2026년 최고의 AI 음성 클로닝 도구: ElevenLabs vs F5-TTS vs OpenVoice
이 주제에 대한 대부분의 게시물은 10개 이상의 도구를 순위 목록으로 나열합니다. 이는 유용하지 않습니다. 세 가지 도구가 거의 모든 실제 사용 사례를 포괄하며, 이들 간의 차이는 뚜렷합니다. 이 가이드는 세 가지 도구를 선택하고 각 도구가 실제로 가장 잘하는 것을 명시하며, 음성 클로닝 도구가 전혀 필요 없는 한 가지 공통 사용 사례(비디오를 다른 언어로 더빙하면서 자신의 목소리를 유지하는 경우)를 강조합니다.
이것이 누구를 위한 것인지
내레이션, 오디오북 또는 맞춤형 TTS 기능을 위해 자신의 목소리를 클로닝할 도구를 선택하는 제작자. 음성 클로닝 기능을 SaaS로 출시하는 제품 팀. 오픈 소스와 상업적 제품을 고려하는 현지화 팀. 자신의 목소리로 YouTube 비디오를 다른 언어로 현지화하려는 경우, 음성 클로닝 도구가 필요하지 않은 경우는?로 건너뛰십시오 — 이는 다른 문제이며 다른 도구입니다.
빠른 구매 가이드 - 실제로 중요한 것
네 가지 차원이 중요하며, 나머지는 마케팅 카피입니다.
1. 동의 및 법적 문제 (가장 먼저 중요한 유일한 규칙). 다른 사람의 목소리를 명시적인 서면 동의 없이 복제하는 것은 법적 재앙입니다 - GDPR은 EU에서 목소리를 생체 데이터로 취급합니다; FCC의 2024년 판결은 미국 로보콜에서 이를 불법으로 만들었습니다. Descript와 Resemble과 같은 도구는 복제 전에 동의 확인을 강제합니다. F5-TTS와 같은 도구는 정책을 사용자에게 맡깁니다. 이에 따라 선택하세요.
2. 가격 모델. 문자당 청구 (ElevenLabs, AWS Polly, Azure)는 선형적으로 확장됩니다 - 저용량에는 괜찮지만 대규모에서는 고통스럽습니다. 구독 계획은 지출을 제한합니다. 오픈 소스 자가 호스팅 (F5-TTS, OpenVoice)은 달러를 GPU 비용 + 엔지니어링 시간으로 교환합니다.
3. 음성 충실도 대 샘플 길이. "즉시" 클론은 10-30초의 참조 오디오가 필요하며 70-80%의 충실도를 제공합니다. "전문가" 클론은 30분 이상의 깨끗한 스튜디오 오디오가 필요하며 95% 이상의 충실도에 도달합니다. 사용 사례에 맞는 계층을 선택하세요 - 팟캐스트 소개는 내부 도구보다 더 높은 충실도가 필요합니다.
4. 오디오가 저장되는 위치. 일부 공급업체는 업로드한 목소리를 모델 연구 및 개발에 사용할 수 있는 "영구 라이선스"를 부여합니다. 개인정보 보호 정책을 읽으세요. 목소리 데이터가 귀하의 인프라를 떠날 수 없다면, F5-TTS 또는 OpenVoice를 자가 호스팅하세요.
이 세 가지를 선택한 방법
대부분의 "최고의 음성 복제 도구" 목록은 SEO를 돕기 위해 15개 항목으로 길어집니다. 우리는 동의하지 않습니다. 세 가지 범주가 거의 모든 실제 사용 사례를 포괄합니다 - 상업적 품질, 오픈 소스 자가 호스팅, 경량 오픈 소스 대안. 우리는 이 세 가지와 겹치는 12개의 도구를 제외했습니다 (Murf, Play.ht, Speechify, Lovo, Listnr, TTSMaker 등은 모두 ElevenLabs와 같은 상업적 품질 범주에 속합니다; Fish Audio, Hume, Respeecher는 영화/공감적 틈새를 목표로 합니다). 긴 목록이 필요하다면, 구글 검색으로 찾을 수 있습니다. 결정을 원하신다면 계속 읽어보세요.
