人工智能正在重塑数据工作流程:从助手到代理
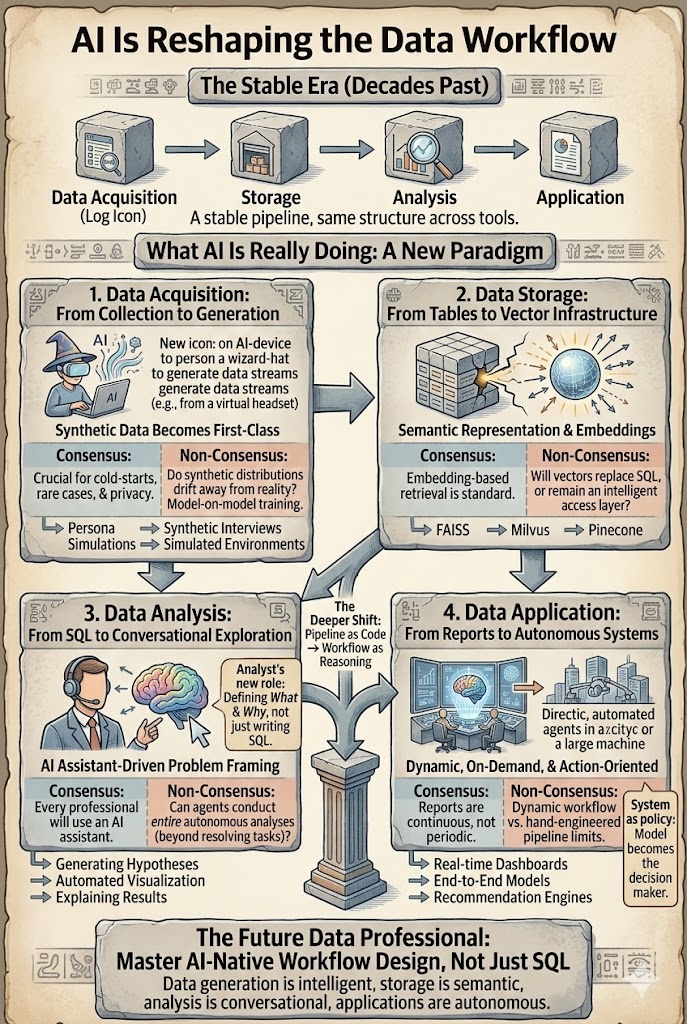
数据工作流程在过去十年中保持了显著的稳定性。无论您是数据科学家、分析师还是推荐工程师,流程大致相同:获取 → 存储 → 分析 → 应用。人工智能不仅加速了这一工作流程——它开始重塑每一层。真正的问题不再是人工智能是否会改变数据工作,而是哪些部分正在明显变化,哪些假设将被证明是错误的。
数据工作流程的四个层次
不同的工具,不同的行业——但基本上相同的四步结构:生成或收集数据,存储数据,分析数据,应用洞察。这个流程在过去十年中推动了搜索、广告和推荐系统,形态变化相对较小。变化的是每一层现在被大型模型和代理重塑的深度。下面的部分将逐层分析,并将共识(明显变化的部分)与非共识(仍在争论中的部分)分开。
每一层是如何变化的
1. 数据获取——合成数据成为一流来源
传统上,有用的数据来自现实世界:日志、交易、传感器、调查。这个假设正在开始破裂。越来越多的数据现在是生成的,而不是收集的——通过角色模拟、行为建模、合成访谈、A/B测试数据生成和用于强化学习训练与评估的模拟环境。
共识: 合成数据将越来越多地补充现实世界数据,特别是在冷启动问题、稀有场景和隐私受限的环境中。
非共识: 当模型越来越多地在其他模型生成的数据上进行训练时会发生什么?合成分布是否会逐渐偏离现实并形成反馈循环?
