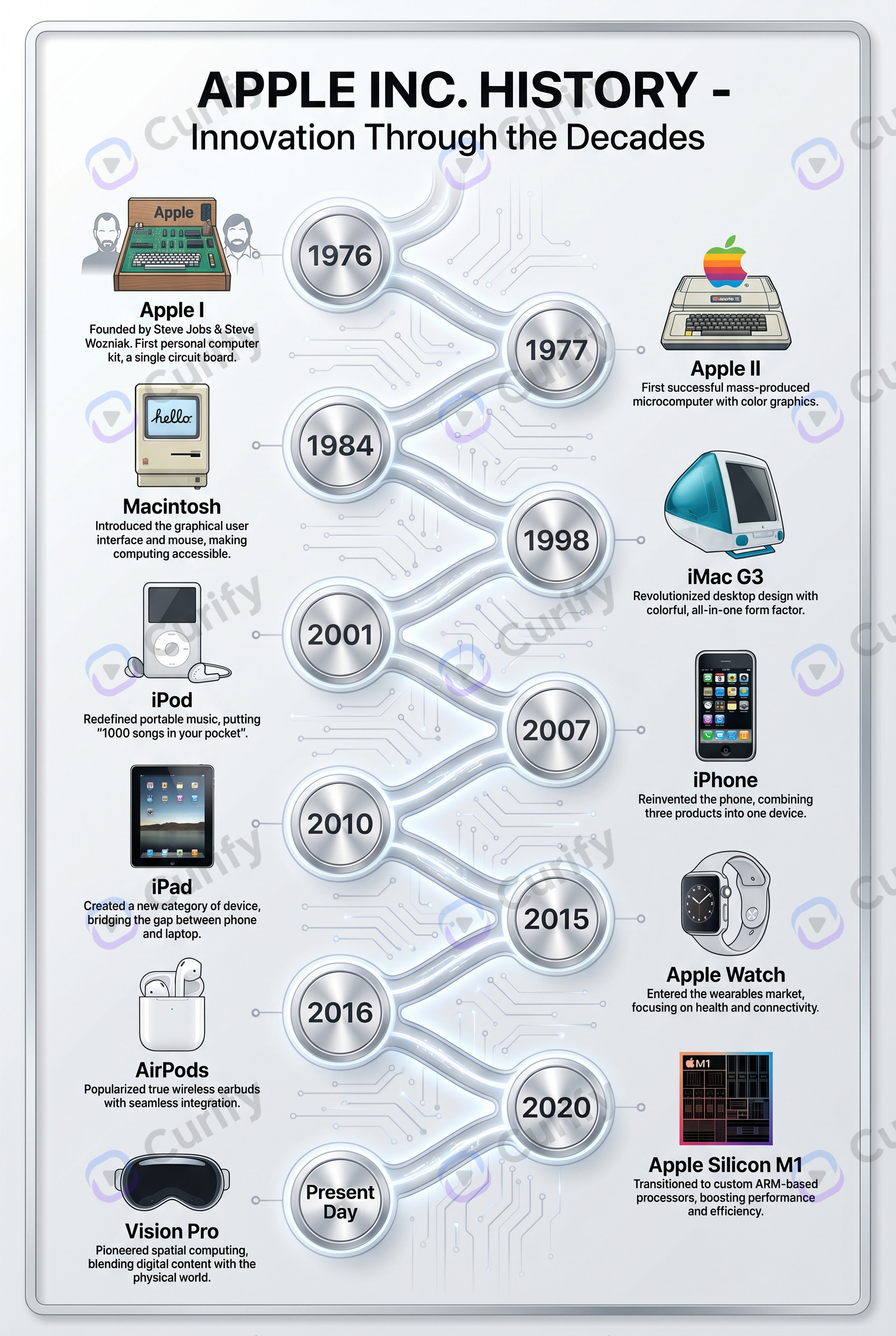
Curify में वास्तविक उपयोगकर्ता प्रश्नों के साथ एक आत्म-सुधार करने वाले मल्टीमोडल सर्च इंजन का निर्माण
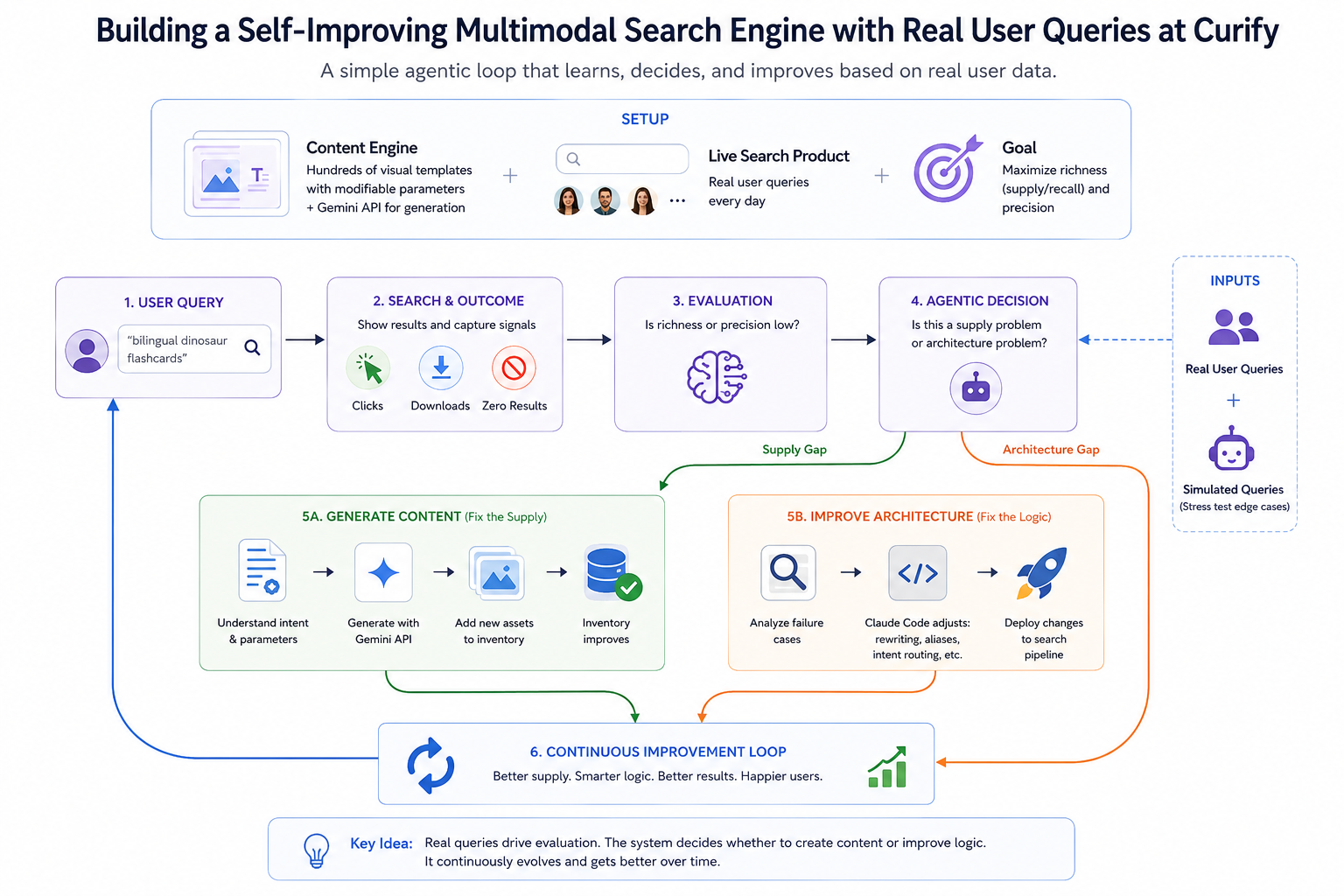
पारंपरिक सर्च इंजन स्थिर अनुक्रमणिका हैं - वे दुनिया के उन्हें भरने का इंतजार करते हैं। एजेंटिक वर्कफ़्लो और "वाइब कोडिंग" के युग में, एक सर्च सिस्टम का निर्माण केवल BM25 या वेक्टर एम्बेडिंग को अनुकूलित करने के बारे में नहीं होना चाहिए; यह एक स्वायत्त लूप बनाने के बारे में होना चाहिए जो सीखता है, निर्णय लेता है, और अपनी खुद की आपूर्ति बनाता है। Curify में, हमने हाल ही में अपने सर्च बार को एक निष्क्रिय पुनर्प्राप्ति उपकरण से एक आत्म-सुधार करने वाले मल्टीमोडल इंजन में बदल दिया। यह पोस्ट यह देखने का अवसर है कि हमने वास्तविक उपयोगकर्ता डेटा द्वारा संचालित एजेंटिक लूप को कैसे इंजीनियर किया।
सेटअप: एक गतिशील आपूर्ति श्रृंखला
इंजन को समझने के लिए, इन्वेंटरी से शुरू करें। Curify खुली वेब को अनुक्रमित नहीं कर रहा है - सेटअप अत्यधिक नियंत्रित और निर्धारक है:
सामग्री इंजन: सैकड़ों संरचित दृश्य टेम्पलेट्स जिनमें संशोधित करने योग्य पैरामीटर हैं, उच्च-निष्ठा छवि उत्पादन के लिए सीधे जेमिनी एपीआई से जुड़े हुए हैं।
संकेत: एक लाइव सर्च उत्पाद जो दैनिक, वास्तविक-विश्व उपयोगकर्ता प्रश्नों को कैप्चर करता है।