비교할 가치가 있는 세 가지 도구
마케팅 카피를 지나, 음성 클로닝 공간은 세 가지 범주로 나뉩니다: 세련된 상업적 리더(ElevenLabs), 오픈 소스 작업 말뚝(F5-TTS), 그리고 F5-TTS가 맞지 않을 때의 가벼운 오픈 소스 대안(OpenVoice). 각 도구는 다른 독자를 소유합니다. 귀하의 제약에 맞는 도구를 선택하십시오.

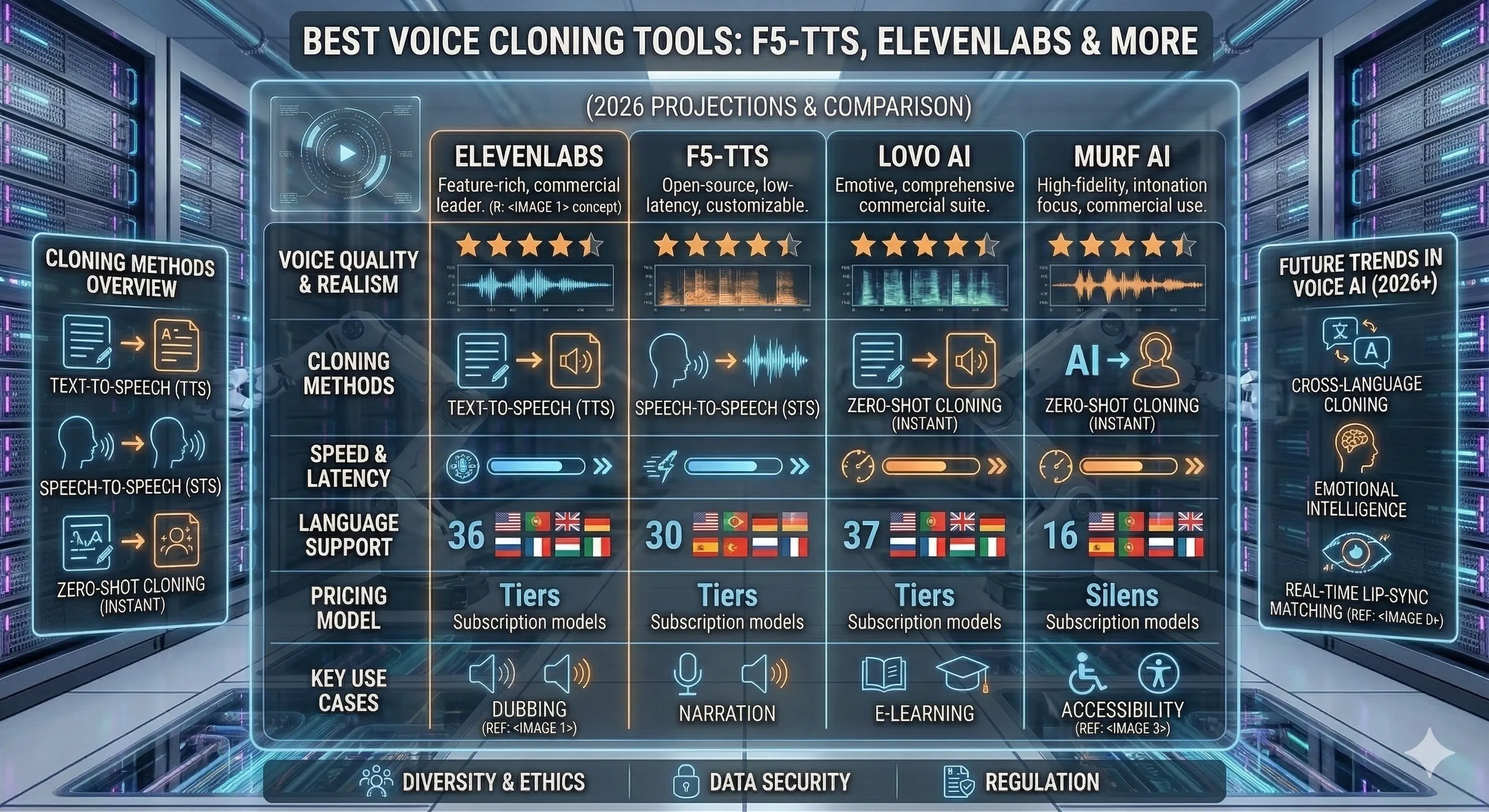
1. ElevenLabs
세련된 음성 클로닝을 위한 상업적 리더
- Best for: 제품, 오디오북, IVR, 미디어 캐릭터 음성을 위한 맞춤형 음성
- Pricing: 문자당 청구 — 무료 티어 제한; 유료 플랜은 약 $5/월부터 시작
- Languages: 성숙한 음성 라이브러리로 30개 이상의 언어 지원
- Notable limitation: 음성 클로닝에 대한 콘텐츠 정책 게이트가 있는 폐쇄형 플랫폼(맞춤형 음성을 위한 동의 확인 필요); 대량 사용 시 문자당 비용이 누적됨
최소한의 엔지니어링 장애물과 가장 높은 기본 충실도가 필요한 음성 클로닝 도구가 필요할 때 ElevenLabs를 선택하십시오. API와 음성 라이브러리는 이 카테고리에서 가장 성숙합니다. 사용자가 자신의 목소리를 클로닝하는 제품 기능을 구축하고 있다면, 이것이 가장 쉬운 경로입니다.
