La IA está remodelando el flujo de trabajo de datos: de asistente a agente
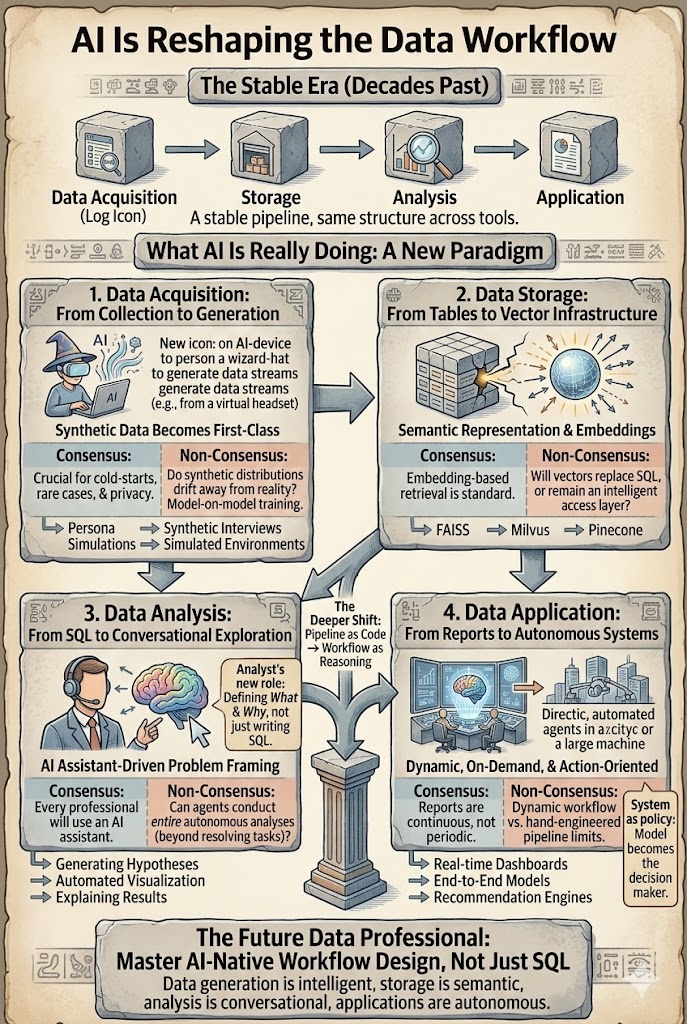
El flujo de trabajo de datos ha sido notablemente estable durante una década. Ya seas un científico de datos, analista o ingeniero de recomendaciones, el pipeline ha sido aproximadamente el mismo: adquisición → almacenamiento → análisis → aplicación. La IA no solo está acelerando este flujo de trabajo, sino que está comenzando a remodelar cada capa del mismo. La verdadera pregunta ya no es si la IA cambiará el trabajo de datos. Es qué partes están claramente cambiando y qué suposiciones resultarán ser incorrectas.
Las Cuatro Capas del Flujo de Trabajo de Datos
Diferentes herramientas, diferentes industrias, pero fundamentalmente la misma estructura de cuatro pasos: generar o recopilar datos, almacenarlos, analizarlos, aplicar la información. Este pipeline ha impulsado diez años de búsqueda, anuncios y sistemas de recomendación con relativamente poco cambio en su forma. Lo que ha cambiado es la profundidad a la que cada capa está siendo remodelada por grandes modelos y agentes. Las secciones a continuación recorren cada capa y separan el consenso (lo que está claramente cambiando) de la no-consenso (lo que aún está en debate).
Cómo Está Cambiando Cada Capa
1. Adquisición de Datos — Los Datos Sintéticos se Convierten en una Fuente de Primera Clase
Tradicionalmente, los datos útiles provenían del mundo real: registros, transacciones, sensores, encuestas. Esa suposición está comenzando a romperse. Cada vez más datos se generan en lugar de ser recopilados, a través de simulaciones de personas, modelado de comportamiento, entrevistas sintéticas, generación de datos de pruebas A/B y entornos simulados utilizados para el entrenamiento y evaluación del aprendizaje por refuerzo.
Consenso: Los datos sintéticos complementarán cada vez más los datos del mundo real, especialmente en problemas de inicio en frío, escenarios raros y entornos con restricciones de privacidad.
No-consenso: ¿Qué sucede cuando los modelos entrenan cada vez más con datos producidos por otros modelos? ¿Las distribuciones sintéticas se alejarán lentamente de la realidad y formarán bucles de retroalimentación?