अनुकूलन लक्ष्य सीधा है: खोज परिणामों की *समृद्धि* (आपूर्ति / पुनःकाल) और *सटीकता* को अधिकतम करना। लेकिन वजन को मैन्युअल रूप से ट्यून करने के बजाय, हम लाइव उपयोगकर्ता प्रश्नों को एक गतिशील, निरंतर मूल्यांकन सेट में बदल देते हैं। प्रत्येक कम प्रदर्शन करने वाला प्रश्न एक प्रशिक्षण संकेत बन जाता है - न कि ग्रेडिएंट-डिसेंट अर्थ में, बल्कि एजेंटिक-निर्णय अर्थ में। पाइपलाइन यह तर्क करती है कि *क्यों* एक प्रश्न असफल हुआ और सही सुधार की ओर मार्गदर्शन करती है।
मूल्यांकन → तर्क → कार्य लूप
चरण 1: वास्तविक प्रश्नों को कैप्चर करें (और किनारे के मामलों का अनुकरण करें)
Curify पर प्रत्येक खोज प्रश्न को कैप्चर करती है साथ ही तत्काल परिणाम: क्लिक, डाउनलोड, या dreaded zero-result पृष्ठ। यह हमें वास्तविक संकेतों की एक धारा देता है।
हम वास्तविक उपयोगकर्ताओं के हिट करने से पहले किनारे के मामलों का तनाव-परीक्षण करने के लिए *अनुकरणीय* उपयोगकर्ता प्रतिक्रियाएं भी इंजेक्ट करते हैं - एक छोटा सिंथेटिक-ट्रैफिक जनरेटर जो कैटलॉग के कोनों की जांच करता है जैसे एक LLM-चालित एजेंट करेगा। वास्तविक प्रश्न उपयोगकर्ताओं की वास्तविक आवश्यकताओं को उजागर करते हैं; अनुकरणीय प्रश्न उन आवश्यकताओं को उजागर करते हैं जो हम उम्मीद करते हैं। दोनों एक ही मूल्यांकन पाइपलाइन को खिलाते हैं।
चरण 2: प्रत्येक कम प्रदर्शन करने वाले प्रश्न का मूल्यांकन करें
कोई भी प्रश्न जो कम समृद्धि या खराब सटीकता उत्पन्न करता है, एक मूल्यांकन नोड को सक्रिय करता है। मूल्यांकनकर्ता वास्तविक जुड़ाव संकेतों (क्लिक, निवास समय, डाउनलोड) को उन प्रश्नों के लिए जेमिनी-निर्धारित प्रासंगिकता स्कोरिंग के साथ जोड़ता है जिन्होंने परिणाम लौटाए लेकिन जहां जुड़ाव अस्पष्ट है।
