Aufbau einer selbstverbessernden multimodalen Suchmaschine mit echten Benutzeranfragen bei Curify
Traditionelle Suchmaschinen sind statische Indizes – sie warten darauf, dass die Welt sie füllt. In der Ära von agentischen Workflows und "Vibe-Coding" sollte der Aufbau eines Suchsystems nicht nur darum gehen, BM25 oder Vektor-Embeddings zu optimieren; es sollte darum gehen, einen autonomen Zyklus zu schaffen, der lernt, entscheidet und seinen eigenen Vorrat aufbaut. Bei Curify haben wir kürzlich unsere Suchleiste von einem passiven Abrufwerkzeug in eine selbstverbessernde multimodale Engine verwandelt. Dieser Beitrag gibt einen Einblick, wie wir einen agentischen Zyklus entwickelt haben, der von echten Benutzerdaten gesteuert wird.
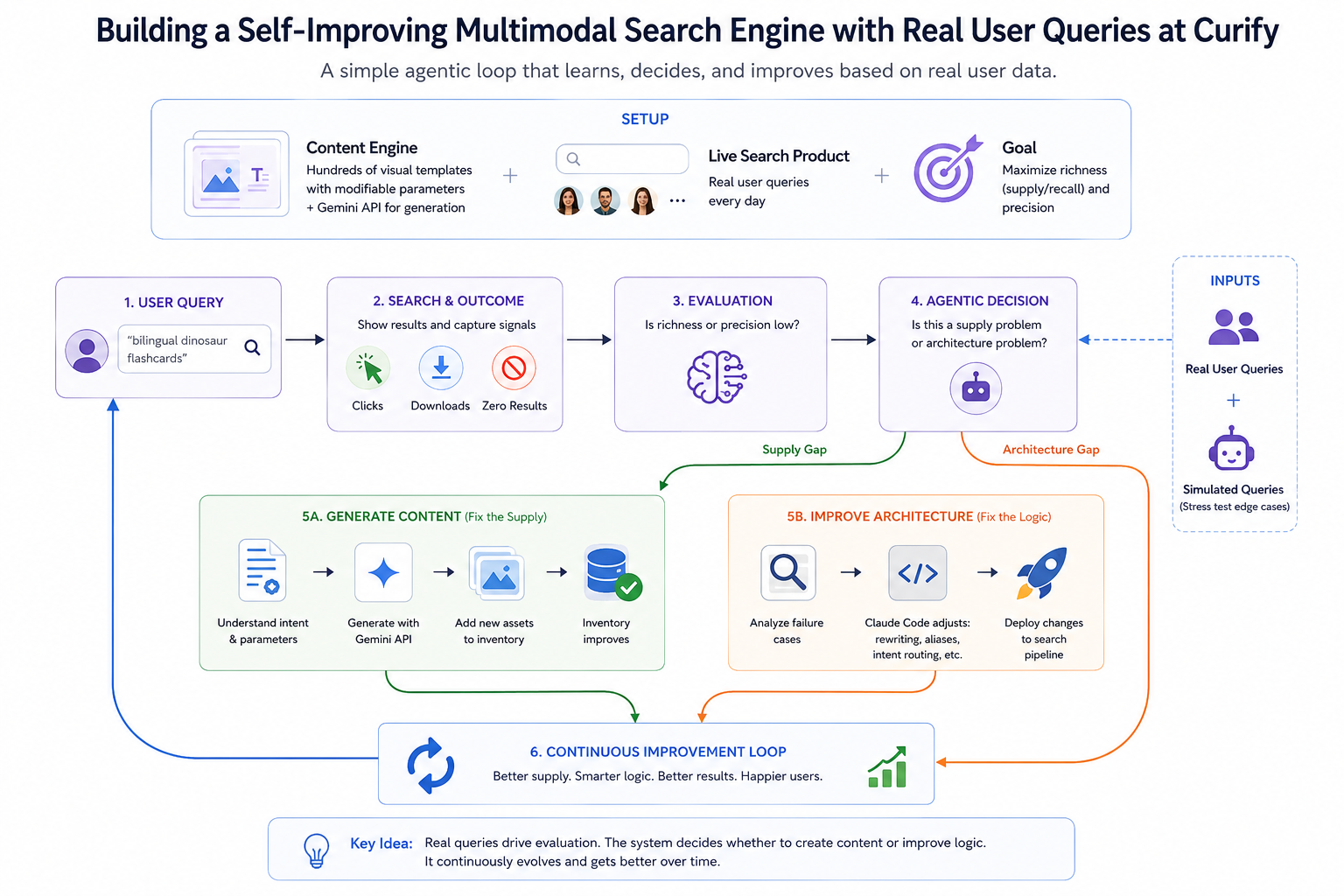
Die Einrichtung: Eine dynamische Lieferkette
Um die Engine zu verstehen, beginnen Sie mit dem Inventar. Curify indiziert nicht das offene Web – die Einrichtung ist hochgradig kontrolliert und deterministisch:
Die Inhalts-Engine: Hunderte von strukturierten visuellen Vorlagen mit modifizierbaren Parametern, die direkt mit der Gemini-API für hochpräzise Bildgenerierung verbunden sind.
