Создание самообучающейся мультимодальной поисковой системы с реальными запросами пользователей в Curify
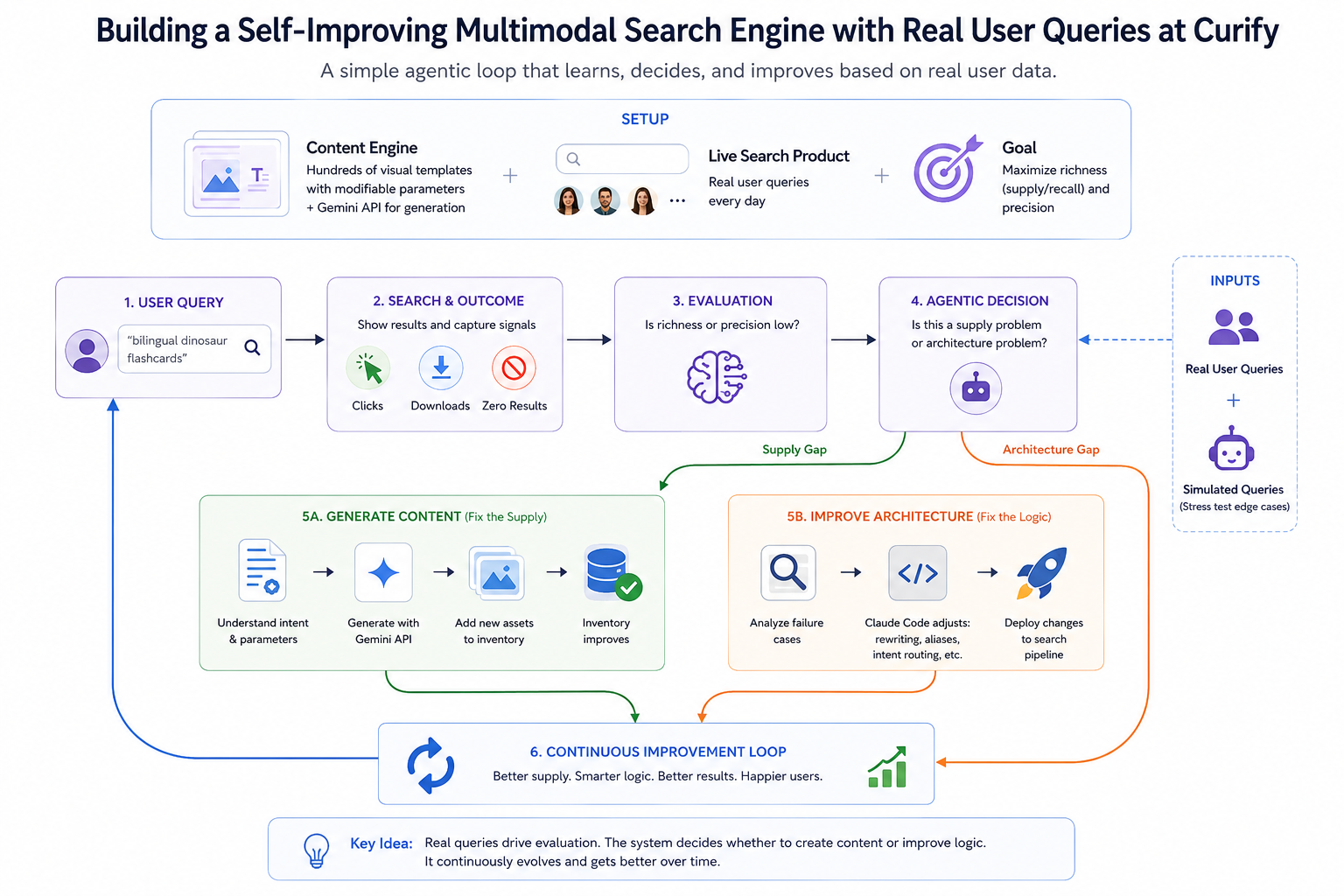
Традиционные поисковые системы — это статические индексы, которые ждут, пока мир их заполнит. В эпоху агентных рабочих процессов и "кодирования по настроению" создание поисковой системы не должно сводиться только к оптимизации BM25 или векторных вложений; это должно быть построением автономного цикла, который учится, принимает решения и создает собственное предложение. В Curify мы недавно преобразовали нашу строку поиска из пассивного инструмента извлечения в самообучающуюся мультимодальную систему. Этот пост — взгляд под капот на то, как мы разработали агентный цикл, управляемый реальными данными пользователей.
Настройка: Динамическая цепочка поставок
Чтобы понять движок, начните с инвентаря. Curify не индексирует открытый веб — настройка высоко контролируемая и детерминированная:
Контентный движок: Сотни структурированных визуальных шаблонов с изменяемыми параметрами, подключенные напрямую к API Gemini для высококачественной генерации изображений.
Сигнал: Живой поисковый продукт, захватывающий ежедневные реальные запросы пользователей.
Цель оптимизации проста: максимизировать *богатство* результатов поиска (предложение / отзыв) и *точность*. Но вместо того, чтобы вручную настраивать веса, мы превращаем живые запросы пользователей в динамический, непрерывный набор для оценки. Каждый неэффективный запрос становится сигналом для обучения — не в смысле градиентного спуска, а в смысле агентного решения. Конвейер размышляет о *почему* запрос не удался и направляет к правильному исправлению.
Цикл Оценка → Размышление → Действие
Шаг 1: Захват реальных запросов (и моделирование крайних случаев)
Каждый поиск в Curify захватывает запрос плюс немедленный результат: клики, загрузки или ужасная страница с нулевыми результатами. Это дает нам поток реального сигнала.