La adquisición de datos está cambiando de *colección* a *generación + calibración*.
2. Almacenamiento de Datos — De Tablas a Infraestructura Vectorial
Los sistemas de datos tradicionales se construyeron en torno al almacenamiento estructurado: bases de datos relacionales, almacenes y almacenes de columnas. La IA introduce una nueva capa: representaciones vectoriales. Texto, imágenes, videos, trayectorias de comportamiento del usuario y fragmentos de conocimiento se almacenan cada vez más como embeddings que impulsan la búsqueda semántica, la generación aumentada por recuperación y el razonamiento multimodal. Bases de datos vectoriales como FAISS, Milvus y Pinecone se están convirtiendo en infraestructura central.
Consenso: La recuperación basada en embeddings es ahora un patrón de diseño estándar. RAG es la arquitectura predeterminada para fundamentar LLMs en datos propietarios.
No-consenso: ¿Eventualmente reemplazarán los vectores las capas de almacenamiento tradicionales? ¿O seguirán siendo una capa de indexación sobre datos en bruto? ¿Podemos reconstruir datos originales a partir de embeddings lo suficientemente bien como para que los vectores se conviertan en almacenamiento primario?
Por ahora, los embeddings funcionan menos como almacenamiento y más como una capa de acceso inteligente. Pero esa capa ya ha remodelado cómo se accede a los datos.
3. Análisis de Datos — De SQL a Exploración Conversacional
La capa de análisis está cambiando más rápido. El flujo de trabajo tradicional se veía así:
definición del problema → SQL → ingeniería de características → modelado → interpretación
Hoy, los sistemas de IA pueden asistir en casi cada paso: los LLMs generan automáticamente SQL, proponen hipótesis, construyen visualizaciones, construyen modelos base y explican resultados. El papel del analista cambia de *Escritor de Consultas* a *Enmarcador y Validador de Problemas*.
Consenso: Cada profesional de datos pronto trabajará con un asistente de IA. Los copilotos y el análisis basado en chat se están convirtiendo en requisitos básicos.
No-consenso: ¿Realmente los agentes llevarán a cabo análisis completos de principio a fin? En el soporte al cliente, los agentes ya pueden manejar el 80% de los tickets. El análisis de datos es más difícil: las preguntas mismas son a menudo ambiguas y los objetivos cambian a mitad de la investigación. La automatización acelerará la ejecución, pero es probable que los humanos sigan siendo responsables de enmarcar el problema.
4. Aplicación de Datos — De Informes a Sistemas Autónomos
La etapa final — aplicar información — está evolucionando en dos frentes.
Informes. La IA ya transforma la elaboración de informes: resúmenes automáticos, gráficos, paneles y presentaciones en texto, imagen y video. El cambio más profundo es que los informes ya no necesitan ser periódicos. Pueden generarse de forma continua y bajo demanda. La verdadera ganancia de productividad no es "escribir más rápido", sino "informes que existen cuando se hace la pregunta."
Sistemas autónomos. La recomendación, búsqueda, publicidad y conducción autónoma se están alejando de pipelines modulares diseñados a mano hacia modelos de extremo a extremo donde el modelo mismo se convierte en la política de decisión. El cambio es de *consumidor de características* a *generador de estrategias*.
Asistente vs Agente — Consenso y No-Consenso
Un consenso emergente: los asistentes y agentes coexistirán a largo plazo. Pero el equilibrio difiere drásticamente entre dominios.
| Dominio | Participación del asistente | Participación del agente |
|---|---|---|
| Soporte al cliente | 20% | 80% |
| Análisis de datos | 70% | 30% (incierto) |
| Optimización de políticas de recomendación | 50% | 50% |
| Conducción autónoma | 10% | 90% |
La incertidumbre clave es el análisis de datos. En dominios donde la definición del problema es la parte más difícil, los agentes tienen problemas para cerrar el ciclo. El resultado más probable: el análisis sigue siendo pesado en asistentes, pero la ejecución se vuelve altamente automatizada. Los humanos enmarcan; los agentes exploran.
El cambio más profundo no es un SQL más rápido o mejores paneles. Es quién controla el flujo de trabajo. Estamos pasando de *Pipeline como Código* a *Flujo de Trabajo como Razonamiento* — de ejecutar pasos predefinidos a sistemas que planifican acciones, exploran hipótesis e iteran.
Tools & Resources
Learn about the best tools available...