मूल्यांकनकर्ता केवल त्रुटि को लॉग नहीं करता। यह एजेंटिक प्रश्न पूछता है: *क्या यह एक आपूर्ति समस्या है, या एक आर्किटेक्चर समस्या?* वह विभाजन लूप का दिल है और यह निर्धारित करता है कि अगली कार्रवाई के लिए कौन सा रास्ता सक्रिय होता है।
चरण 3: निर्णय विभाजन - सामग्री उत्पन्न करें (आपूर्ति को ठीक करें)
यदि मूल्यांकन यह निर्धारित करता है कि उपयोगकर्ता का इरादा मान्य है (जैसे, "द्विभाषी डायनासोर फ्लैशकार्ड") लेकिन डेटाबेस वास्तव में खाली है, तो सिस्टम एक स्वायत्त निर्माता के रूप में कार्य करता है।
क्रिया: यह प्रश्न पैरामीटर को टेम्पलेट इंजन की ओर मार्गदर्शित करता है, जेमिनी एपीआई को सक्रिय करता है, और गायब दृश्य संपत्तियों को बैच-जनरेट करता है - वही टेम्पलेट-चालित पाइपलाइन जो नियमित सामग्री ड्रॉप को शक्ति देती है, अब एक असफल खोज द्वारा मांग पर सक्रिय की जाती है।
जब तक अगला उपयोगकर्ता (या अनुकरणीय एजेंट) वही खोज करता है, इन्वेंटरी ने खुद को ठीक कर लिया है। सर्च इंजन ने वास्तव में जो गायब था उसे बनाया।
चरण 4: निर्णय विभाजन - आर्किटेक्चर में सुधार करें (तर्क को ठीक करें)
यदि सामग्री मौजूद है ("टी-रेक्स शैक्षिक पोस्टर") लेकिन उपयोगकर्ता का प्रश्न ("जुरासिक शिक्षण सामग्री") इसे उजागर करने में असफल रहा, तो इंजन एक आर्किटेक्चरल गैप को चिह्नित करता है।
क्रिया: यहीं पर वाइब कोडिंग अपनी कीमत वसूल करती है। एक डेवलपर द्वारा मैन्युअल रूप से regex नियम लिखने के बजाय, हम असफल मूल्यांकन मामलों को क्लॉड कोड में फीड करते हैं और इसे प्रेरित करते हैं:
- प्रश्न पुनर्लेखन नियम अपडेट करें