Мы также вводим *смоделированные* ответы пользователей, чтобы протестировать крайние случаи, прежде чем реальные пользователи с ними столкнутся — небольшой генератор синтетического трафика, который исследует углы каталога так, как это сделал бы агент на основе LLM. Реальные запросы выявляют, что пользователи действительно нуждаются; смоделированные запросы показывают, что им *понадобится* на основе ожидаемых паттернов. Оба питают один и тот же конвейер оценки.
Шаг 2: Оценка каждого неэффективного запроса
Любой запрос, который дает низкое богатство или плохую точность, запускает узел оценки. Оценщик сочетает реальные сигналы вовлеченности (клики, время нахождения, загрузки) с оценкой релевантности, определенной Gemini, для запросов, которые вернули результаты, но где вовлеченность неясна.
Оценщик не просто фиксирует ошибку. Он задает агентный вопрос: *это проблема предложения или проблема архитектуры?* Этот разветвление — сердце цикла и определяет, какой из двух путей действий будет выполнен следующим.
Шаг 3: Разветвление решения — Генерация контента (исправление предложения)
Если оценка определяет, что намерение пользователя действительно (например, "двуязычные карточки с динозаврами"), но база данных действительно пуста, система действует как автономный создатель.
Действие: Она направляет параметры запроса в движок шаблонов, запускает API Gemini и массово генерирует недостающие визуальные активы — тот же движок, который управляет регулярными выпусками контента, теперь вызываемый по запросу неудачного поиска.
К тому времени, когда следующий пользователь (или смоделированный агент) выполняет тот же поиск, инвентарь уже восстановился. Поисковая система буквально создала то, чего не хватало.
Шаг 4: Разветвление решения — Улучшение архитектуры (исправление логики)
Если контент существует ("образовательные постеры Ти-Рекса"), но запрос пользователя ("материалы для обучения юрского периода") не смог его выявить, движок отмечает архитектурный пробел.
Действие: Здесь кодирование по настроению оправдывает себя. Вместо того чтобы разработчик вручную писал правила regex, мы передаем неудачные случаи оценки Claude Code и просим его:
- обновить правила переписывания запросов
- сгенерировать новые расширения псевдонимов
- уточнить подсказку маршрутизации намерений LLM
Архитектурные изменения в конвейере поиска отправляются за считанные минуты, полностью основанные на реальных точках трения пользователей. Инженер остается в цикле, просматривая различия, но агент выполняет проектирование на основе реальных случаев, а не спекулирует о гипотетических запросах.
Что это заменяет
Три паттерна, которые цикл вытесняет:
Ручное заполнение контента: традиционные поисковые команды поддерживают список "запросов с низким отзывом" и отправляют заказы на контент для устранения пробелов. Задержка составляет недели; многие никогда не заполняются. Агентный цикл закрывает пробел за часы.
Ручные правила переписывания: инженеры по поиску пишут псевдонимы для каждого ключевого слова или поддерживают словари стемминга. Необходимо, но медленно, и правила изменяются по мере появления новых паттернов запросов. Переписывания, основанные на настроении, масштабируются линейно с объемом дел, а не с часами инженеров.
Статические наборы оценки: эталонные показатели релевантности, написанные один раз и замороженные. Реальные запросы пользователей меняются каждую неделю — статический набор оценки измеряет реальность прошлого квартала. Обработка живых запросов как набора для оценки означает, что система оптимизирует то, что пользователи действительно ищут *на этой неделе*.
Tools & Resources
Learn about the best tools available...
Как стек соединяется
Четыре компонента, соединенные агентным слоем:
Поисковый фронт захватывает запросы + сигналы вовлеченности и отправляет их оценщику в почти реальном времени.
Движок шаблонов — это библиотека Nano Banana от Curify — сотни параметризованных визуальных шаблонов, которые вызывает ветвь предложения для генерации недостающего контента. Тот же движок, который управляет ручными выпусками контента; цикл становится еще одним вызовом.
API Gemini обрабатывает как генерацию изображений (сторона предложения), так и оценку релевантности (сторона оценки). Одна семейство моделей, две роли.
Claude Code обрабатывает обновления со стороны архитектуры — правила переписывания, расширения псевдонимов, подсказки маршрутизации намерений. Агент получает контекст по неудачным случаям плюс текущее состояние конвейера, возвращает различия, инженер просматривает, отправляет.
Стоимость интеграции была ниже ожидаемой, потому что движок шаблонов и поисковый фронт уже были независимыми системами. Агентный цикл — это координационный слой над инструментами, которые у нас уже были — не переписывание — вот почему мы смогли выпустить первую версию за дни, а не недели.
Поиск как оркестрация
Поиск больше не просто о извлечении и ранжировании; это проблема оркестрации. Обрабатывая реальные запросы пользователей не только как метрики, но и как активные триггеры для агентного принимающего решения, мы построили систему, которая активно борется со своей энтропией.
В Curify поисковая система больше не просто находит контент. Если контент отсутствует, она создает его. Если логика ошибочна, она переписывает ее. Сторона предложения и сторона архитектуры обе улучшаются на основе одного и того же сигнала — запросов, которые не сработали вчера.
Это модель для следующего поколения поисковых систем: не большие индексы, а более плотные циклы.
Take the next step
Putting what you read into practice.
Связанные статьи
DS & AI Engineering
Фабрика контента на основе ИИ: почему маркетинговым агентствам нужно прекратить покупать инструменты и начать строить конвейеры

От месяцев до минут: Мульти-модальный ИИ-пайплайн для двуязычного образовательного издательства