数据获取正在从*收集*转向*生成 + 校准*。
2. 数据存储——从表格到向量基础设施
传统数据系统围绕结构化存储构建:关系数据库、数据仓库和列存储。人工智能引入了一层新内容——向量表示。文本、图像、视频、用户行为轨迹和知识片段越来越多地作为嵌入存储,支持语义搜索、检索增强生成和多模态推理。像FAISS、Milvus和Pinecone这样的向量数据库正在成为核心基础设施。
共识: 基于嵌入的检索现在是一种标准设计模式。RAG是将LLM与专有数据结合的默认架构。
非共识: 向量最终会取代传统存储层吗?还是它们将作为原始数据之上的索引层存在?我们能否从嵌入中重建原始数据,以至于向量成为主要存储?
目前,嵌入的功能更像是智能访问层而非存储。但这一层已经重塑了数据的访问方式。
3. 数据分析——从SQL到对话式探索
分析层变化最快。传统的工作流程如下:
问题定义 → SQL → 特征工程 → 建模 → 解释
如今,人工智能系统几乎可以协助每一步:LLM自动生成SQL,提出假设,构建可视化,构建基线模型,并解释结果。分析师的角色从*查询编写者*转变为*问题框架和验证者*。
共识: 每位数据专业人士很快将与人工智能助手合作。副驾驶和基于聊天的分析正在成为基本要求。
非共识: 代理最终会进行端到端的完整分析吗?在客户支持中,代理已经可以处理80%的工单。数据分析更难——问题本身往往模糊不清,目标在调查过程中会发生变化。自动化将加速执行,但人类可能仍然负责框架问题。
4. 数据应用——从报告到自主系统
最后阶段——应用洞察——在两个方面不断演变。
报告。 人工智能已经改变了报告:自动摘要、图表、仪表板和跨文本、图像和视频的演示。更深层次的变化是报告不再需要定期生成。它们可以持续生成并按需生成。真正的生产力提升不是“写得更快”,而是“在提出问题时存在的报告”。
自主系统。 推荐、搜索、广告和自主驾驶正在从手工设计的模块化流程转向端到端模型,其中模型本身成为决策政策。转变是从*特征消费者*到*战略生成者*。
助手与代理——共识与非共识
一个新兴的共识是:助手和代理将长期共存。 但在不同领域之间的平衡差异很大。
| 领域 | 助手份额 | 代理份额 |
|---|---|---|
| 客户支持 | 20% | 80% |
| 数据分析 | 70% | 30%(不确定) |
| 推荐策略优化 | 50% | 50% |
| 自主驾驶 | 10% | 90% |
关键的不确定性在于数据分析。在问题定义本身是最困难的部分的领域,代理在闭环方面存在困难。最可能的结果是:分析仍然以助手为主,但执行高度自动化。人类框架;代理探索。
更深层次的变化不是更快的SQL或更好的仪表板,而是谁控制工作流程。我们正在从*代码管道*转向*推理工作流程*——从执行预定义步骤转向计划行动、探索假设和迭代的系统。
Tools & Resources
Learn about the best tools available...
Curify在这一转变中的位置
Curify围绕*推理工作流程*模式构建。平台上今天的三个具体示例:
- 内容生成作为工作流程,而非单次操作。 /nano-template库包含172个参数化模板,链接提示 → 图像生成 → 变体标记 → CDN同步——一个生成工作流程,而不是一次性提示。
- 在画廊层的嵌入支持访问。 /nano-banana-pro-prompts语料库包含4000多个提示,可以按标签、主题和语义相似性进行搜索——向量层是访问路径,原始JSON是真相来源。
- 音频 + 视频转录作为上游输入。 /tools/video-transcript-generator输出带有发言者标签的转录文本,这些文本流入/tools/video-dubbing和/tools/translate-subtitles——一个由一个输入驱动三个本地化输出的工作流程。
数据专业人士面临的真正问题
传统的数据工作流程并没有消失。但它正在演变:数据生成变得更加智能,存储变得更加语义化,分析变得更加对话式,应用变得更加自主。
一个更激进的非共识观点是:未来的数据系统可能会分为两类——人类可解释的分析系统(用于理解世界)和黑箱优化系统(用于优化结果)。当两者分开时,数据专业人士并不会消失;他们将成为*战略解释者*而非数据操作员。
今天,任何数据专业人士面临的真正问题不再是“你能写SQL吗”。而是:你能设计AI原生工作流程吗?
Take the next step
Putting what you read into practice.