- नए उपनाम विस्तार उत्पन्न करें
- LLM इरादा-मार्गदर्शन प्रॉम्प्ट को परिष्कृत करें
सर्च पाइपलाइन में आर्किटेक्चरल ट्विक्स मिनटों में शिप होते हैं, पूरी तरह से वास्तविक उपयोगकर्ता घर्षण बिंदुओं पर आधारित। इंजीनियर डिफ्स की समीक्षा करते हुए लूप में रहता है, लेकिन एजेंट वास्तविक मामलों के खिलाफ ड्राफ्टिंग करता है बजाय इसके कि काल्पनिक प्रश्नों के बारे में अनुमान लगाए।
यह क्या प्रतिस्थापित करता है
तीन पैटर्न जो लूप को विस्थापित करते हैं:
मैनुअल सामग्री बैकफिल: पारंपरिक सर्च टीमें "कम पुनःकाल वाले प्रश्नों" का एक बैकलॉग बनाए रखती हैं और गैप को भरने के लिए सामग्री कमीशन भेजती हैं। देरी सप्ताहों की होती है; कई कभी नहीं भरे जाते। एजेंटिक लूप घंटों में गैप को बंद कर देता है।
हैंड-लिखित पुनर्लेखन नियम: सर्च इंजीनियर्स प्रति-किवर्ड उपनाम लिखना या स्टेमिंग शब्दकोश बनाए रखना। आवश्यक लेकिन धीमा, और नियम नए प्रश्न पैटर्न के उभरने के साथ भटकते हैं। वाइब-कोडेड पुनर्लेखन केस वॉल्यूम के साथ रैखिक रूप से स्केल करते हैं, इंजीनियर घंटों के साथ नहीं।
स्थिर मूल्यांकन सेट: प्रासंगिकता बेंचमार्क जो एक बार लिखे जाते हैं और जमे रहते हैं। वास्तविक उपयोगकर्ता प्रश्न हर सप्ताह बदलते हैं - एक स्थिर मूल्यांकन सेट पिछले तिमाही की वास्तविकता को माप रहा है। लाइव प्रश्नों को मूल्यांकन सेट के रूप में मानते हुए, सिस्टम वास्तव में इस सप्ताह उपयोगकर्ताओं द्वारा खोजे गए प्रश्नों के लिए अनुकूलित करता है।
Tools & Resources
Learn about the best tools available...