2. F5-TTS
오픈 소스 작업 말뚝, 제로샷 다국어 지원
- Best for: 자체 호스팅 음성 클로닝, 기술 팀, 맞춤형 추론, 배치 생성
- Pricing: 무료(자체 호스팅) — GPU 비용이 바닥
- Languages: 다국어 제로샷 전송; 저자원 언어를 위한 커뮤니티 미세 조정
- Notable limitation: GPU 및 추론 인프라 필요; 긴 클립(>30-45초)에서 프로소디가 드리프트할 수 있으며, 표현적 극단(웃음, 고함)이 약해짐
엔지니어링 리소스가 있고 대규모로 클립당 비용이 0인 경제성을 원하거나 준수를 위해 데이터 거주지/자체 호스팅이 필요한 경우 F5-TTS를 선택하십시오. 이 모델은 Diffusion Transformer와 함께 흐름 일치를 사용하며, 단계와 정밀도를 조정하면 상업적 출력과 경쟁력이 있습니다. 참조 레포: SWivid/F5-TTS; 2025년 논문 OpenReview에서.
3. OpenVoice
경량 오픈 소스 대안, MIT 라이선스
- Best for: 단일 클립 클론, 자원 소모가 적은 환경, 허용적인 라이선스
- Pricing: 무료 (MIT 라이선스, 자체 호스팅)
- Languages: 4개 이상의 언어를 기본 제공; 음성 스타일 전환 가능
- Notable limitation: 상업적 리더들보다 낮은 음성 충실도; 자원 소모가 적은 모델로, F5-TTS가 제공하는 미세 조정 레버가 적음
F5-TTS가 제약에 맞지 않을 때 OpenVoice를 선택하세요 — 더 약한 하드웨어에서 실행되는 작은 모델, 상업적 사용을 위한 더 허용적인 라이선스, 또는 더 간단한 API를 원할 때. 충실도 저하가 있지만 비영웅적 사용 사례(초안, 내부 도구, 접근성 프로토타입)에는 관리 가능함.
나란히 비교
세 가지 도구에서 동일한 네 가지 차원. 각 도구 박스를 읽은 후 이 정보를 사용하여 결정을 내리세요.
| ElevenLabs | F5-TTS | OpenVoice | |
|---|---|---|---|
| Best for | 제품, 오디오북, IVR, 미디어 캐릭터 음성을 위한 맞춤형 음성 | 자체 호스팅 음성 클로닝, 기술 팀, 맞춤형 추론, 배치 생성 | 단일 클립 클론, 자원 소모가 적은 환경, 허용적인 라이선스 |
| Pricing | 문자당 청구 — 무료 티어 제한; 유료 플랜은 약 $5/월부터 시작 | 무료(자체 호스팅) — GPU 비용이 바닥 | 무료 (MIT 라이선스, 자체 호스팅) |
| Languages | 성숙한 음성 라이브러리로 30개 이상의 언어 지원 | 다국어 제로샷 전송; 저자원 언어를 위한 커뮤니티 미세 조정 | 4개 이상의 언어를 기본 제공; 음성 스타일 전환 가능 |
| Limitation | 음성 클로닝에 대한 콘텐츠 정책 게이트가 있는 폐쇄형 플랫폼(맞춤형 음성을 위한 동의 확인 필요); 대량 사용 시 문자당 비용이 누적됨 | GPU 및 추론 인프라 필요; 긴 클립(>30-45초)에서 프로소디가 드리프트할 수 있으며, 표현적 극단(웃음, 고함)이 약해짐 | 상업적 리더들보다 낮은 음성 충실도; 자원 소모가 적은 모델로, F5-TTS가 제공하는 미세 조정 레버가 적음 |
어떤 사용 사례에 어떤 것을 선택할까
- SaaS 기능, 오디오북 또는 IVR을 위한 맞춤 음성 → ElevenLabs. 성숙하고, 세련되며, 엔지니어링 표면이 낮음.