Das Signal: Ein Live-Suchprodukt, das täglich echte Benutzeranfragen erfasst.
Das Optimierungsziel ist einfach: die *Reichhaltigkeit* der Suchergebnisse (Angebot / Abruf) und die *Präzision* zu maximieren. Aber anstatt Gewichte manuell anzupassen, verwandeln wir die Live-Benutzeranfragen in ein dynamisches, kontinuierliches Bewertungsset. Jede unterdurchschnittliche Anfrage wird zu einem Trainingssignal – nicht im Sinne des Gradientenabstiegs, sondern im Sinne der agentischen Entscheidung. Die Pipeline überlegt, *warum* eine Anfrage fehlgeschlagen ist und leitet zur richtigen Lösung.
Der Zyklus Bewerten → Überlegen → Handeln
Schritt 1: Echte Anfragen erfassen (und Randfälle simulieren)
Jede Suche bei Curify erfasst die Anfrage sowie das unmittelbare Ergebnis: Klicks, Downloads oder die gefürchtete Null-Ergebnis-Seite. Das gibt uns einen Strom von echtem Signal.
Wir injizieren auch *simulierte* Benutzerantworten, um Randfälle zu testen, bevor echte Benutzer darauf stoßen – ein kleiner synthetischer Verkehrsgenerator, der die Ecken des Katalogs so erkundet, wie es ein von LLM gesteuertes Agent tun würde. Echte Anfragen zeigen, was Benutzer tatsächlich benötigen; simulierte Anfragen zeigen, was sie *benötigen werden*, basierend auf Mustern, die wir erwarten. Beide speisen dasselbe Bewertungs-Pipeline.
Schritt 2: Jede unterdurchschnittliche Anfrage bewerten
Jede Anfrage, die eine niedrige Reichhaltigkeit oder schlechte Präzision ergibt, löst einen Bewertungs-Knoten aus. Der Bewerter kombiniert echte Engagement-Signale (Klicks, Verweildauer, Downloads) mit von Gemini bewerteten Relevanzbewertungen für Anfragen, die Ergebnisse zurückgegeben haben, bei denen das Engagement jedoch unklar ist.
Der Bewerter protokolliert nicht nur den Fehler. Er stellt die agentische Frage: *Ist dies ein Versorgungsproblem oder ein Architekturproblem?* Diese Gabelung ist das Herz des Zyklus und bestimmt, welcher der beiden Aktionspfade als nächstes aktiviert wird.
Schritt 3: Entscheidungs-Gabelung – Inhalte generieren (Versorgung beheben)
Wenn die Bewertung ergibt, dass die Absicht des Benutzers gültig ist (z. B. "bilinguale Dinosaurier-Flashkarten"), aber die Datenbank tatsächlich leer ist, handelt das System als autonomer Creator.
Aktion: Es leitet die Abfrageparameter an die Vorlagen-Engine weiter, löst die Gemini-API aus und generiert die fehlenden visuellen Assets in großen Mengen – dieselbe vorlagenbasierte Pipeline, die reguläre Inhaltsdrops antreibt, jetzt auf Abruf durch eine fehlgeschlagene Suche aktiviert.
Bis der nächste Benutzer (oder simulierte Agent) die gleiche Suche durchführt, hat sich das Inventar selbst geheilt. Die Suchmaschine hat buchstäblich das gebaut, was fehlte.
Schritt 4: Entscheidungs-Gabelung – Architektur verbessern (Logik beheben)
Wenn die Inhalte existieren ("T-Rex Bildungsplakate"), aber die Anfrage des Benutzers ("jurassische Lernmaterialien") nicht dazu geführt hat, sie anzuzeigen, kennzeichnet die Engine eine architektonische Lücke.