Dónde Encaja Curify en Este Cambio
Curify se construye en torno al patrón de *Flujo de Trabajo como Razonamiento*. Tres ejemplos concretos en la plataforma hoy:
- Generación de contenido como flujo de trabajo, no como un solo intento. La biblioteca /nano-template tiene 172 plantillas parametrizadas que encadenan prompt → generación de imagen → etiquetado de variantes → sincronización de CDN — un flujo de generación, no un prompt único.
- Acceso respaldado por embeddings en la capa de galería. El corpus de /nano-banana-pro-prompts de más de 4,000 prompts es buscable por etiqueta, tema y similitud semántica — la capa vectorial es el camino de acceso, el JSON en bruto es la fuente de verdad.
- Transcripción de audio + video como entrada upstream. /tools/video-transcript-generator produce transcripciones etiquetadas por hablante que fluyen hacia /tools/video-dubbing y /tools/translate-subtitles — un flujo de trabajo donde una entrada impulsa tres salidas localizadas.
La Verdadera Pregunta para los Profesionales de Datos
El flujo de trabajo de datos tradicional no está desapareciendo. Pero está evolucionando: la generación de datos se vuelve más inteligente, el almacenamiento se vuelve más semántico, el análisis se vuelve más conversacional, las aplicaciones se vuelven más autónomas.
Una visión no-consensuada más radical: los futuros sistemas de datos pueden dividirse en dos — sistemas de análisis interpretables por humanos (para entender el mundo) y sistemas de optimización de caja negra (para optimizar resultados). Cuando los dos se separen, los profesionales de datos no desaparecen; se convierten en *intérpretes de estrategias* en lugar de operadores de datos.
La verdadera pregunta para cualquier profesional de datos hoy ya no es "¿puedes escribir SQL?" Es: ¿puedes diseñar flujos de trabajo nativos de IA?
Take the next step
Putting what you read into practice.
Artículos Relacionados
DS & AI Engineering
De Probabilístico a Determinista: Verdades Difíciles Sobre la Ingeniería de IA en Producción
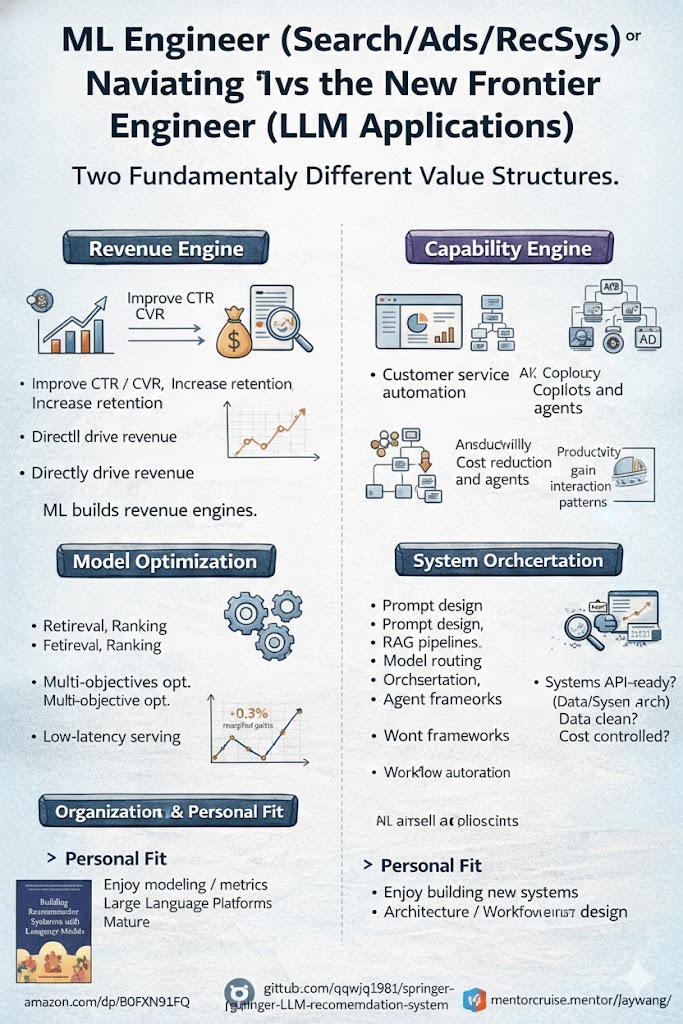
¿Ingeniero de ML o Ingeniero de IA? Dos Trayectorias Profesionales, Dos Estructuras de Valor