कैसे स्टैक एक साथ काम करता है
चार घटक, एजेंट परत द्वारा चिपके हुए:
सर्च फ्रंट-एंड प्रश्नों + जुड़ाव संकेतों को कैप्चर करता है और उन्हें लगभग वास्तविक समय में मूल्यांकनकर्ता को भेजता है।
टेम्पलेट इंजन Curify का नैनो बनाना पुस्तकालय है - सैकड़ों पैरामीटरयुक्त दृश्य टेम्पलेट्स जो आपूर्ति-पक्ष विभाजन को गायब सामग्री उत्पन्न करने के लिए कॉल करते हैं। वही इंजन जो मैन्युअल सामग्री ड्रॉप को शक्ति देता है; लूप एक और कॉलर बन जाता है।
जेमिनी एपीआई छवि उत्पादन (आपूर्ति पक्ष) और प्रासंगिकता स्कोरिंग (मूल्यांकन पक्ष) दोनों को संभालता है। एकल मॉडल परिवार, दो भूमिकाएं।
क्लॉड कोड आर्किटेक्चर-पक्ष के अपडेट को संभालता है - पुनर्लेखन नियम, उपनाम विस्तार, इरादा-मार्गदर्शन प्रॉम्प्ट। एजेंट को असफल मामलों के बारे में संदर्भ मिलता है और मौजूदा पाइपलाइन स्थिति, एक डिफ़ लौटाता है, इंजीनियर समीक्षा करता है, शिप।
एकीकरण लागत अपेक्षा से कम थी क्योंकि टेम्पलेट इंजन और सर्च फ्रंट-एंड पहले से ही स्वतंत्र सिस्टम थे। एजेंटिक लूप उन उपकरणों के ऊपर एक समन्वय परत है जो हमारे पास पहले से थे - एक पुनर्लेखन नहीं - यही कारण है कि हम पहले संस्करण को दिनों में शिप कर सके न कि हफ्तों में।
सर्च को ऑर्केस्ट्रेशन के रूप में
सर्च अब केवल पुनर्प्राप्ति और रैंकिंग के बारे में नहीं है; यह एक ऑर्केस्ट्रेशन समस्या है। वास्तविक उपयोगकर्ता प्रश्नों को केवल मेट्रिक्स के रूप में नहीं बल्कि एक एजेंटिक निर्णय-निर्माता के लिए सक्रिय ट्रिगर्स के रूप में मानते हुए, हमने एक ऐसा सिस्टम बनाया है जो सक्रिय रूप से अपनी खुद की एंट्रॉपी से लड़ता है।
Curify में, सर्च इंजन अब केवल सामग्री नहीं खोजता। यदि सामग्री गायब है, तो यह इसे बनाता है। यदि तर्क दोषपूर्ण है, तो यह इसे फिर से लिखता है। आपूर्ति पक्ष और आर्किटेक्चर पक्ष दोनों एक ही संकेत से सुधार करते हैं - वे प्रश्न जो कल काम नहीं करते थे।
यह अगली पीढ़ी के सर्च सिस्टम का मॉडल है: न कि बड़े अनुक्रमणिका, बल्कि तंग लूप।
Take the next step
Putting what you read into practice.
संबंधित लेख
DS & AI Engineering
एआई कंटेंट फैक्टरी: मार्केटिंग एजेंसियों को उपकरण खरीदना बंद करना चाहिए और पाइपलाइनों का निर्माण शुरू करना चाहिए

महीनों से मिनटों तक: द्विभाषी शैक्षिक प्रकाशन के लिए एक मल्टी-मोडल एआई पाइपलाइन