- 대규모 음성 클로닝, 자체 호스팅 → F5-TTS. 클립당 무료, 완전한 제어, GPU가 최소 요구 사항.
- 자원 소모가 적거나 허용적인 라이선스 필요 → OpenVoice. 더 가벼운 모델, MIT.
- 화자의 음성을 유지하면서 비디오를 다른 언어로 현지화 → 세 가지 모두 건너뛰기. 다음 섹션을 읽어보세요.
음성 클로닝 *도구*가 필요하지 않다면?
“최고의 음성 클로닝 도구”에 도착한 대부분의 독자는 실제로 하나의 특정 문제를 해결하려고 합니다: 비디오를 다른 언어로 원래 화자처럼 들리게 만들기. 만약 당신이 그렇다면, 음성 클로닝 도구가 필요하지 않습니다 — 내부적으로 음성 클로닝을 사용하는 더빙 도구가 필요합니다.
Curify 비디오 더빙은 원본 비디오에서 화자의 음성을 클론하고, 오디오를 번역하며, 원본 타이밍에 맞춰 정렬하고, 화자의 정체성을 유지한 채 목표 언어로 더빙 트랙을 제공합니다. 음성 클로닝은 보이지 않으며 — 비디오를 업로드하고, 언어를 선택하고, 더빙을 받으세요. 이 파이프라인은 위에서 다룬 F5-TTS 계보를 기반으로 하며, 정렬, 립싱크 및 자막 생성을 처리하므로 직접 조립할 필요가 없습니다.
이것이 적합한 경우: YouTube 비디오, 강의 모듈, 제품 데모, 웨비나, 튜토리얼을 현지화할 때.
적합하지 않은 경우: TTS API, IVR, 오디오북 내레이션 또는 사용자가 자신의 음성을 클론하는 SaaS 기능을 위한 음성 클로닝 — 그런 경우에는 위의 ElevenLabs 또는 F5-TTS를 사용하세요. 다른 카테고리, 다른 도구.
음성을 클로닝하기 전에 알아야 할 준수 사항
법적 조언이 아닙니다 — 귀하의 관할권에 대한 상담을 받으십시오. 그렇긴 해도, 세 가지 방어 가능한 관행이 어디에서나 나타납니다:
- 동의 및 권리. 음성 소유자로부터 명시적인 서면 동의를 받으십시오. 참조 오디오의 출처를 문서화하십시오. 일부 미국 주에서는 사망 후에도 공개 권리가 지속됩니다; 변호사가 이를 범위 지정할 수 있습니다.
- 공개. 플랫폼이나 관할권에서 요구하는 경우 합성 또는 의미 있게 변경된 음성을 라벨링하십시오. YouTube는 업로드 중 공개 경로를 제공합니다 — 이를 사용하십시오.
- 전화 주의. 미국 FCC의 2024 선언적 판결은 사전 명시적 동의 없이 로보콜에서 AI 생성 음성을 불법으로 만들었습니다. 귀하의 사용 사례가 전화와 관련이 있다면, 이것이 장애물입니다.
자주 묻는 질문
2026년에 AI 음성 복제가 합법인가요?