Aktion: Hier verdient das Vibe-Coding seinen Platz. Anstatt dass ein Entwickler manuell Regex-Regeln schreibt, füttern wir die fehlgeschlagenen Bewertungsfälle an Claude Code und fordern ihn auf:
- Abfrage-Umschreiberegeln zu aktualisieren
- neue Alias-Erweiterungen zu generieren
- den LLM-Intent-Routing-Prompt zu verfeinern
Architektonische Anpassungen an der Suchpipeline werden in Minuten versendet, die vollständig auf echten Benutzerfriktionen basieren. Der Ingenieur bleibt im Zyklus, um Diffs zu überprüfen, aber der Agent erstellt die Entwürfe anhand realer Fälle, anstatt über hypothetische Anfragen zu spekulieren.
Was dies ersetzt
Drei Muster, die der Zyklus verdrängt:
Manuelle Inhaltsauffüllung: Traditionelle Suchteams führen ein Backlog von "Anfragen mit niedriger Rückrufquote" und beauftragen Inhaltskommissionen, um die Lücken zu schließen. Die Verzögerung beträgt Wochen; viele werden nie gefüllt. Der agentische Zyklus schließt die Lücke in Stunden.
Handgeschriebene Umschreiberegeln: Suchingenieure, die Aliasnamen pro Schlüsselwort schreiben oder Stemming-Wörterbücher pflegen. Notwendig, aber langsam, und die Regeln driftet, wenn neue Anfrage-Muster auftauchen. Vibe-codierte Umschreibungen skalieren linear mit dem Fallvolumen, nicht mit Ingenieurstunden.
Statische Bewertungssets: Relevanzbenchmarks, die einmal verfasst und eingefroren werden. Echte Benutzeranfragen ändern sich jede Woche – ein statisches Bewertungsset misst die Realität des letzten Quartals. Die Behandlung von Live-Anfragen als Bewertungsset bedeutet, dass das System für das optimiert, wonach Benutzer *diese Woche* tatsächlich suchen.
Tools & Resources
Learn about the best tools available...
Wie der Stack zusammengefügt wird
Vier Komponenten, verbunden durch die Agentenschicht:
Such-Frontend erfasst Anfragen + Engagement-Signale und sendet sie in nahezu Echtzeit an den Bewerter.
Vorlagen-Engine ist die Nano Banana-Bibliothek von Curify – Hunderte von parametrisierten visuellen Vorlagen, die der versorgungsseitige Zweig aufruft, um fehlende Inhalte zu generieren. Dieselbe Engine, die manuelle Inhaltsdrops antreibt; der Zyklus wird zu einem weiteren Aufrufer.
Gemini-API verarbeitet sowohl die Bildgenerierung (Versorgungsseite) als auch die Relevanzbewertung (Bewertungsseite). Eine Modellfamilie, zwei Rollen.
Claude Code kümmert sich um die architekturseitigen Updates – Umschreiberegeln, Alias-Erweiterungen, Intent-Routing-Prompts. Der Agent erhält Kontext zu den fehlgeschlagenen Fällen sowie den aktuellen Pipeline-Zustand, gibt ein Diff zurück, Ingenieur überprüft, versendet.
Die Integrationskosten waren niedriger als erwartet, da die Vorlagen-Engine und das Such-Frontend bereits eigenständige Systeme waren. Der agentische Zyklus ist eine Koordinationsschicht über Werkzeugen, die wir bereits hatten – kein Rewrite – weshalb wir die erste Version in Tagen und nicht in Wochen versenden konnten.
Suche als Orchestrierung
Suche dreht sich nicht mehr nur um Abruf und Ranking; es ist ein Orchestrierungsproblem. Indem wir echte Benutzeranfragen nicht nur als Metriken, sondern als aktive Auslöser für einen agentischen Entscheidungsträger behandeln, haben wir ein System aufgebaut, das aktiv gegen seine eigene Entropie kämpft.
Bei Curify findet die Suchmaschine nicht nur Inhalte mehr. Wenn der Inhalt fehlt, erstellt sie ihn. Wenn die Logik fehlerhaft ist, schreibt sie sie um. Die Versorgungsseite und die Architekturseite verbessern sich beide aus demselben Signal – den Anfragen, die gestern nicht funktioniert haben.
Das ist das Modell für die nächste Generation von Suchsystemen: nicht größere Indizes, sondern engere Schleifen.
Take the next step
Putting what you read into practice.
Verwandte Artikel
DS & AI Engineering
Die KI-Inhaltsfabrik: Warum Marketingagenturen aufhören müssen, Werkzeuge zu kaufen, und anfangen sollten, Pipelines zu bauen

Von Monaten zu Minuten: Eine Multi-Modal AI-Pipeline für zweisprachige Bildungsinhalte