At Curify, we recently transformed our search bar from a passive retrieval tool into a self-improving multimodal engine. This post is the under-the-hood look at how we engineered an agentic loop driven by real user data.
The Setup: A Dynamic Supply Chain
To understand the engine, start with the inventory. Curify is not indexing the open web — the setup is highly controlled and deterministic:
The content engine: Hundreds of structured visual templates with modifiable parameters, hooked directly into the Gemini API for high-fidelity image generation.
The signal: A live search product capturing daily, real-world user queries.
The optimization goal is straightforward: maximize search result *richness* (supply / recall) and *precision*. But instead of manually tuning weights, we turn the live user queries into a dynamic, continuous evaluation set. Each underperforming query becomes a training signal — not in the gradient-descent sense, but in the agentic-decision sense. The pipeline reasons about *why* a query failed and routes to the right fix.
The Evaluate → Reason → Act Loop
Step 1: Capture Real Queries (and Simulate the Edge Cases)
Every search on Curify captures the query plus the immediate outcome: clicks, downloads, or the dreaded zero-result page. That gives us a stream of real signal.
We also inject *simulated* user responses to stress-test edge cases before real users hit them — a small synthetic-traffic generator that probes the corners of the catalog the way an LLM-driven agent would. Real queries surface what users actually need; simulated queries surface what they *will* need based on patterns we expect. Both feed the same evaluation pipeline.
Step 2: Evaluate Each Underperforming Query
Any query that yields low richness or poor precision triggers an evaluation node. The evaluator combines real engagement signals (clicks, dwell time, downloads) with Gemini-judged relevance scoring for queries that returned results but where engagement is ambiguous.
The evaluator does not just log the error. It asks the agentic question: *is this a supply problem, or an architecture problem?* That fork is the heart of the loop and determines which of the two action paths fires next.
Step 3: Decision Fork — Generate Content (Fix the Supply)
If the evaluation determines the user's intent is valid (e.g., "bilingual dinosaur flashcards") but the database is genuinely empty, the system acts as an autonomous creator.
Action: It routes the query parameters to the template engine, triggers the Gemini API, and batch-generates the missing visual assets — the same template-driven pipeline that powers regular content drops, now invoked on demand by a failed search.
By the time the next user (or simulated agent) runs the same search, the inventory has healed itself. The search engine literally built what was missing.
Step 4: Decision Fork — Improve Architecture (Fix the Logic)
If the content exists ("T-Rex educational posters") but the user's query ("jurassic learning materials") failed to surface it, the engine flags an architectural gap.
Action: This is where vibe coding earns its keep. Instead of a developer manually writing regex rules, we feed the failed evaluation cases to Claude Code and prompt it to:
- update query rewriting rules
- generate new alias expansions
- refine the LLM intent-routing prompt
Architectural tweaks to the search pipeline ship in minutes, grounded entirely in real user friction points. The engineer stays in the loop reviewing diffs, but the agent does the drafting against real cases instead of speculating about hypothetical queries.
What This Replaces
Three patterns the loop displaces:
Manual content backfill: traditional search teams maintain a backlog of "queries with low recall" and dispatch content commissions to fix the gaps. Lag is weeks; many never get filled. The agentic loop closes the gap in hours.
Hand-written rewrite rules: search engineers writing per-keyword aliases or maintaining stemming dictionaries. Necessary but slow, and the rules drift as new query patterns emerge. Vibe-coded rewrites scale linearly with case volume, not engineer hours.
Static evaluation sets: relevance benchmarks authored once and frozen. Real user queries shift every week — a static eval set is measuring last quarter's reality. Treating live queries as the evaluation set means the system optimizes for what users actually search for *this week*.
Tools & Resources
Learn about the best tools available...
How the Stack Wires Together
Four components, glued by the agent layer:
Search front-end captures queries + engagement signals and ships them to the evaluator in near-real-time.
Template engine is Curify's Nano Banana library — hundreds of parameterized visual templates that the supply-side fork calls to generate missing content. Same engine that drives manual content drops; the loop becomes another caller.
Gemini API handles both image generation (supply side) and relevance scoring (evaluation side). Single model family, two roles.
Claude Code handles the architecture-side updates — rewrite rules, alias expansions, intent-routing prompts. The agent gets context on the failed cases plus the existing pipeline state, returns a diff, engineer reviews, ship.
The integration cost was lower than expected because the template engine and the search front-end were already standalone systems. The agentic loop is a coordination layer above tools we already had — not a rewrite — which is why we could ship the first version in days rather than weeks.
Search as Orchestration
Search is no longer just about retrieval and ranking; it is an orchestration problem. By treating real user queries not just as metrics but as active triggers for an agentic decision-maker, we've built a system that actively fights its own entropy.
At Curify, the search engine doesn't just find content anymore. If the content is missing, it creates it. If the logic is flawed, it rewrites it. The supply side and the architecture side both improve from the same signal — the queries that didn't work yesterday.
That is the model for the next generation of search systems: not bigger indexes, but tighter loops.
Take the next step
Putting what you read into practice.
Browse related topics
More templates and prompts in these areas.
Related Articles
DS & AI Engineering
The AI Content Factory: Why Marketing Agencies Need to Stop Buying Tools and Start Building Pipelines

From Months to Minutes: A Multi-Modal AI Pipeline for Bilingual Educational Publishing