관할권에 따라 다릅니다. 미국: 음성 복제에 대한 연방법은 없지만, 비동의적 사용에 대해 주의 공적 권리 법이 적용됩니다; FCC의 2024년 판결은 로보콜에서 AI 음성을 불법으로 만듭니다. EU: GDPR은 음성을 생체 데이터로 취급합니다 - 명시적인 동의가 필요하며, 모델 훈련 사용을 공개해야 합니다. 항상 음성 소유자로부터 명시적인 서면 동의를 받으세요, 이를 문서화하고 플랫폼에서 요구하는 경우 합성 콘텐츠에 라벨을 붙이세요 (YouTube, TikTok).
목소리를 복제하려면 얼마나 많은 오디오가 필요하나요?
계층에 따라 다릅니다. 즉시 클론 (ElevenLabs Instant, OpenVoice)은 10-30초의 참조 오디오가 필요하며 70-80%의 충실도를 제공합니다. 전문가 클론 (ElevenLabs Professional, F5-TTS 미세 조정)은 30분 이상의 깨끗한 스튜디오 오디오가 필요하며 95% 이상의 충실도에 도달합니다. 팟캐스트 소개를 위해 자신의 목소리를 복제하는 경우, 즉시 계층이 괜찮습니다. 제품 기능을 출시하는 경우, 전문가로 가세요.
개인 프로젝트를 위해 유명인의 목소리를 복제할 수 있나요?
아니요. 모든 신뢰할 수 있는 플랫폼 (ElevenLabs, Resemble, Respeecher)은 TOS에서 이를 금지합니다. 이는 대부분의 미국 주에서 공적 권리 법을 위반하며 많은 관할권에서 저작권을 위반합니다. 오픈 소스 모델을 자가 호스팅하더라도, 유명인 클론의 출력을 배포하는 것은 법적 조치를 받을 수 있습니다. 하지 마세요.
음성 복제와 텍스트-음성 변환 (TTS)의 차이는 무엇인가요?
TTS는 기존의 목소리를 사용하여 작성된 텍스트를 음성으로 변환합니다 (종종 선별된 스톡 목소리). 음성 복제는 참조 샘플에서 캡처한 특정 사람의 목소리로 음성을 생성합니다. 대부분의 현대 플랫폼 (ElevenLabs, F5-TTS)은 둘 다 수행합니다 - 음성 복제를 기능으로 갖춘 TTS 엔진입니다. "음성 복제 도구"는 일반적으로 "내가 목소리를 복제하는 데 사용하는 TTS 엔진"을 의미합니다.
음성-음성 변환 (STS)란 무엇인가요?
다른 메커니즘: 당신은 자신의 톤, 속도, 감정을 담아 대사를 수행하는 것을 녹음하고, 도구는 당신의 성과를 다른 목표 목소리에 매핑합니다. 더빙에 유용하며, 더빙된 목소리가 원래 배우의 감정 전달을 물려받기를 원할 때 사용됩니다. Respeecher가 이 분야를 전문으로 하며, ElevenLabs와 다른 플랫폼도 기능으로 제공합니다. 이는 단순한 음성 복제와는 다른 문제입니다.
내 목소리로 YouTube 비디오를 더빙하고 싶습니다. 어떤 도구를 사용해야 하나요?
위의 세 가지는 각각 단독으로는 사용할 수 없습니다 - 파이프라인을 구성해야 합니다. 필요할 것은: (1) 원본 오디오 추출, (2) 화자의 목소리 복제, (3) 스크립트 번역, (4) 복제된 목소리로 더빙된 오디오 생성, (5) 원본 비디오 타이밍에 맞추기, (6) 선택적으로 립싱크. Curify Video Dubbing은 모든 여섯 단계를 종합적으로 수행합니다. 음성 복제는 내부적이며, 비디오를 업로드하고 언어를 선택하여 더빙을 받습니다. "음성 복제 도구"와는 다른 범주입니다.
간단한 버전
세 가지 도구, 하나의 결정: ElevenLabs는 제품을 출시하고 싶고 세련됨 + 낮은 엔지니어링 표면을 원할 때; F5-TTS는 GPU가 있고 대규모로 클립당 비용이 0인 경우; OpenVoice는 허용적인 라이센스가 있는 더 가벼운 모델이 필요할 때. 그리고 실제 문제는 자신의 목소리로 비디오를 더빙하는 것이라면, Curify를 사용해 보세요 — 음성 클로닝이 자동으로 이루어지며 위의 세 가지를 배울 필요가 없습니다.
Take the next step
Putting what you read into practice.

